Description
Kubernetes Version - 1.25
Couchbase Server - 7.2.5 → 7.6.1
Operator -2.6.4-119
UpgradeProcess: DeltaRecovery
Cluster Setup
- Each node is an m5.4xlarge instance. (16 vCPUs and 64GB RAM)
- 6 Data Service, 4 Index Service & Query Service Nodes.
- 10 Buckets (with 1 replica), Full Eviction and Auto-failover set to 5s.
- ~2TiB data loaded onto the cluster before the beginning of the upgrade.
- 50 Primary Indexes with 1 Replica each. (Total 100 Indexes)
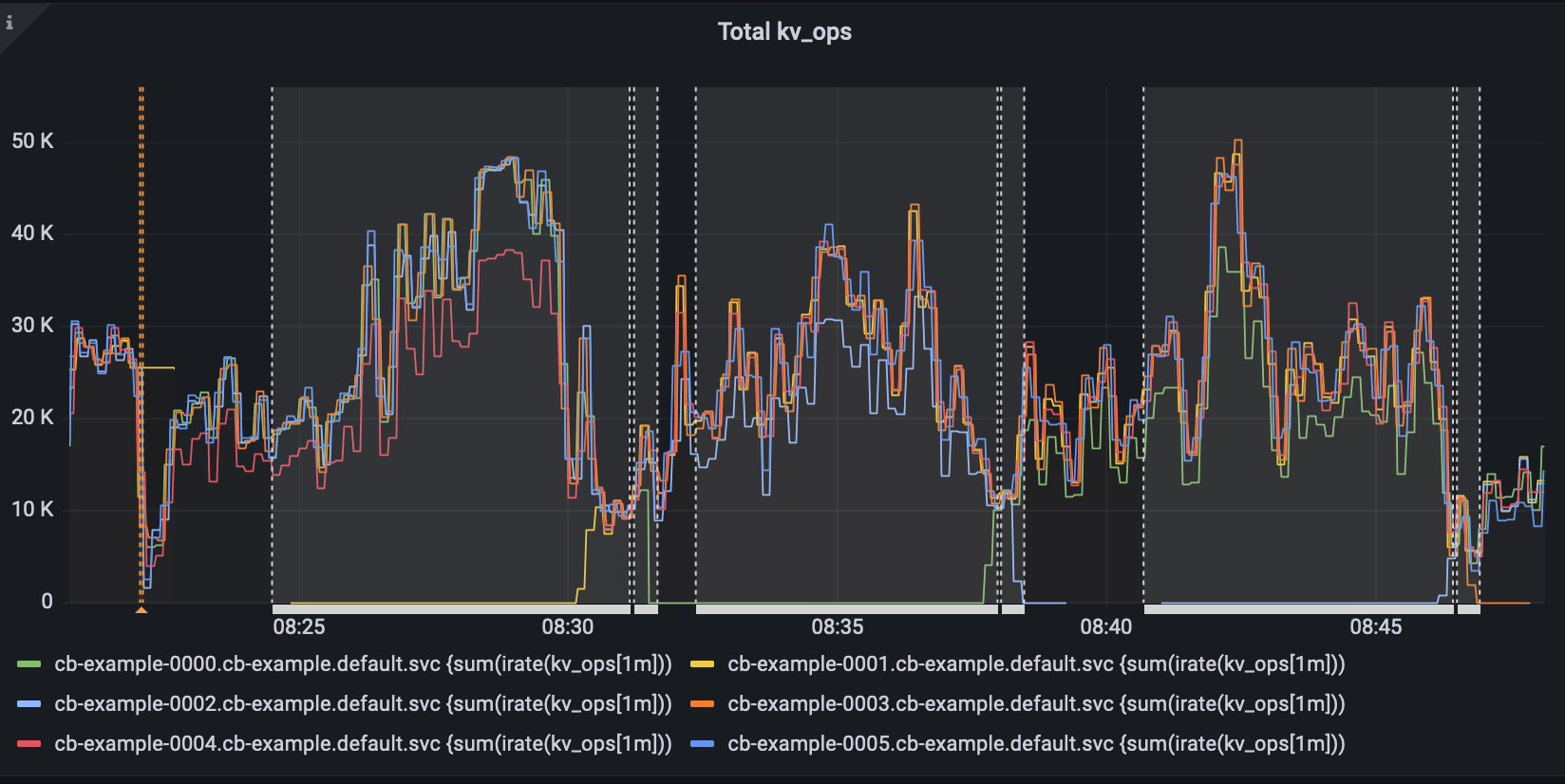
Experiment Performed:-
- Restarted node hosting pod 0001 (Data Node) during upgrade
- Restarted node hosting pod 0009 (Index+Query) during upgrade
observation:- - pod 0001 (data service) auto-failover after node restarted, created new pod 0001, added back to the cluster and completed delta recovery upgrade with delta recovery.
- pod 0009 (index_query) auto-failover twice in total.
- Cluster saw multiple rebalance failures.
- After the second failover of, created pod 0009 which was added back to cluster and completed the upgrade with full rebalance.
- After the first failover of 0009, the cluster tried to failover 0006 multiple times.
Analysis:-
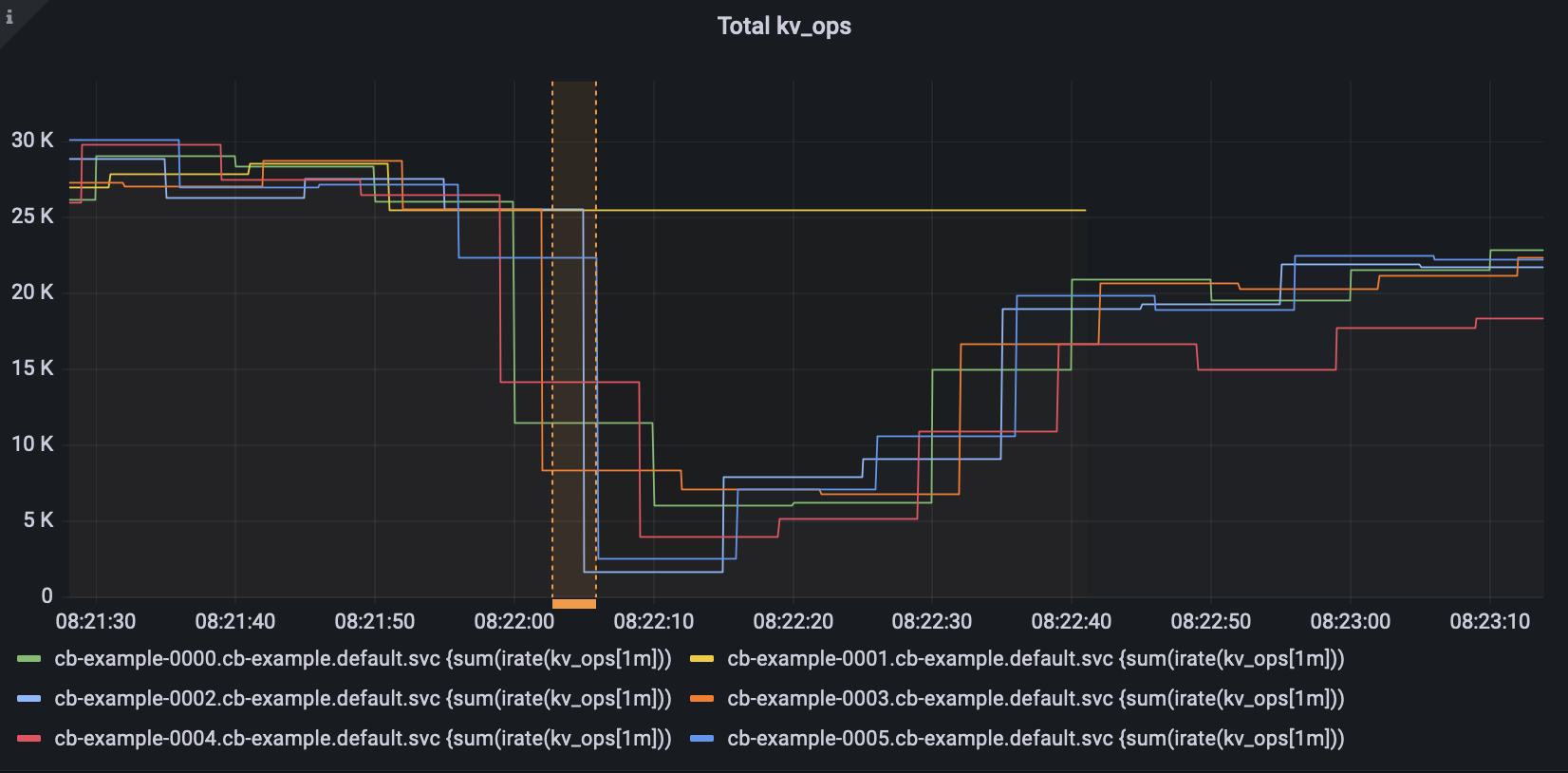
rebalance of pod 0008 was running to upgrade before 0009 got failed.
rebalance of 0008 started at 2024-06-03T09:13:27.991Z
rebalance failed at 2024-06-03T09:14:34.281Z
2024-06-03T09:13:27.991Z, ns_orchestrator:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Starting rebalance, KeepNodes = ['ns_1@cb-example-0000.cb-example.default.svc', 'ns_1@cb-example-0001.cb-example.default.svc', 'ns_1@cb-example-0002.cb-example.default.svc', 'ns_1@cb-example-0003.cb-example.default.svc', 'ns_1@cb-example-0004.cb-example.default.svc', 'ns_1@cb-example-0005.cb-example.default.svc', 'ns_1@cb-example-0006.cb-example.default.svc', 'ns_1@cb-example-0007.cb-example.default.svc', 'ns_1@cb-example-0008.cb-example.default.svc', 'ns_1@cb-example-0009.cb-example.default.svc'], EjectNodes = [], Failed over and being ejected nodes = []; Delta recovery nodes = ['ns_1@cb-example-0008.cb-example.default.svc'], Delta recovery buckets = all;; Operation Id = ae45abc595df96fd5caff169c80ca2e8 |
|
|
|
|
2024-06-03T09:14:34.281Z, ns_orchestrator:0:critical:message(ns_1@cb-example-0006.cb-example.default.svc) - Rebalance exited with reason {service_rebalance_failed,index, {agent_died,<0.6841.0>, {linked_process_died,<0.8097.1>, {'ns_1@cb-example-0006.cb-example.default.svc', {timeout, {gen_server,call, [<0.7915.0>, {call,"ServiceAPI.StartTopologyChange", #Fun<json_rpc_connection.0.36915653>, #{timeout => 60000}}, 60000]}}}}}}.Rebalance Operation Id = ae45abc595df96fd5caff169c80ca2e8 |
first_failover 0009 at 2024-06-03T09:14:39.828Z
Cluster tried to fail 0006 (Index+query) at 2024-06-03T09:14:41.065Z
first_failover 0009 completed at 2024-06-03T09:15:34.531Z
2024-06-03T09:14:39.828Z, failover:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Starting failing over ['ns_1@cb-example-0009.cb-example.default.svc']
|
|
|
2024-06-03T09:14:41.065Z, auto_failover:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Could not automatically fail over nodes (['ns_1@cb-example-0006.cb-example.default.svc']). Failover is running.
|
|
|
2024-06-03T09:15:34.372Z, failover:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Deactivating failed over nodes ['ns_1@cb-example-0009.cb-example.default.svc']
|
|
|
2024-06-03T09:15:34.531Z, ns_orchestrator:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Failover completed successfully.
|
SIGTERM Received at 2024-06-03T09:29:31.258Z
[error_logger:info,2024-06-03T09:29:31.258Z,babysitter_of_ns_1@cb.local:erl_signal_server<0.79.0>:ale_error_logger_handler:do_log:101]
|
=========================NOTICE REPORT=========================
|
SIGTERM received - shutting down
|
second_failover 0009 at 2024-06-03T09:29:30.817Z
2024-06-03T09:29:30.817Z, failover:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Starting failing over ['ns_1@cb-example-0009.cb-example.default.svc']
|
second_failover 0009 completed at 2024-06-03T09:29:31.148Z
2024-06-03T09:29:31.148Z, ns_orchestrator:0:info:message(ns_1@cb-example-0006.cb-example.default.svc) - Failover completed successfully.
|
Operator logs analysis:-
Operator confirms 0008 rebalance is completed but in the server, it failed at 2024-06-03T09:14:34.281Z,.
Operator started 0009 failover without attempting a rebalance which failed for 0008.
{"level":"info","ts":"2024-06-03T09:12:46Z","logger":"kubernetes","msg":"Creating pod","cluster":"default/cb-example","name":"cb-example-0008","image":"couchbase/server:7.6.1"} |
|
|
{"level":"info","ts":"2024-06-03T09:14:36Z","logger":"cluster","msg":"Resource updated","cluster":"default/cb-example","diff":"-{v2.ClusterStatus}.Conditions[1->?]:{Type:Balanced Status:False LastUpdateTime:2024-06-03T09:13:27Z LastTransitionTime:2024-06-03T09:13:27Z Reason:Unbalanced Message:The operator is attempting to rebalance the data to correct this issue};+{v2.ClusterStatus}.Conditions[?->1]:{Type:Balanced Status:True LastUpdateTime:2024-06-03T09:14:36Z LastTransitionTime:2024-06-03T09:14:36Z Reason:Balanced Message:Data is equally distributed across all nodes in the cluster}"} |
|
|
{"level":"info","ts":"2024-06-03T09:14:39Z","logger":"scheduler","msg":"Scheduler status","cluster":"default/cb-example","name":"cb-example-0008","class":"index-query","group":"us-east-2c"} |
|
|
{"level":"info","ts":"2024-06-03T09:14:39Z","logger":"cluster","msg":"cb-example-0009"} |
|
|
{"level":"info","ts":"2024-06-03T09:14:39Z","logger":"cluster","msg":"Upgrading pods with DeltaRecovery","cluster":"default/cb-example","names":["cb-example-0009"],"target-version":"7.6.1"} |
{"level":"info","ts":"2024-06-03T09:14:39Z","logger":"cluster","msg":"Unable to perform graceful failover on node. Reverting to hard failover.","cluster":"default/cb-example","name":"cb-example-0009"} |
Follow-ups?
- 0008 rebalance failed at 2024-06-03T09:14:34.281Z, why did the operator started 0009 first_failover at 2024-06-03T09:14:39.828Z with out reattempting the rebalance of 0008.
- What causes two failovers for pod 0009, as it gets re-created with a 7.6.1 image which only requires a rebalance to complete the upgrade?
- Why is Cluster trying to failover 0006 after 2 seconds of failing over of 0009?
CB logs - https://supportal.couchbase.com/snapshot/d048242a2d17a9e1472f8bb6c685a718::0
Operator logs - cbopinfo-20240603T195043+0530.tar.gz![]()
Attachments



Issue Links
- mentioned in
-
Page Loading...