- Set antiaffinity to true in couchbase-cluster.yaml.
- There is one master node and 2 worker nodes.
[root@ip-172-31-7-110 couchbase-operator]# kubectl get nodes
|
NAME STATUS ROLES AGE VERSION
|
ip-172-31-1-197.us-east-2.compute.internal Ready <none> 57d v1.10.2
|
ip-172-31-6-25.us-east-2.compute.internal Ready <none> 57d v1.10.2
|
ip-172-31-7-110.us-east-2.compute.internal Ready master 57d v1.10.2
|
* There are three pods to be scheduled as mentioned in couchbase-cluster.yaml:
servers:
|
- size: 3
|
name: all_services
|
services:
|
- data
|
- index
|
- query
|
- search
|
- eventing
|
- analytics
|
* Since
anti-affinity is set to true, there is no worker node for the third pod to be scheduled and the third pod fails to be scheduled as expected. The logs also print out messages appropriately indicating this behavior:
time="2018-06-29T05:24:57Z" level=info msg="Finish reconciling" cluster-name=cb-example module=cluster
|
time="2018-06-29T05:24:57Z" level=error msg="failed to reconcile: Failed to add new node to cluster: unable to schedule pod: 0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules." cluster-name=cb-example module=cluster
|
* The first two pods are scheduled properly and are up and running:
[root@ip-172-31-7-110 couchbase-operator]# kubectl get pods -o wide
|
NAME READY STATUS RESTARTS AGE IP NODE
|
cb-example-0000 1/1 Running 0 12m 10.44.0.5 ip-172-31-6-25.us-east-2.compute.internal
|
cb-example-0001 1/1 Running 0 12m 10.36.0.2 ip-172-31-1-197.us-east-2.compute.internal
|
couchbase-operator-5d7dfb795f-wthfr 1/1 Running 0 2d 10.36.0.1 ip-172-31-1-197.us-east-2.compute.internal
|
* However, after logging into the UI, it appears that the operator left the cluster in an inconsistent state (pending rebalance) as shown below:
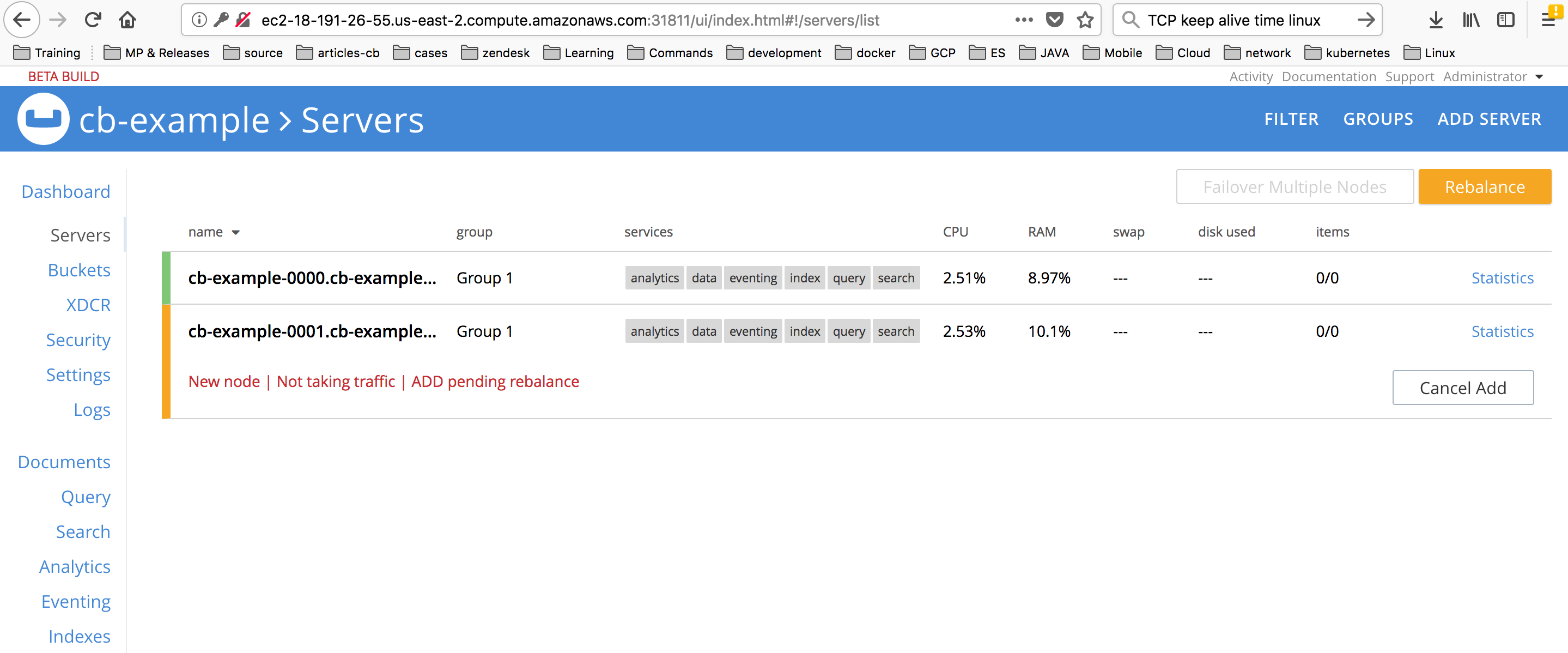
Question: Since 2 pods out of 3 pods are scheduled successfully due to node availability, isn't the operator expected to manage those 2 pods correctly? Is the cluster expected to be left in this state?
Improvement
 Minor
Minor