Details
-
Bug
-
Resolution: Duplicate
-
 Blocker
Blocker
-
2.5.1, 3.0
-
Security Level: Public
-
None
-
Untriaged
-
Centos 64-bit
-
No
-
June 30 - July 18
Description
Build
--------
3.0.0-432
Scenario
--------------
1. Setup two 2node clusters, 1 default bucket on each cluster, bi-dir replication between them. Start loading 1000 docs.
2. Pause replication on either sides, delete destination bucket and recreate it. Do not create replication to source cluster. No workload on dest cluster.
3. Resume replication from source cluster and wait for replication to end.
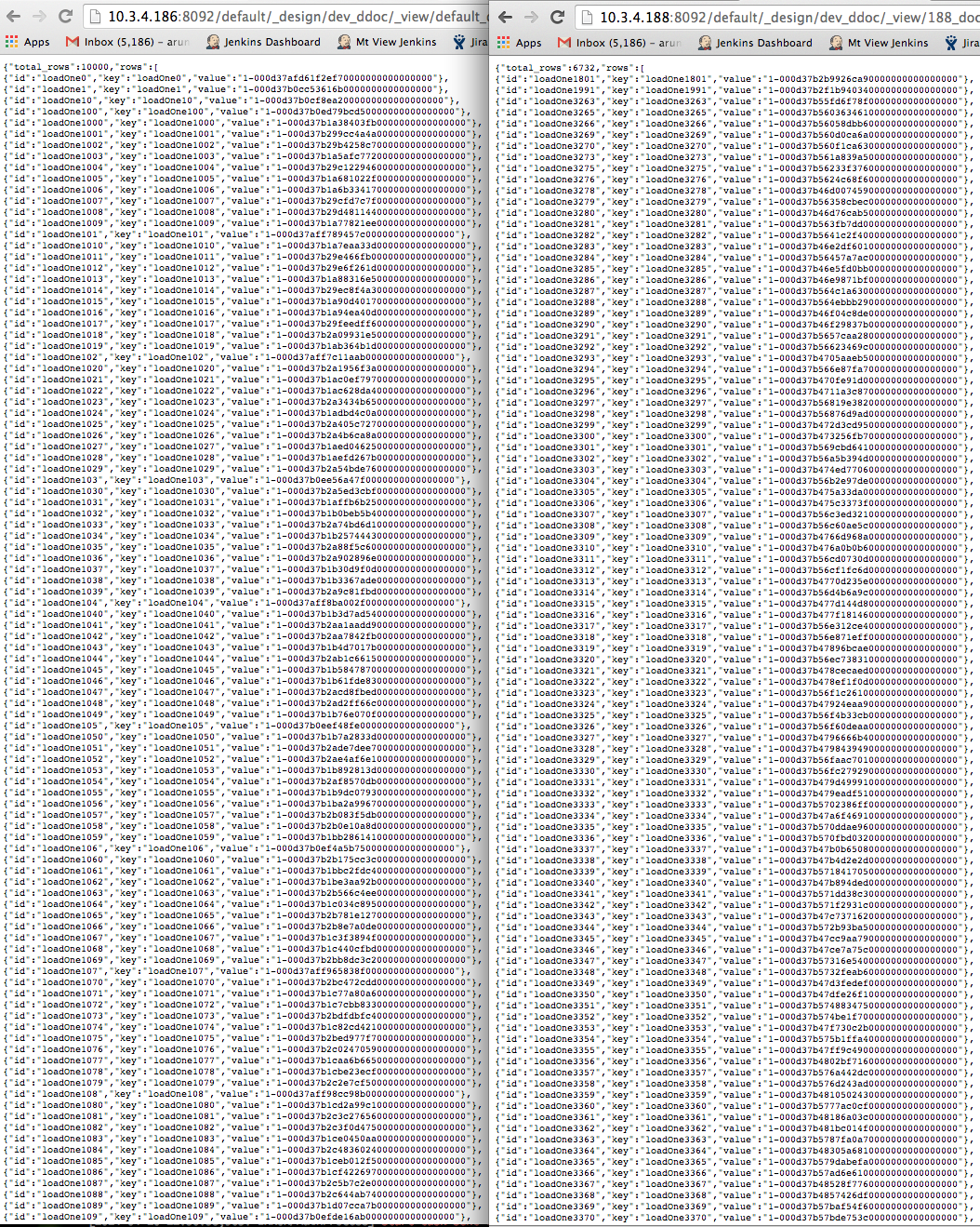
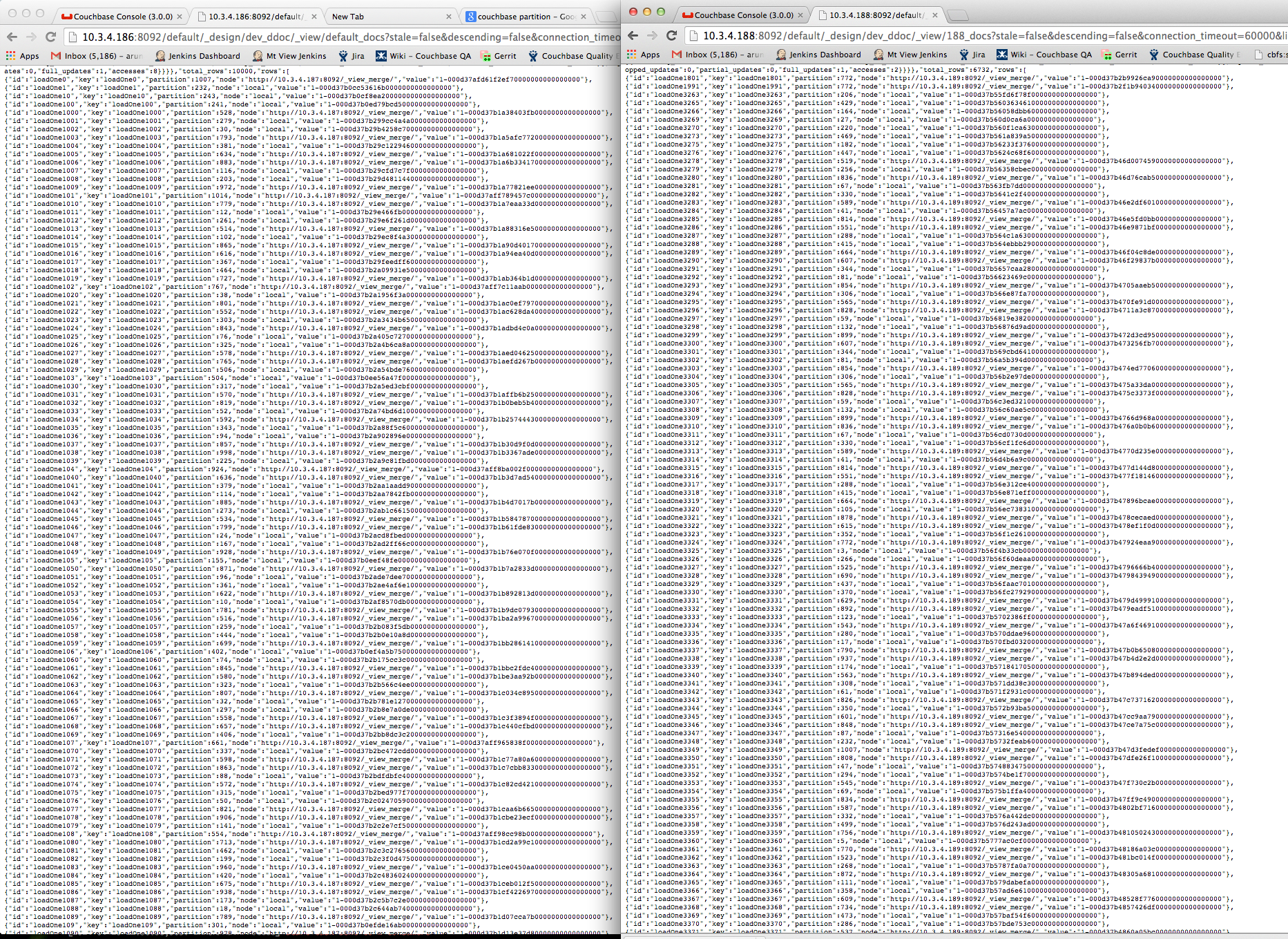
Item count on source = 10000, on dest = 9990, no xdcr activity seen for 10 mins and longer.
Reproducible
------------------
Consistently reproducible with -
./testrunner -i bixdcr.ini -t xdcr.pauseResumeXDCR.PauseResumeTest.replication_with_pause_and_resume,items=10000,delete_bucket=destination,replication_type=xmem,pause=source
Observations
------------------
1. This issue is only seen in scenarios where there is no workload on source after resume and the source cluster is only replicating what it already has in memory. After resume when there's still workload happening, all docs are replicated.
2. Not sure if this can be seen with plain xdcr without pause/resume. Will try and update the issue.
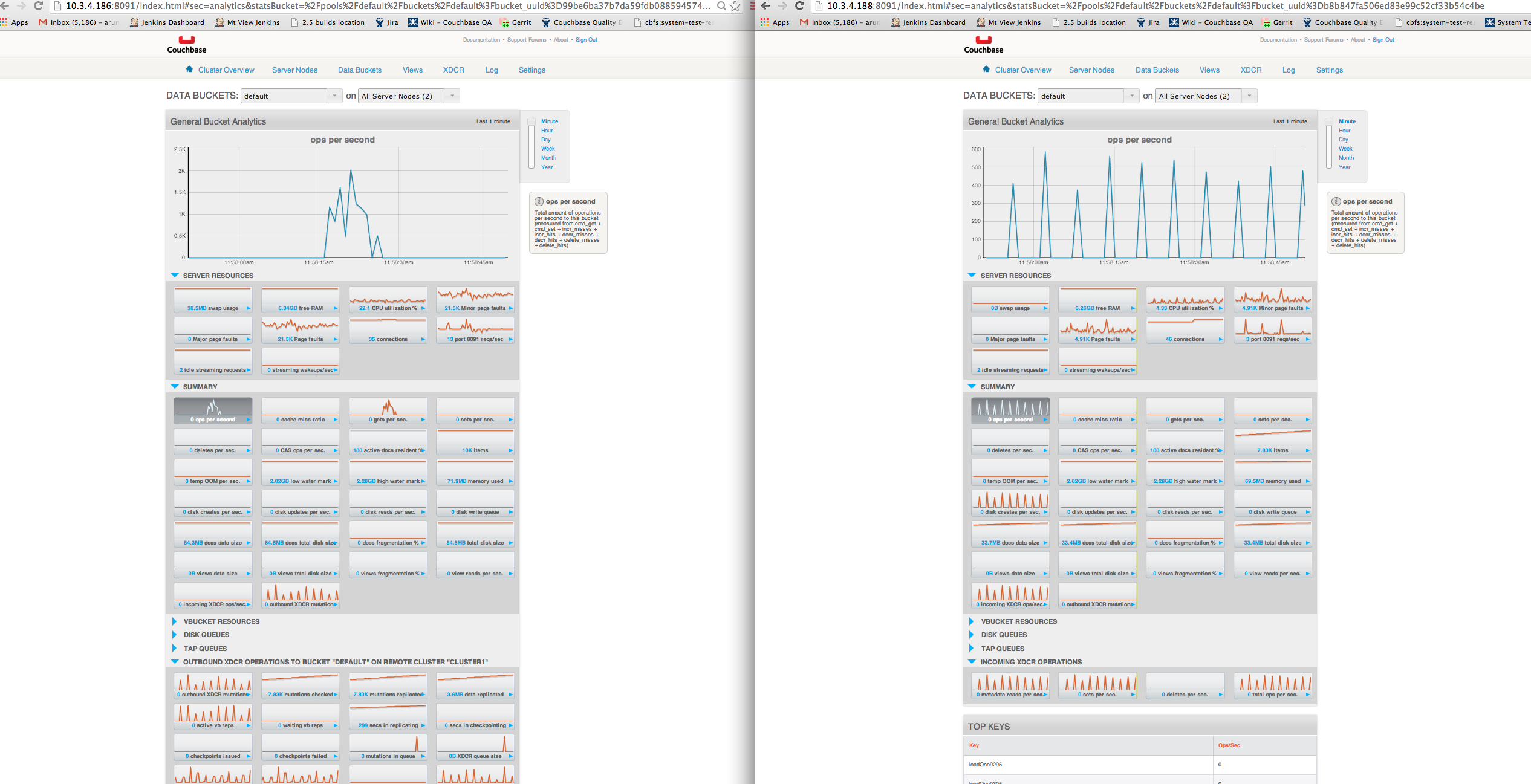
3. Data replication to destination is spikey and slow(screenshot attached). Although there is no data load on source, outbound mutations are seen in spurts(like spikes), which wakes up replicators in spurts(which is justified) which is reflected on incoming_ops in dest cluster. So here it doesn't appear to be a problem with replicators itself. My qn here is - is it ok to see spikey outbound mutations when there is no data load?
Attaching cbcollect logs.
.186, .187 --> source cluster
.188, .189 --> destination cluster
Attachments
Issue Links
- relates to
-
-

- Closed
-