Details
-
Bug
-
Resolution: Fixed
-
 Test Blocker
Test Blocker
-
3.0
-
Security Level: Public
-
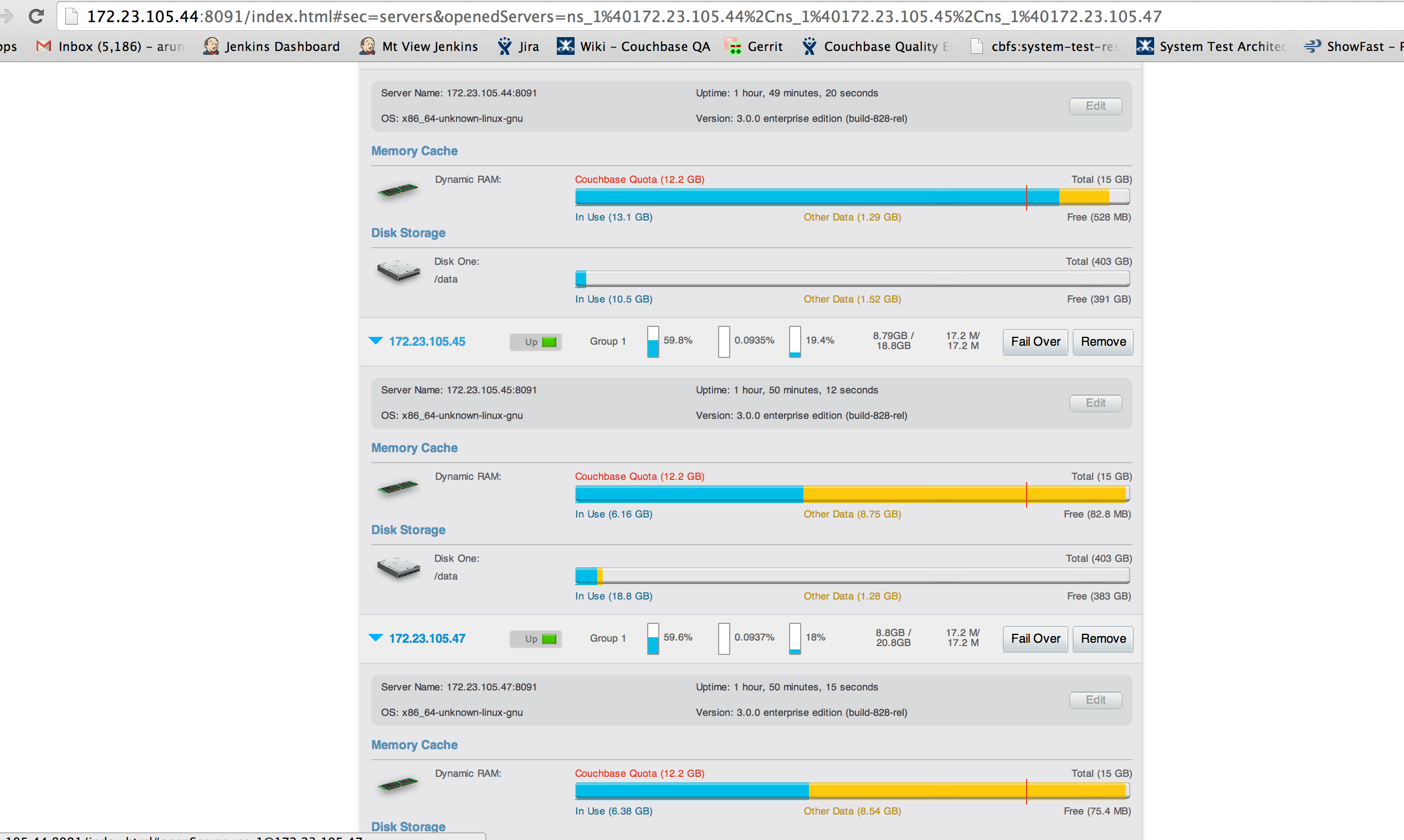
CentOS 6.x 8*8 clusters. Each node : 15GB RAM, 450Gb HDD
-
Untriaged
-
Unknown
-
June 30 - July 18
Description
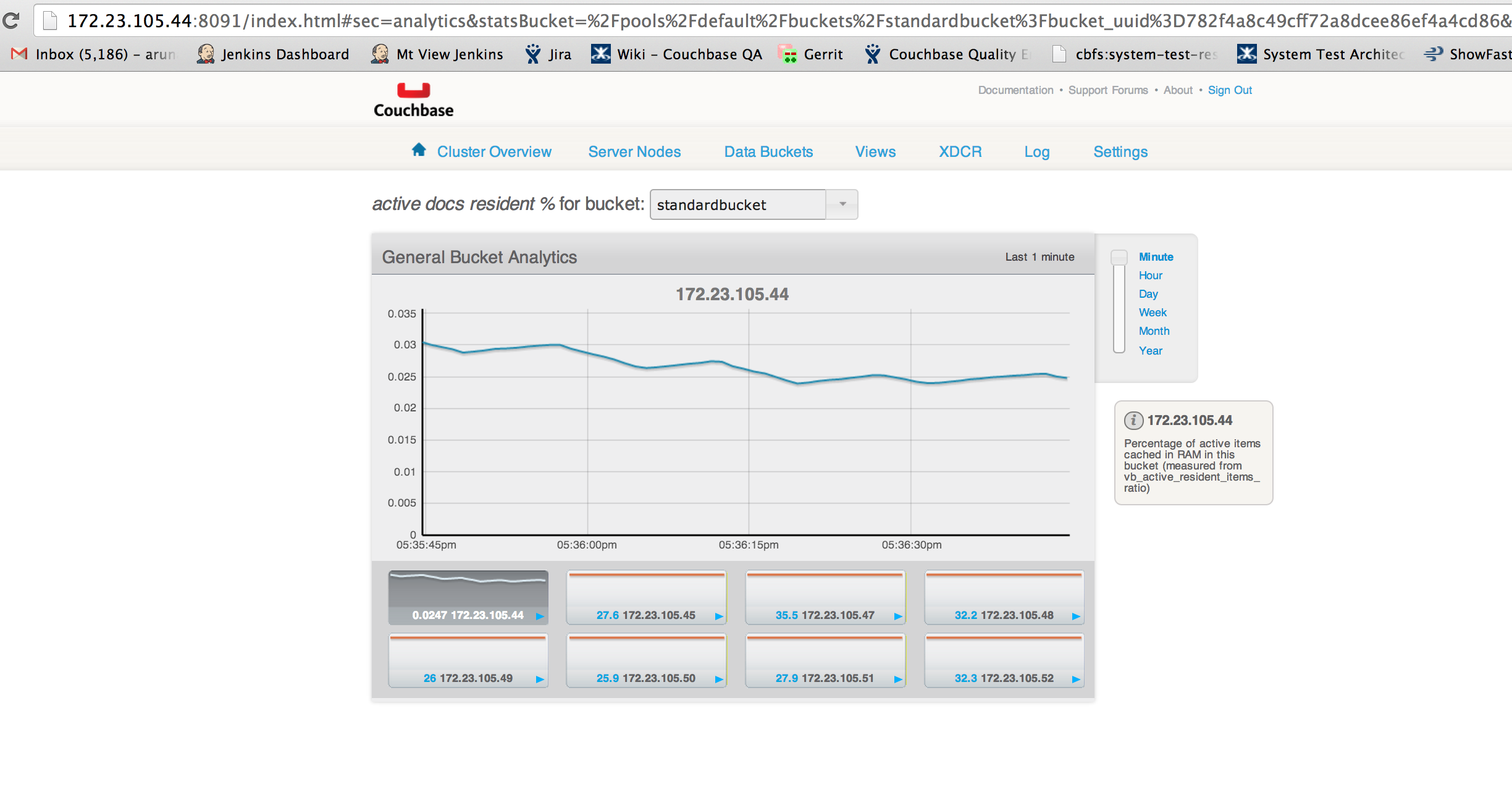
Continuation on MB-11448 [This system test was modified to maintain 25% active resident item ratio compared to the previous run which was <1% ]
Build
--------
3.0.0-840(xdcr on upr, internal replication on upr)
Clusters
-----------
Source : http://172.23.105.44:8091/
Destination : http://172.23.105.54:8091/
The clusters are available to investigate.
Steps
--------
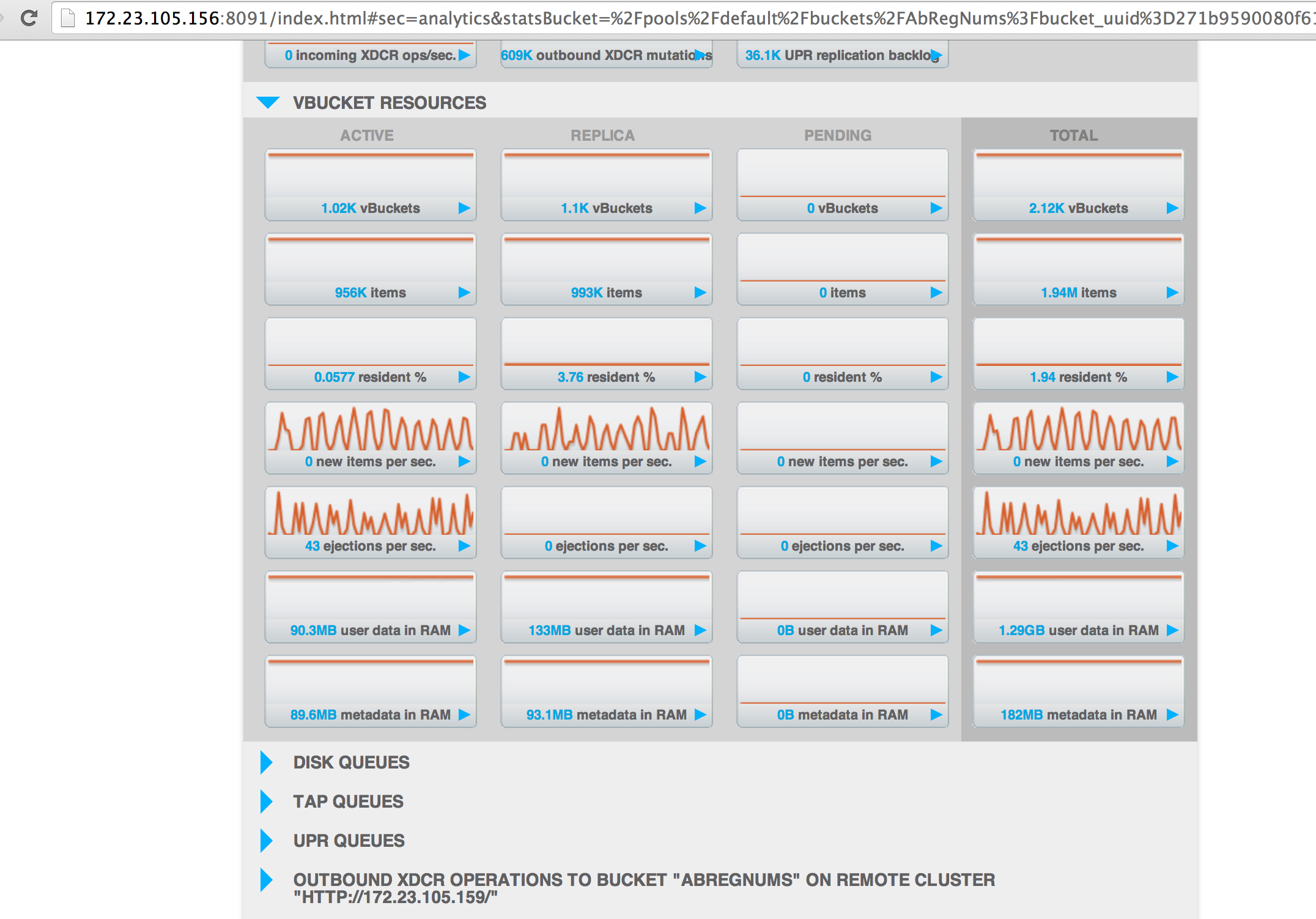
1. Load on both clusters till vb_active_resident_items_ratio < 50.
2. Access phase with 50% gets, 50%deletes runs for 3 hours
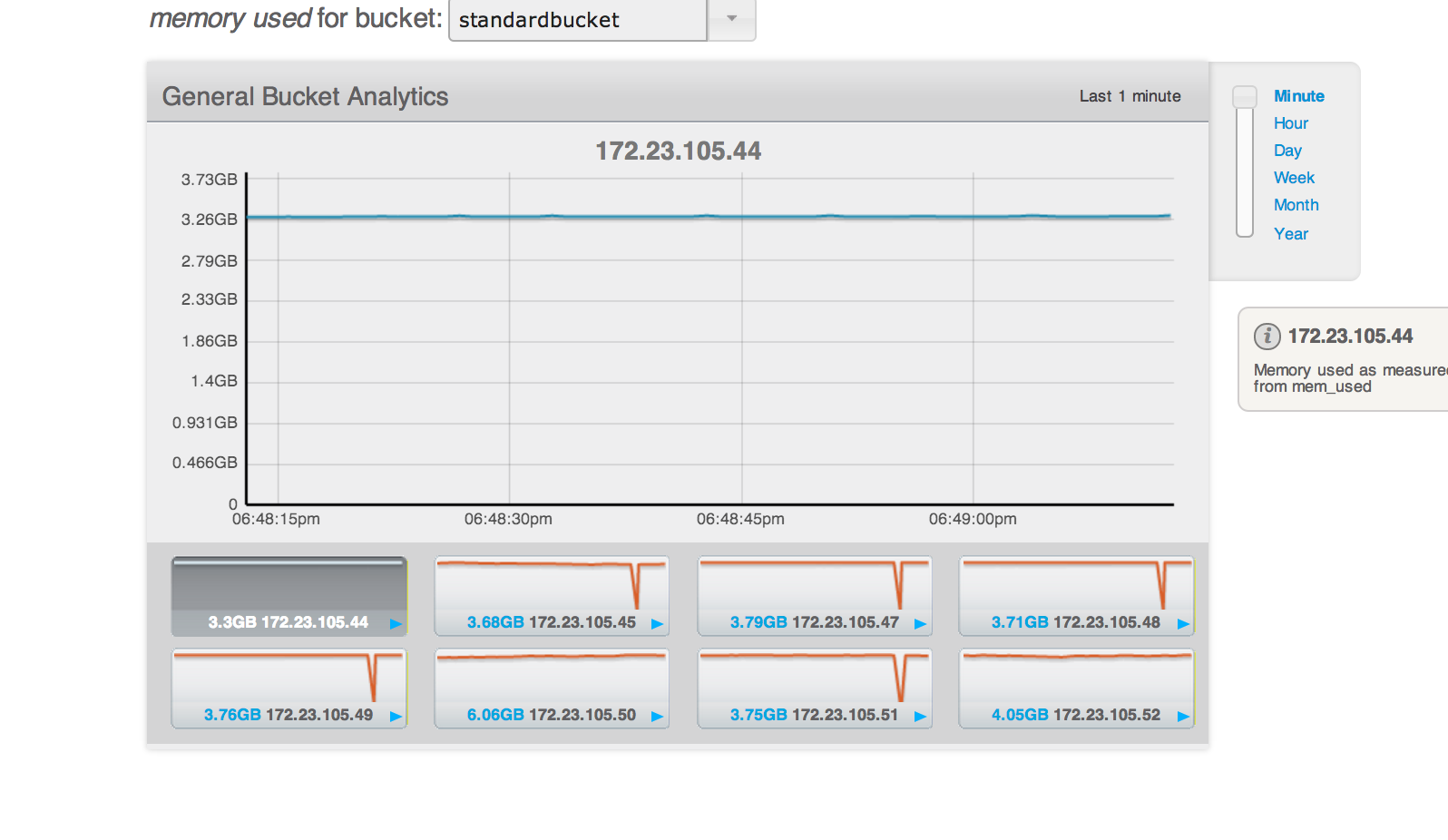
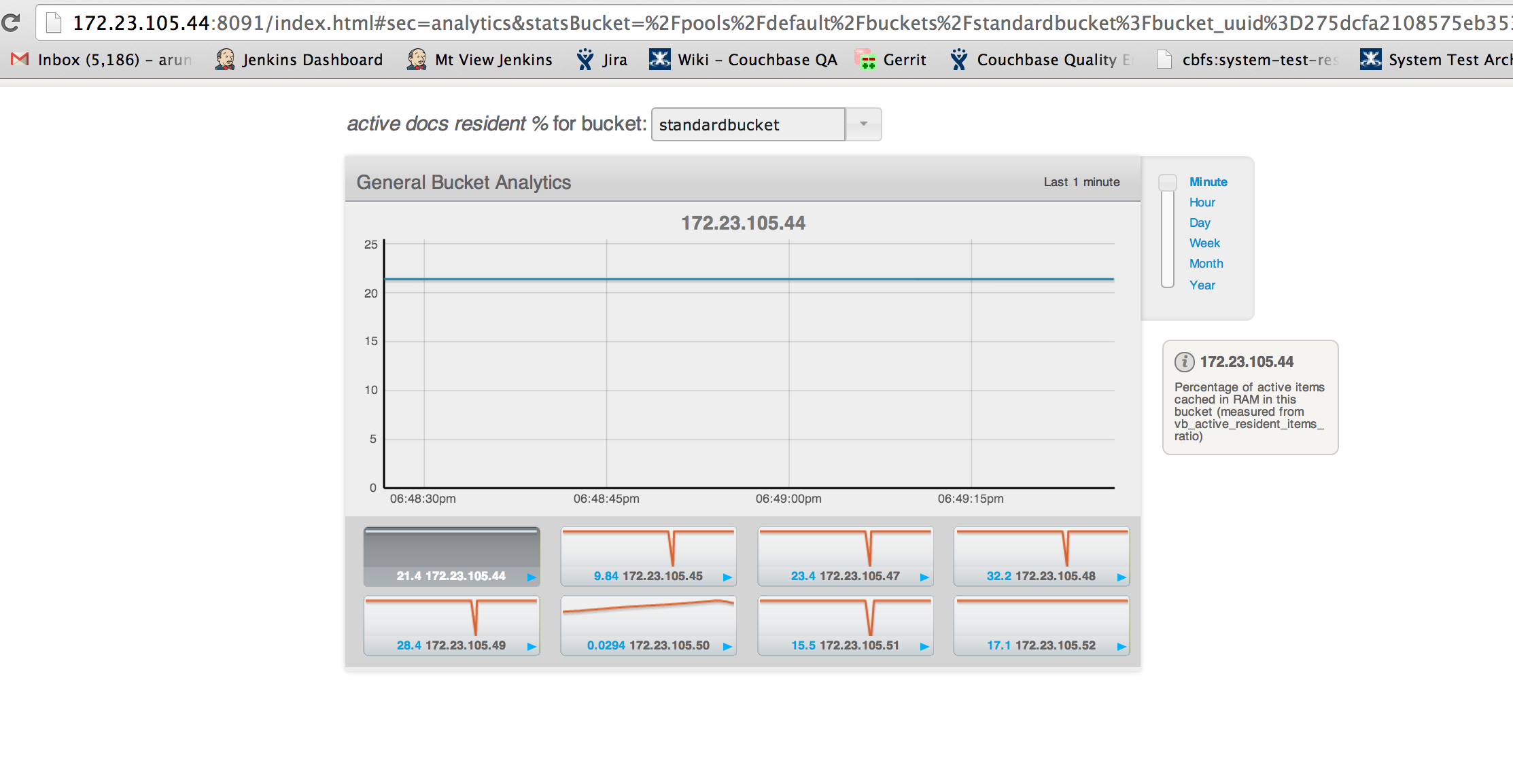
Bucket under discussion: standardbucket (has uni-xdcr)
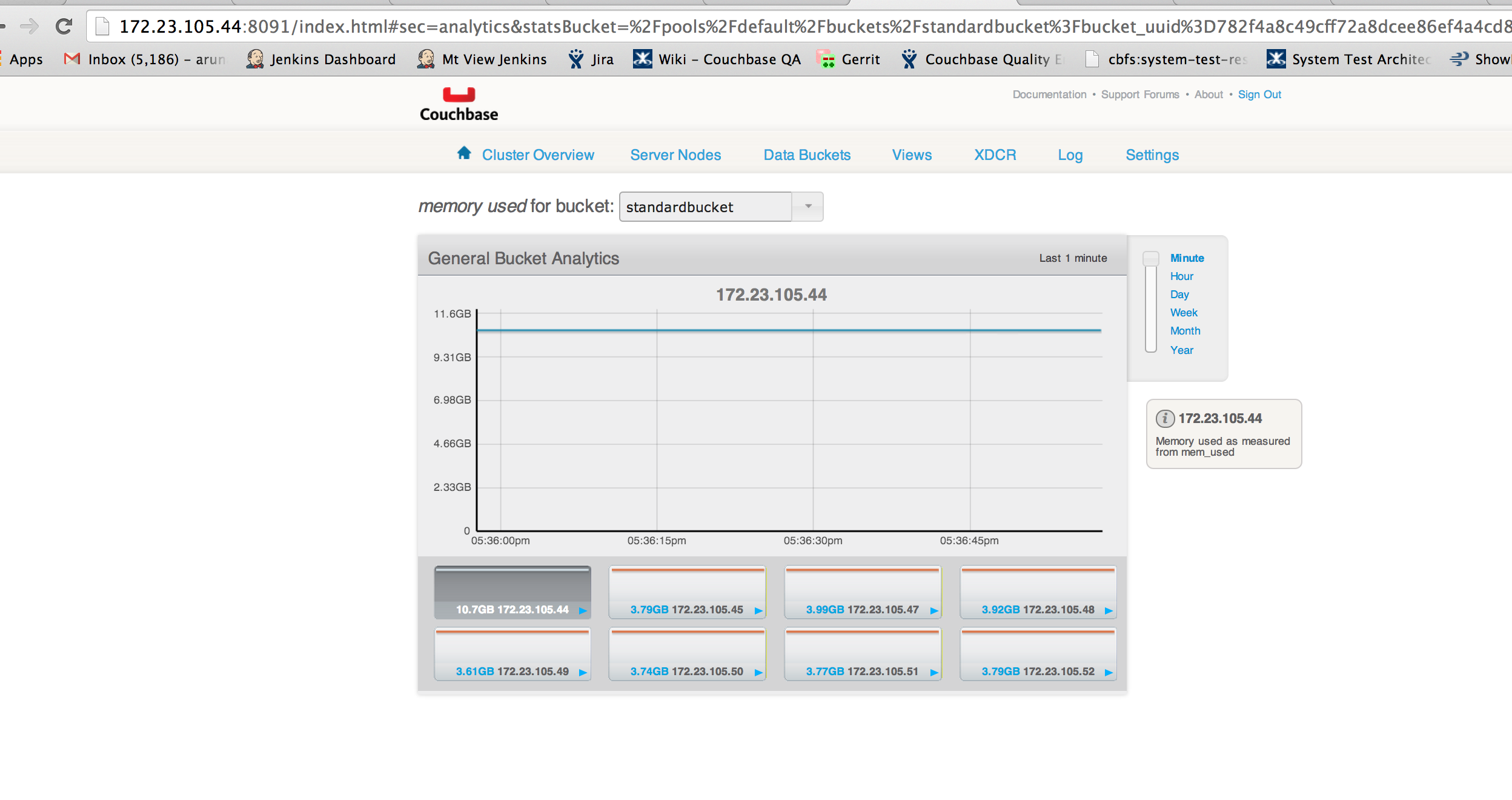
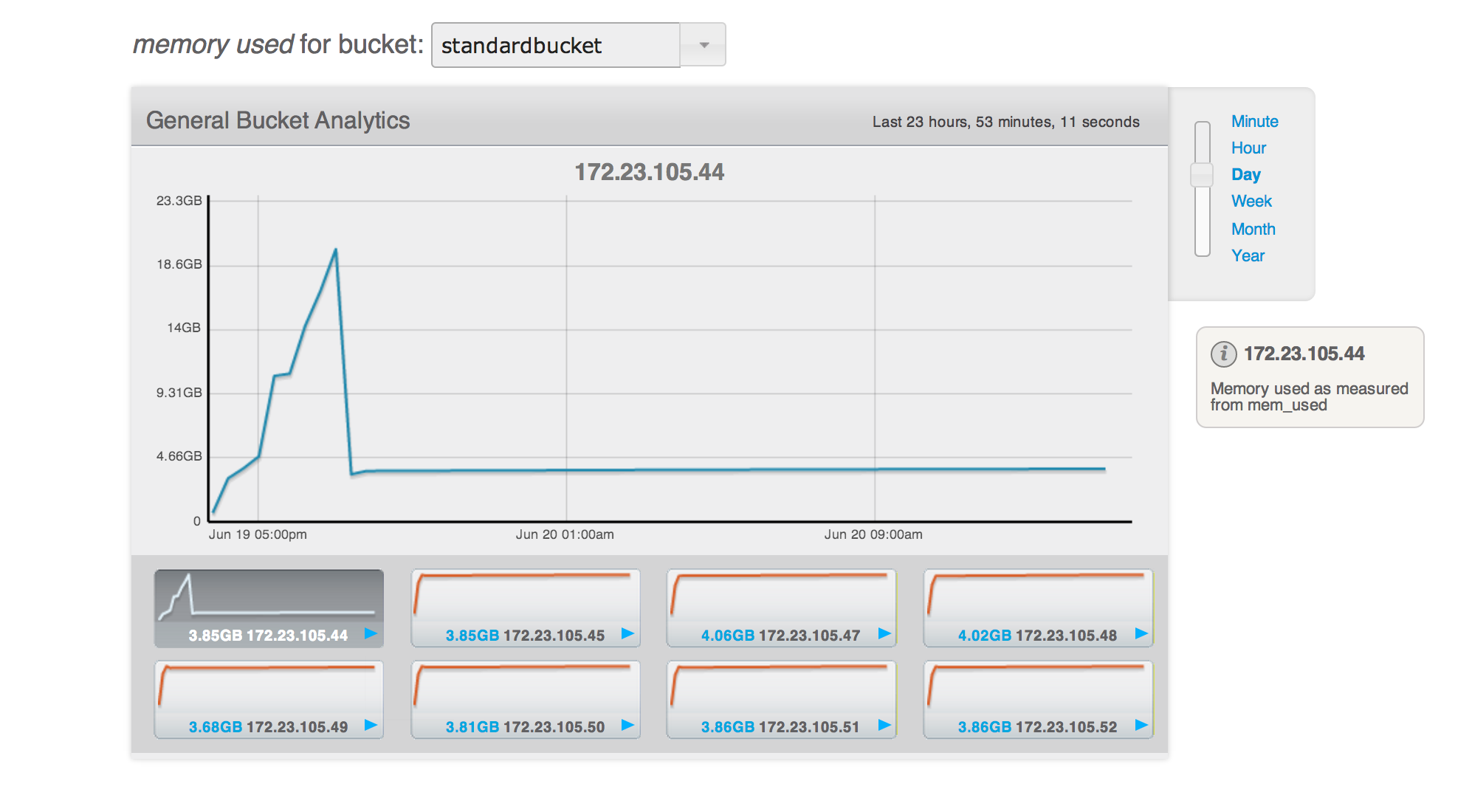
Another bucket standardbucket1 also has uni-xdcr but it's memory usage is comparable to that of other nodes. So it may not be due to XDCR.
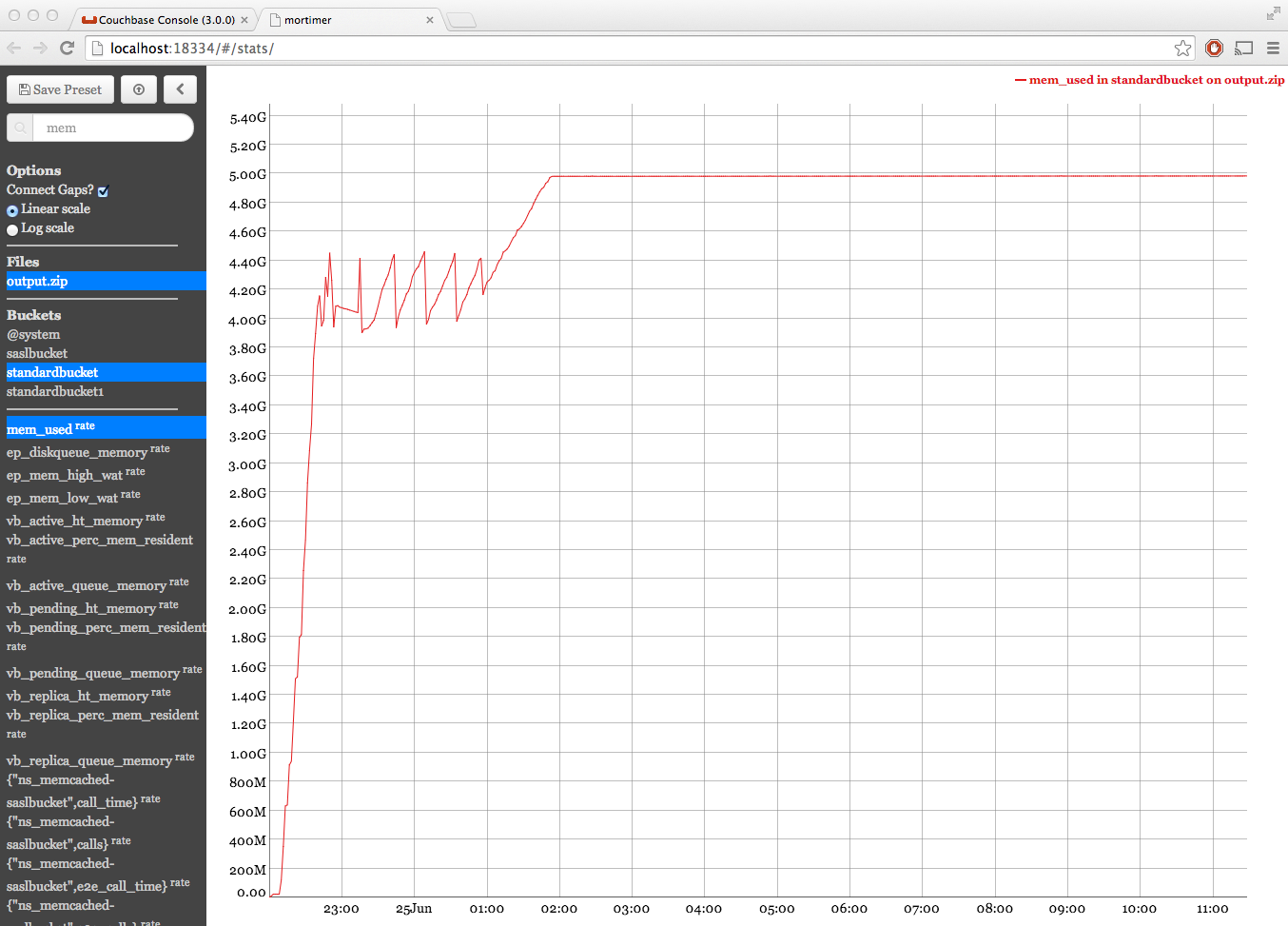
Bucket capacity:5GB but ep_value_size is >10gb while the node is at 0% dgm.
Rest of the nodes are at 75% dgm with 3.8GB.
Cluster C1: http://172.23.105.44:8091/
C2 : http://172.23.105.54:8091/
See attached screenshots and logs. Marking this as a test blocker because rebalance in this scenario will hang.
Attachments
Issue Links
- relates to
-
-

- Closed
-