Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
3.0
-
Security Level: Public
-
None
-
Build 3.0.0-1005
Platform = Physical
OS = CentOS 6.5
CPU = Intel Xeon E5-2680 v2 (40 vCPU)
Memory = 256 GB
Disk = RAID 10 SSD
-
Untriaged
-
Centos 64-bit
-
Yes
-
June 30 - July 18
Description
5 -> 5 UniDir, 2 buckets x 500M x 1KB, 10K SETs/sec, LAN
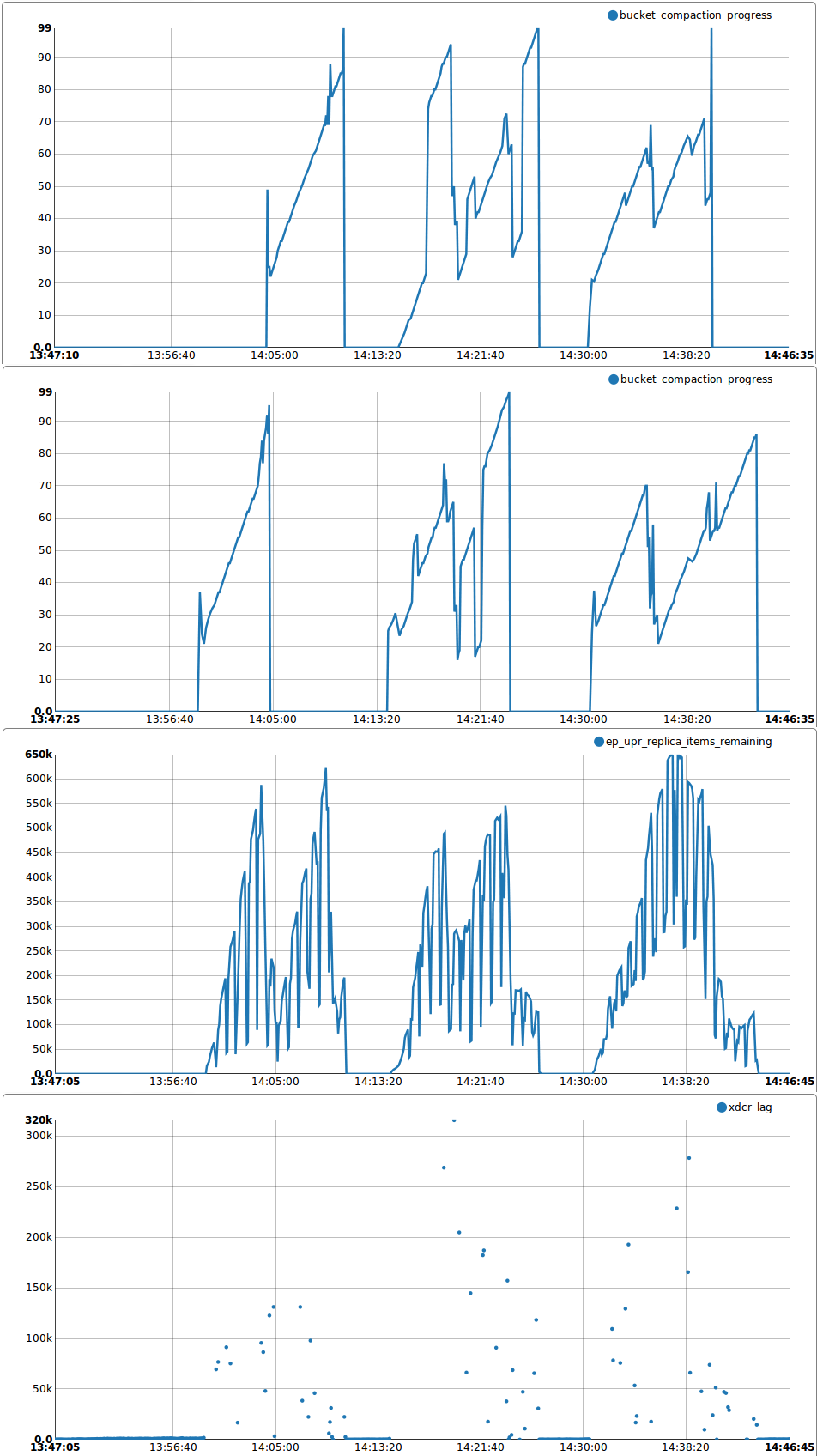
Similar to MB-11731 which is getting worse and worse. But now compaction affects intra-cluster replication and XDCR latency as well:
"ep_upr_replica_items_remaining" reaches 1M during compaction
"xdcr latency" reaches 5 minutes during compaction.
See attached charts for details. Full reports:
http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=atlas_c1_300-1005_a66_access
http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=atlas_c2_300-1005_6d2_access
One important change that we made recently - http://review.couchbase.org/#/c/39647/.
The last known working builds is 3.0.0-988.
Attachments
Issue Links
- is duplicated by
-
-

- Closed
-
| For Gerrit Dashboard: MB-11799 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 39880,1 | MB-11799 Flusher picks next vbucket if it is locked | master | ep-engine | Status: ABANDONED | -2 | +1 |
| 39958,5 | MB-11799 re-use existing task for rescheduling vb snapshots | master | ep-engine | Status: MERGED | +2 | +1 |
| 40043,3 | MB-11799 Throttle vbucket compaction with the disk write queue size. | master | ep-engine | Status: MERGED | +2 | +1 |
| 40059,3 | MB-11799 Let the flusher update the last persisted checkpoint id. | master | ep-engine | Status: MERGED | +2 | +1 |