Details
-
Bug
-
Resolution: Duplicate
-
 Test Blocker
Test Blocker
-
4.0.0
-
Security Level: Public
-
400-2093
10 buckets, 10 gsi indexes
-
Untriaged
-
Unknown
Description
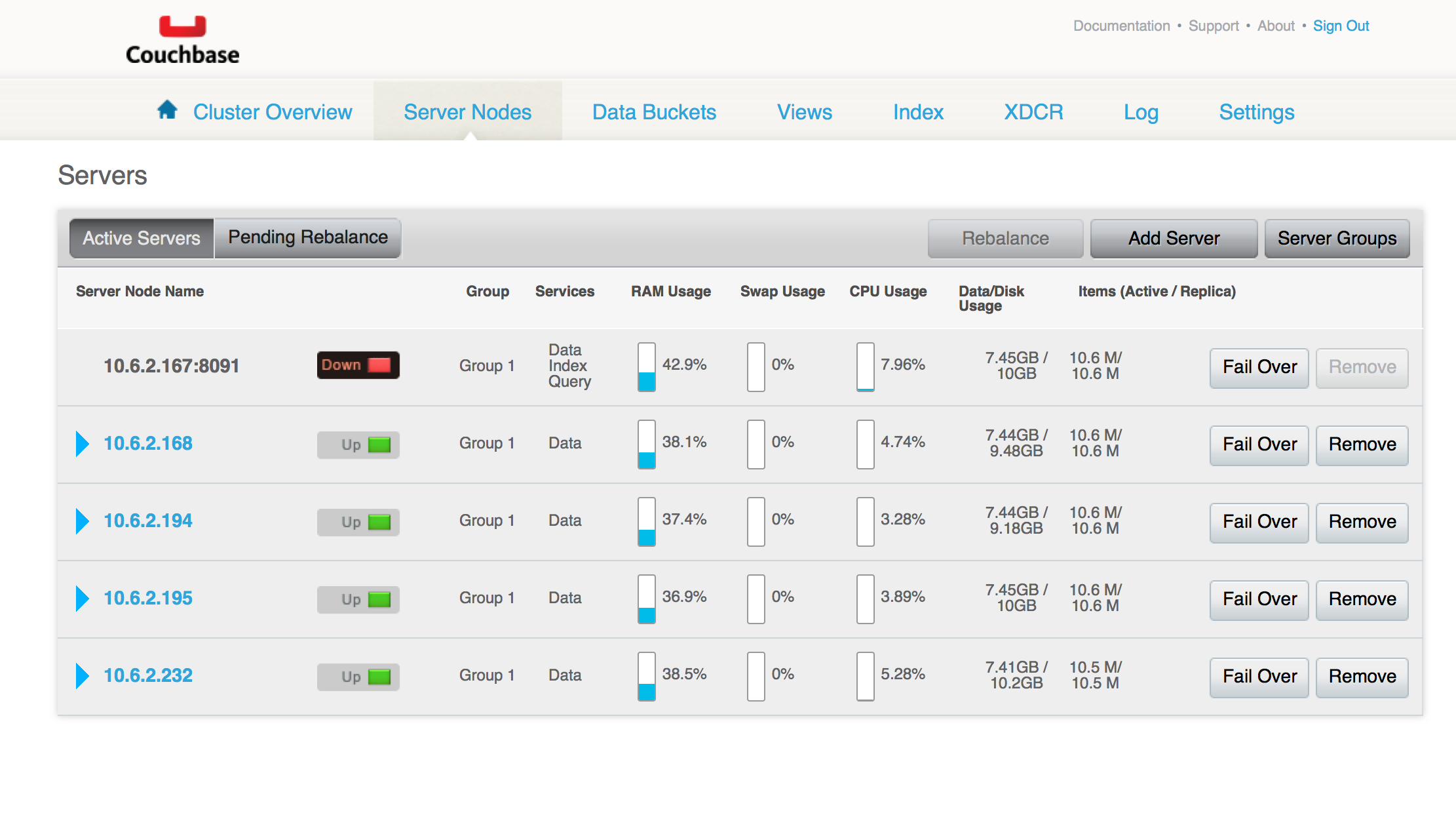
0.Cluster has unhealthy indexes - either the indexes are timing out, or showing "stale metadata" errors.
- To start over, I decided to drop the indexes - which fails with GSI scan timeout
- I restarted the indexer, hoping things work - No progress, same errors.
- To still make this work, I decided to delete the index files from its directory
storageDir=/index/@2i
rm -rf /index/@2i
Expectation - The cluster should have no indexes.
Restarting the indexer and projector - should get the cluster back to some workable state.
This did not work - I assume this is not supported?
The indexer logs now contain panic on "no valid seq no"
also, the Node is down and unusable.
Filing this is a "major" bug to know what caused the indexer to crash.
logs from indexer node https://s3.amazonaws.com/bugdb/bug_index/10_167_2.tar
Attachments
| For Gerrit Dashboard: MB-14969 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 51123,2 | MB-14969 : No Vaild Restart Seqno | unstable | indexing | Status: MERGED | +2 | +1 |