Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
4.0.0
-
Security Level: Public
-
400-3502
View Indexes
5M items, 50 warehouses
System configuration:
▪ Machine configuration:
⁃ SSDs
⁃ 24GB Ram
⁃ 250GB /data and /index disks
⁃ 8 Core CPU
⁃ Individual VMs ( non-shared)
▪ Indexer Settings : ( see attached settings.json)
⁃ Index Ram Quota on Index Nodes : 21GB,
⁃ 8 Indexer Threads
⁃ indexer.settings.scan_timeout:1400000 No index settings changed at any point on the test.
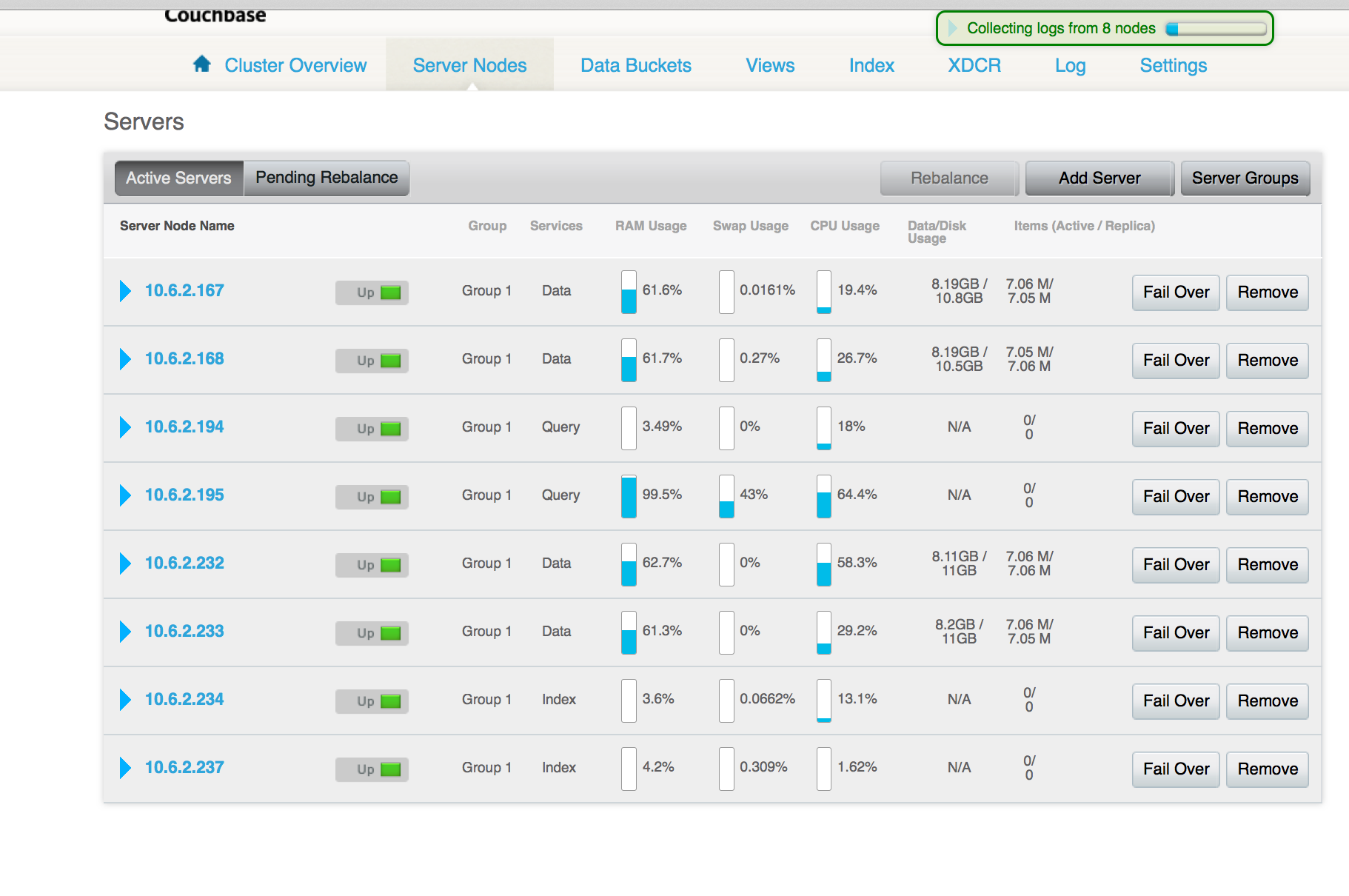
▪ 8 Node cluster
⁃ 2 Query nodes,
⁃ 4 KV nodes, 2 index ( defunct) nodes.
▪ 10 Buckets
▪ 50 warehouses for tppc(9) buckets and 5M items for default.
▪ 36 View indexes across 10 buckets ( 18 active, 18 replica)
400-3502 View Indexes 5M items, 50 warehouses System configuration: ▪ Machine configuration: ⁃ SSDs ⁃ 24GB Ram ⁃ 250GB /data and /index disks ⁃ 8 Core CPU ⁃ Individual VMs ( non-shared) ▪ Indexer Settings : ( see attached settings.json) ⁃ Index Ram Quota on Index Nodes : 21GB, ⁃ 8 Indexer Threads ⁃ indexer.settings.scan_timeout:1400000 No index settings changed at any point on the test. ▪ 8 Node cluster ⁃ 2 Query nodes, ⁃ 4 KV nodes, 2 index ( defunct) nodes. ▪ 10 Buckets ▪ 50 warehouses for tppc(9) buckets and 5M items for default. ▪ 36 View indexes across 10 buckets ( 18 active, 18 replica)
-
Untriaged
-
Unknown
Description
1. load data_ indexes
1. b : Rebalance out Data node.
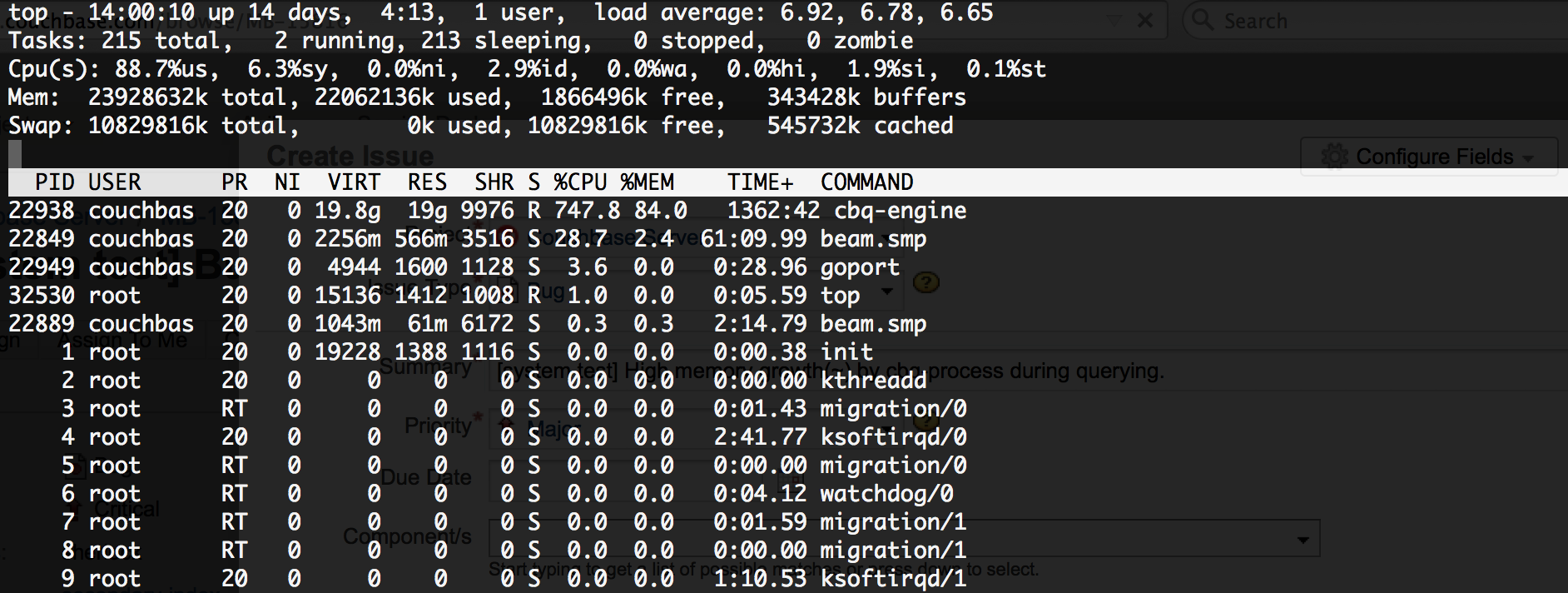
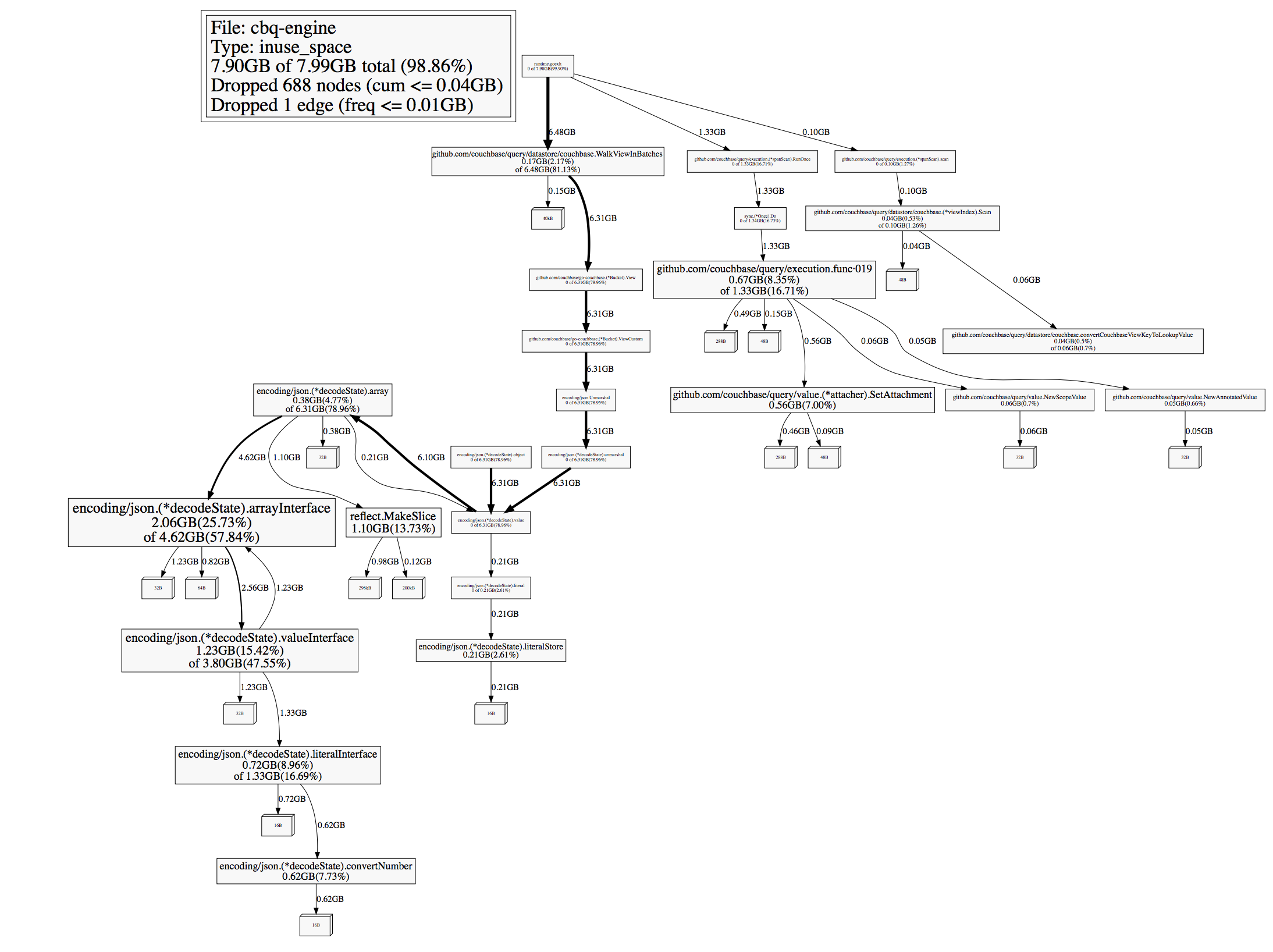
2. Query the cluster - started seeing high memory growth.
running load on tpcc and sabre. adding logs.
Memory grows upto 20G
Num clients :200
python ./tpcc.py --duration 720000 --warehouses 50 --clients 100 --no-load --debug n1ql
python ./tests/n1ql/dml_sabre.py -d 10000 -c 10 -q 10.6.2.195 -ops select -scan REQUEST_PLUS
python ./tests/n1ql/dml_sabre.py -d 10000 -c 100 -q 10.6.2.195 -ops select -scan NOT_BOUNDED
python ./tests/n1ql/dml_sabre.py -d 10000 -c 50 -q 10.6.2.195 -ops update
python ./tests/n1ql/dml_sabre.py -d 720000 -c 10 -q 10.6.2.195 -ops delete