Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
5.0.0
-
Untriaged
-
Unknown
Description
Steps to Reproduce
- Cluster of 4 nodes with reasonable spec (>=8 cores, SSD, fast network)
- Create one large (>10GB) bucket with 10% resident ratio
- client workload (e.g. pillowfight) doing ~20K writes / sec
- Rebalance in a 5th node to the cluster
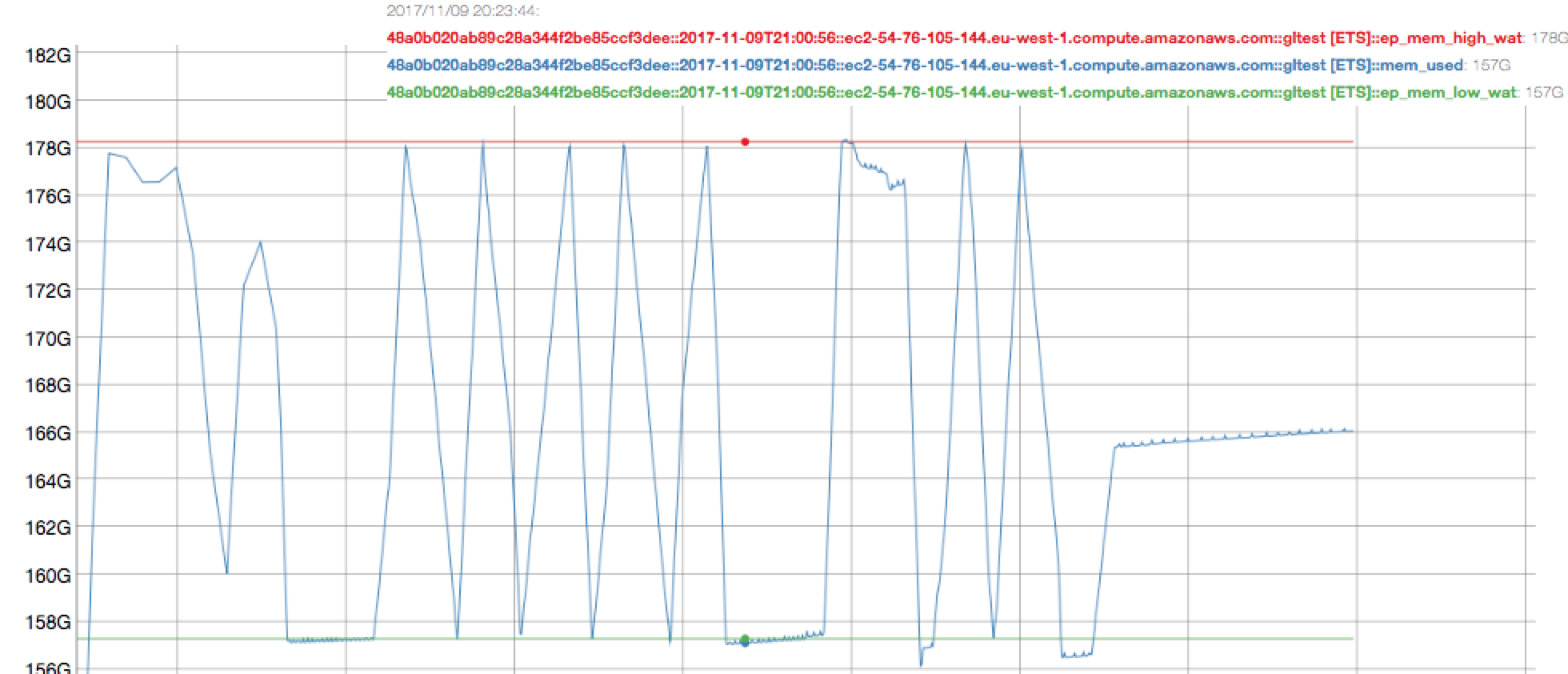
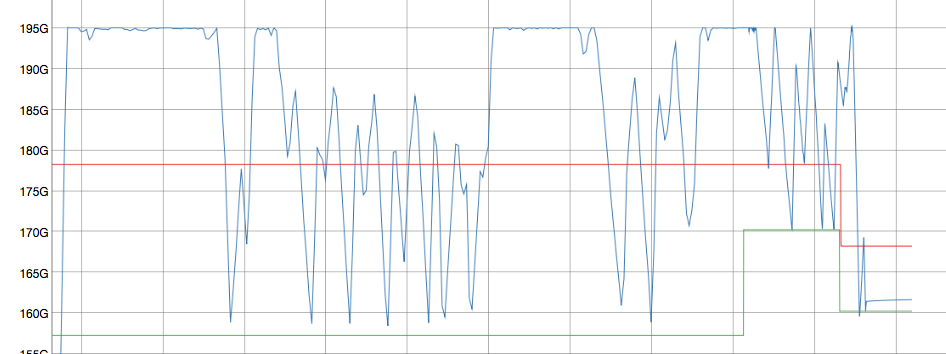
The above steps can result in the client receiving a significant spike in TMP_OOMs during the rebalance (from the incoming node) and degrade the application's performance. The suspected cause is that DCP replication streams from the existing nodes can quickly saturate the memory on the incoming node. The item pager is either not successfully invoked OR cannot eject items quickly enough - conjecture is it may require several passes to get an item with a sufficient LRU value to eject.
The desired behaviour is that the client application is basically unaffected by the rebalance. This could possibly be achieved in a number of ways. The following are merely suggestions to get the ball rolling:
- Change the relative priority of the ItemPager and DCP Processor tasks (currently the processor is higher priority).
- Run the item pager more aggressively - note it is not currently triggered by SET_WITH_META (which DCP consumer uses).
- Initialise the items on the incoming node with a different LRU value that allows them to be ejected on first pass of the item pager.
- Incorporate a more sophisticated throttle / backoff on the DCP stream when the HWM is reached so that frontend client ops have greater priority.