Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
4.6.0, 4.6.2, 5.0.0, 5.0.1
-
Untriaged
-
Unknown
Description
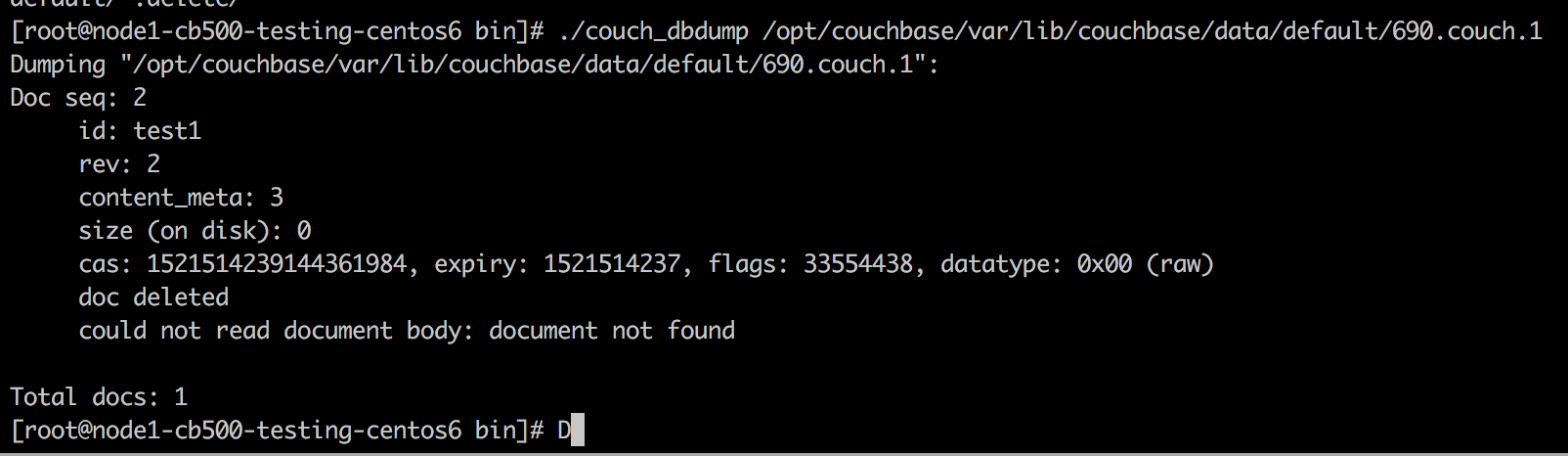
With XDCR a target node receiving DelWithMeta(key1) and that node does not know about key1, the requirement is that a delete of key1 is recreated (allowing future conflict resolution to occur).
A problem can occur when the source and target nodes compact and purge deleted documents (tombstones).
- If the target node purges ahead of the source, the target node may correctly remove tombstones, but this leaves the source/target out of sync.
- If an XDCR disconnect occurs before the source compacts, XDCR may 're-sync', i.e. ask the source for all documents from a historical seqno.
- The source node will then send to XDCR over local DCP all mutations and deletions, which will be replicated to the target node as SetWithMeta/DelWithMeta
- Many of these meta operations will be ignored, because conflict resolution spots if an incoming with-meta matches existing documents.
- The DelWithMeta which match keys that the target purged, means the target will re-create the deletes (queueing into checkpoints, writing to disk and writing to all local DCP clients).
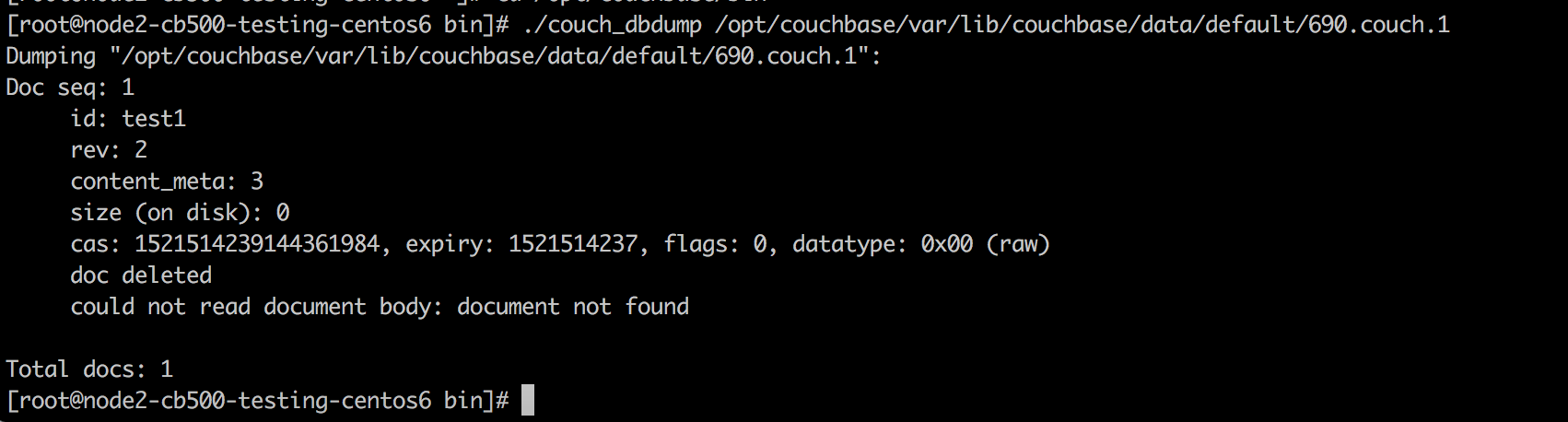
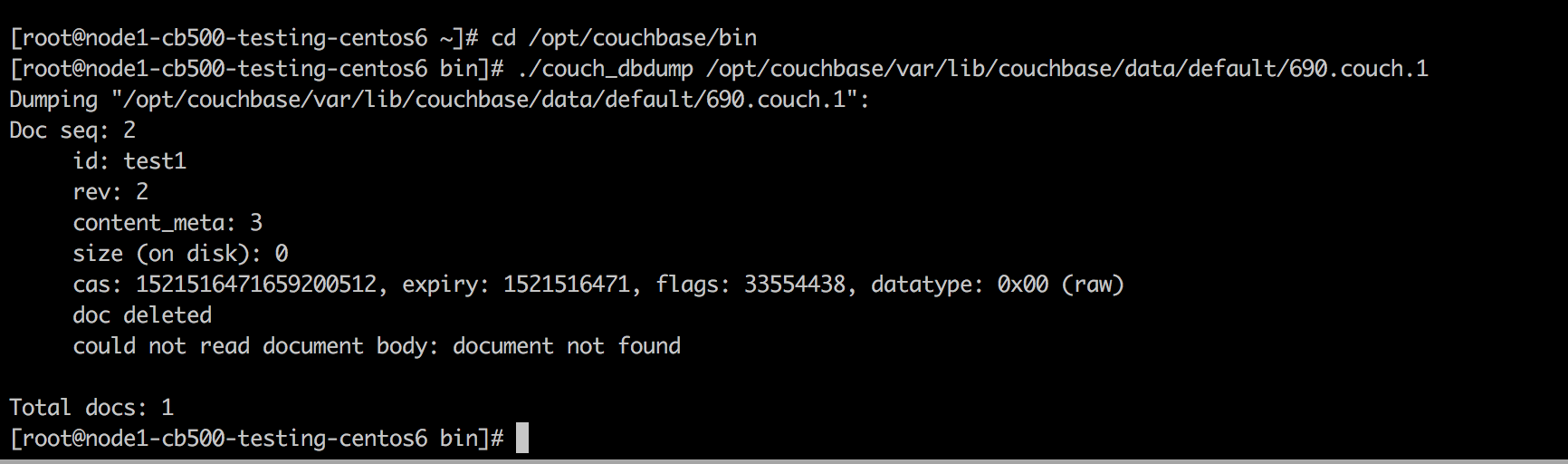
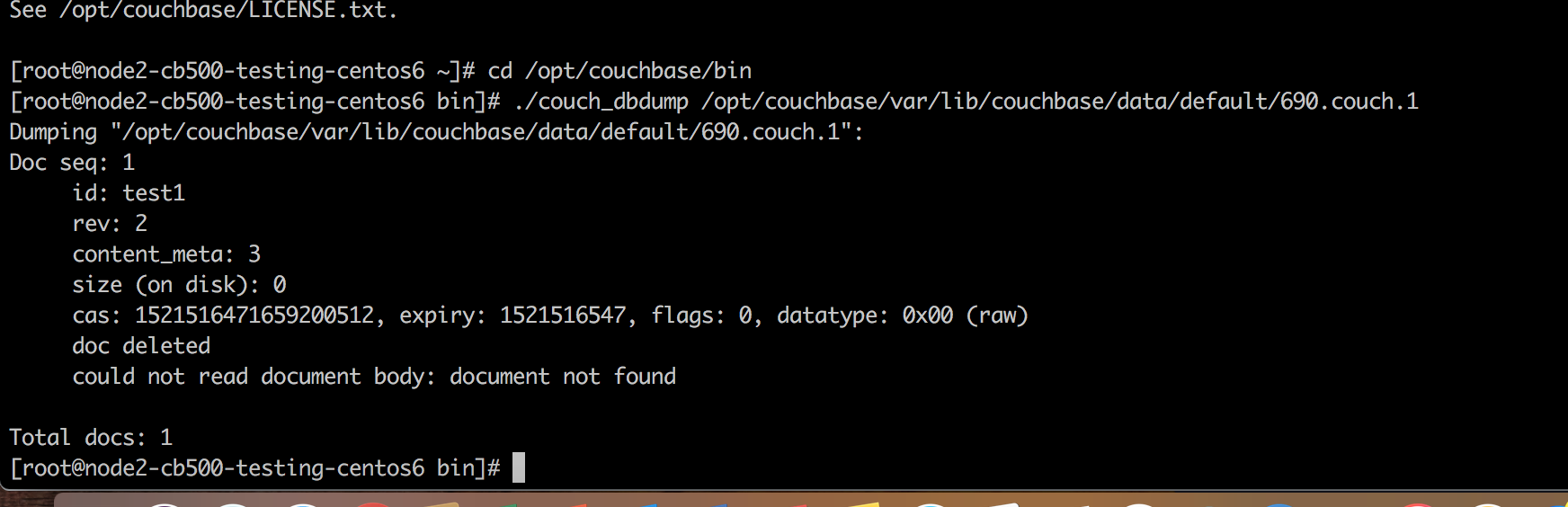
For workloads which make heavy use of deletion (perhaps all documents have fixed time-to-live) this scenario may end up driving very high utilisation (recreating many many deletes).
The problem occurs because when we create a tombstone, it is always given a time of now() as it's creation time (compaction uses the tombstones creation time and it's now() to work out the age of a tombstone and its eligibility for removal).
So in our example of target/source compacting out of sync, we can presume that overtime we build up a nice steady stream of deletions, we are writing tombstones spaced apart by their real deletion time.
When the target compacts, it may purge n deletes had nicely spanned creation times.
When the disconnect and re-sync occurs, the target will effectively bulk recreate tombstones which did have a nicely spanned deletion, to the exact same creation time (depending on how many deletes are generated before the clock ticks).
So those n deletes all now have the same purge time, and still the workload is creating new deletions. You can visualise it with a simple histogram showing that before we had a nice spread of documents at each expiry creation time, but after the compact/resync tombstones move to the same timestamp.
▲
|
│
|
│
|
│
|
┌─────────┐ │
|
│ No. of │ │
|
│ Deletes │ │ ┌───┐
|
└─────────┘ │ ┌───┐ │ │ ┌───┐
|
│ ┌───┐ │ │ ┌───┐ │ │ ┌───┐ │ │
|
│ │ │ │ │ │ │ │ │ │ │ │ │
|
│ │ │ │ │ │ │ │ │ │ │ │ │
|
│ │ │ │ │ │ │ │ │ │ │ │ │
|
└─┴───┴─┴───┴─┴───┴─┴───┴─┴───┴─┴───┴────────▶
|
┌───────────────────────┐
|
│ Delete Creation Time │
|
└───────────────────────┘
|
|
|
┌───┐
|
▲ │ │
|
│ │ │
|
│ │ │
|
│ │ │
|
┌─────────┐ │ │ │
|
│ No. of │ │ │ │
|
│ Deletes │ │ │ │ ┌───┐
|
└─────────┘ │ │ │ │ │ ┌───┐
|
│ │ │ │ │ ┌───┐ │ │
|
│ │ │ │ │ │ │ │ │
|
│ │ │ │ │ │ │ │ │
|
│ │ │ │ │ │ │ │ │
|
└─────────────┴───┴─┴───┴─┴───┴─┴───┴────────▶
|
┌───────────────────────┐
|
│ Delete Creation Time │
|
└───────────────────────┘
|
|
Now nothing stops this process cycling and the large group of tombstones can itself combine with other compact/disconnect cycles and grow, and overtime this cluster gets large and expensive to re-sync.