Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
5.5.0
-
5.5.0-2497
-
Untriaged
-
Centos 64-bit
-
No
Description
Script to Repro
./testrunner -i /tmp/testexec.8098.ini -p get-cbcollect-info=True,GROUP=bucket_op -t eventing.eventing_rebalance.EventingRebalance.test_memcache_crash_on_kv_and_eventing_node_during_eventing_rebalance,doc-per-day=10,dataset=default,nodes_init=5,services_init=kv-kv-eventing-eventing-index:n1ql,groups=simple,reset_services=True,GROUP=bucket_op
|
Steps
1) Create a 5 node cluster of kv-kv-eventing-eventing-index:n1ql
2) Deployed a eventing function.
3) Start loading docs on source bucket.
4) When 3 is in progress rebalance in an eventing node.
5) After rebalance reaches 30% or so kill memcached on 1 kv(172.23.108.91) and 1 eventing(172.23.109.137) node.
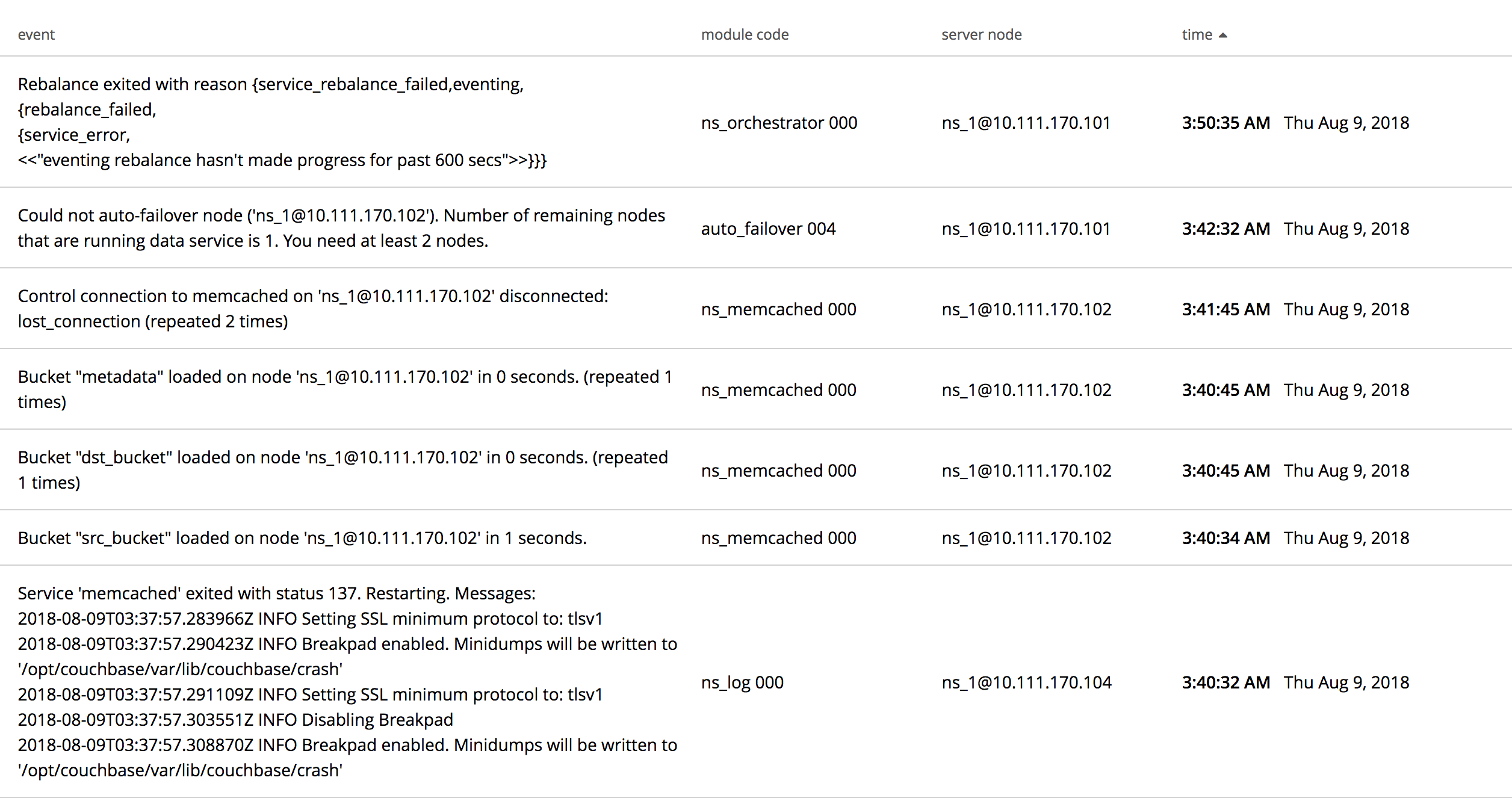
Rebalance hangs. Logs attached.
Cluster details
172.23.107.67 - kv
172.23.108.91 - kv
172.23.109.137 - eventing
172.23.109.152 - eventing
172.23.109.153 - index:n1ql
172.23.98.165 - eventing (Rebalancing in)
cbcollect_info : https://s3.amazonaws.com/bugdb/jira/memcache_crash_hang/test_24.zip
Attachments
Issue Links
| For Gerrit Dashboard: MB-29271 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 97500,4 | MB-29271 Bail out Eventing rebalance if it's struck for 600s | unstable | eventing | Status: MERGED | +2 | +1 |