Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
5.5.0
-
Triaged
-
No
-
KV-Engine MH 2nd Beta
Description
This issue has been observed while trying to reproduce the issue in MB-30017.
Test at http://perf.jenkins.couchbase.com/job/oceanus/565 (build 5.5.0-2814).
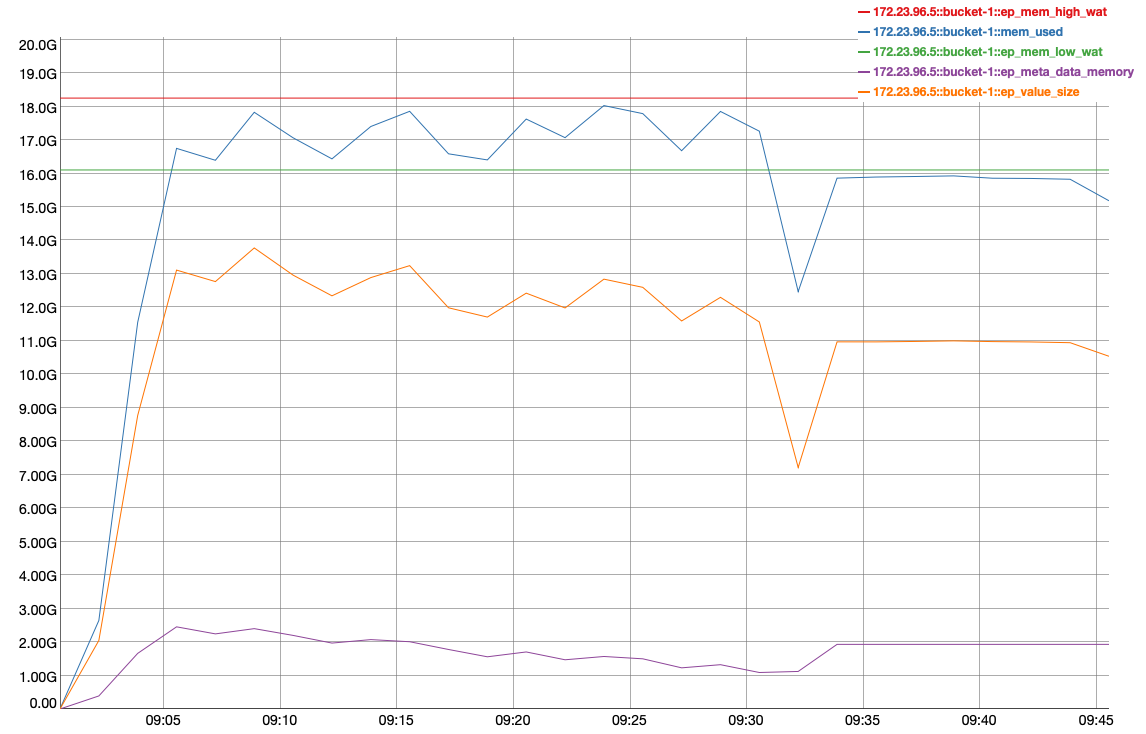
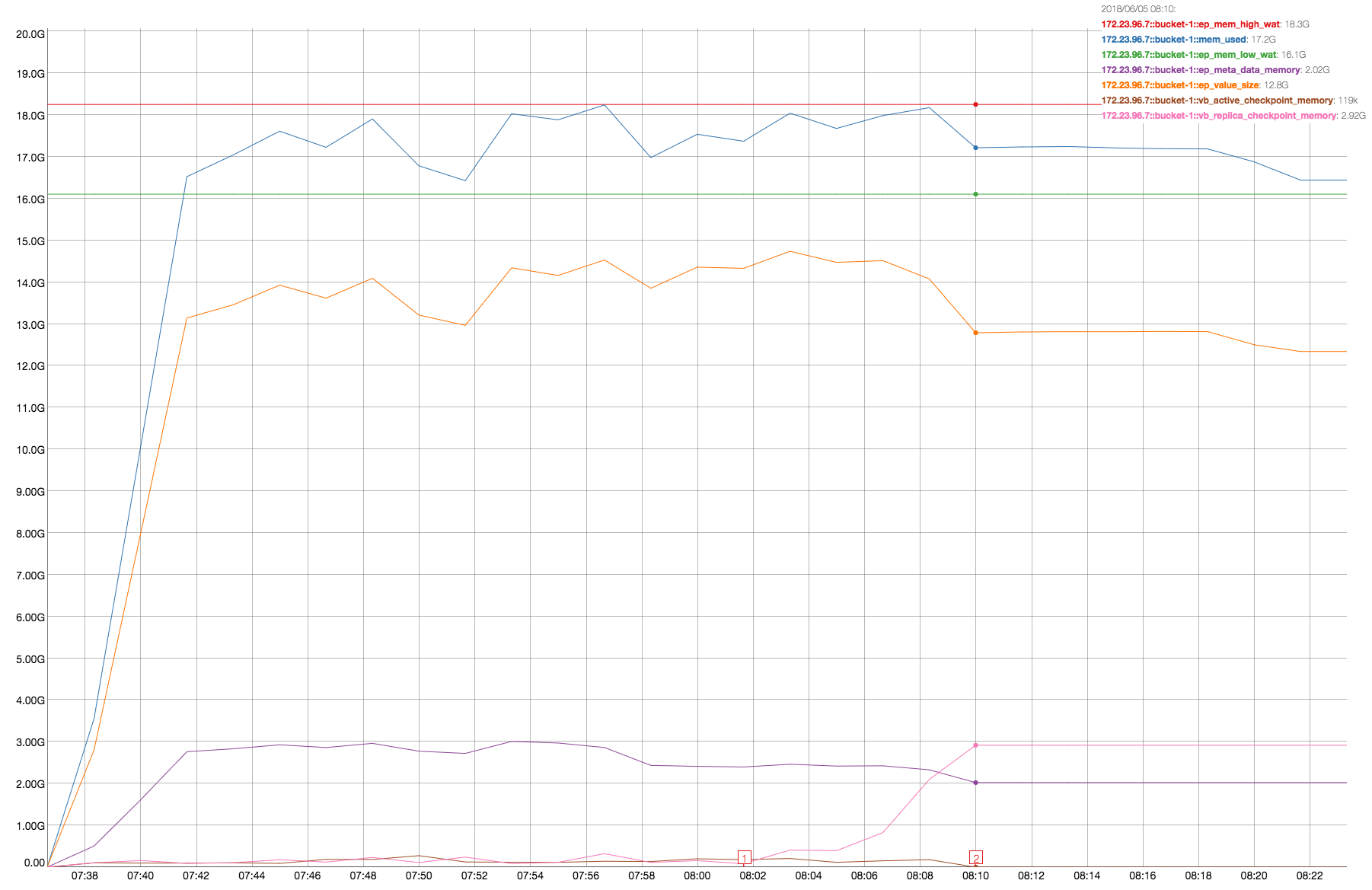
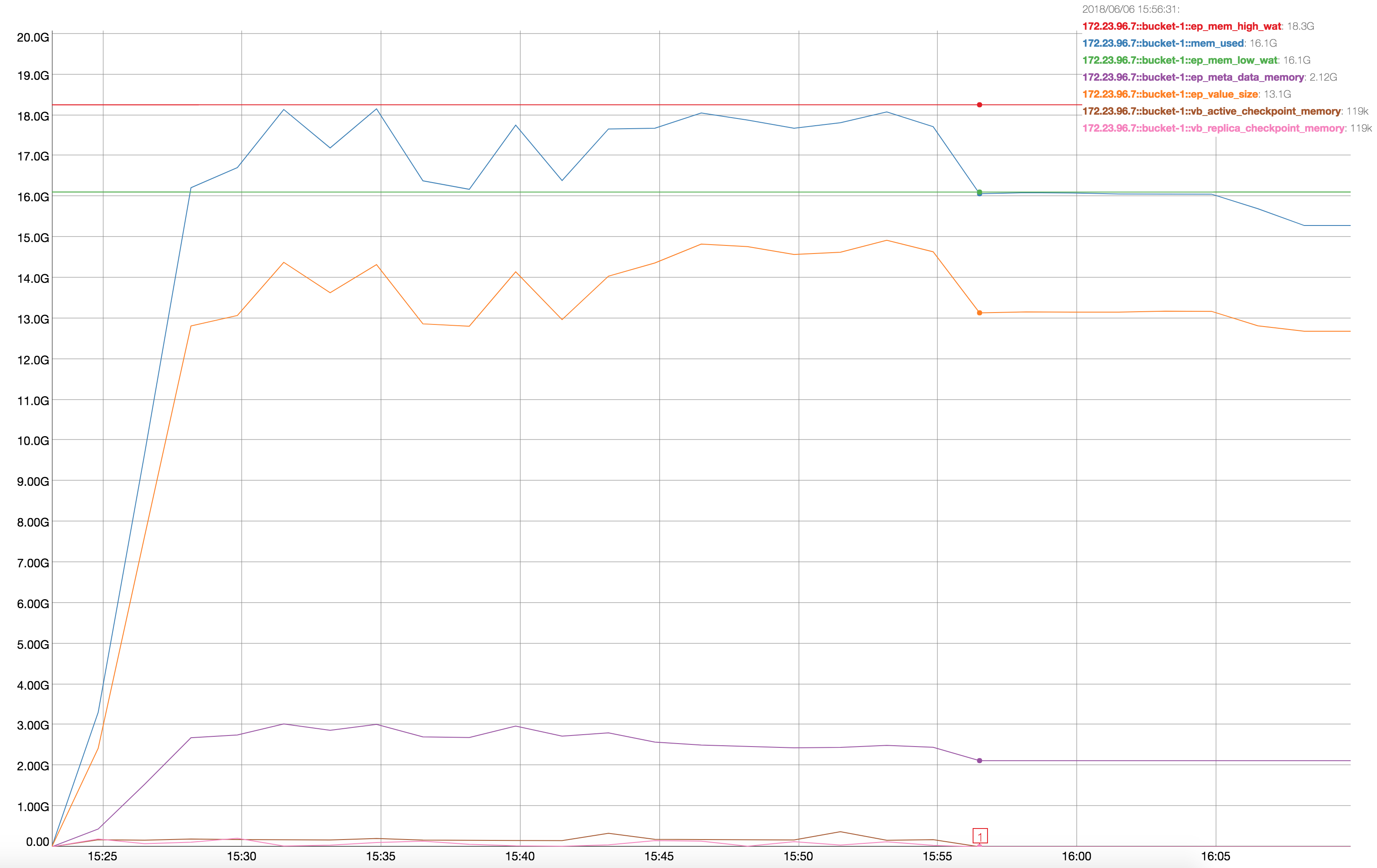
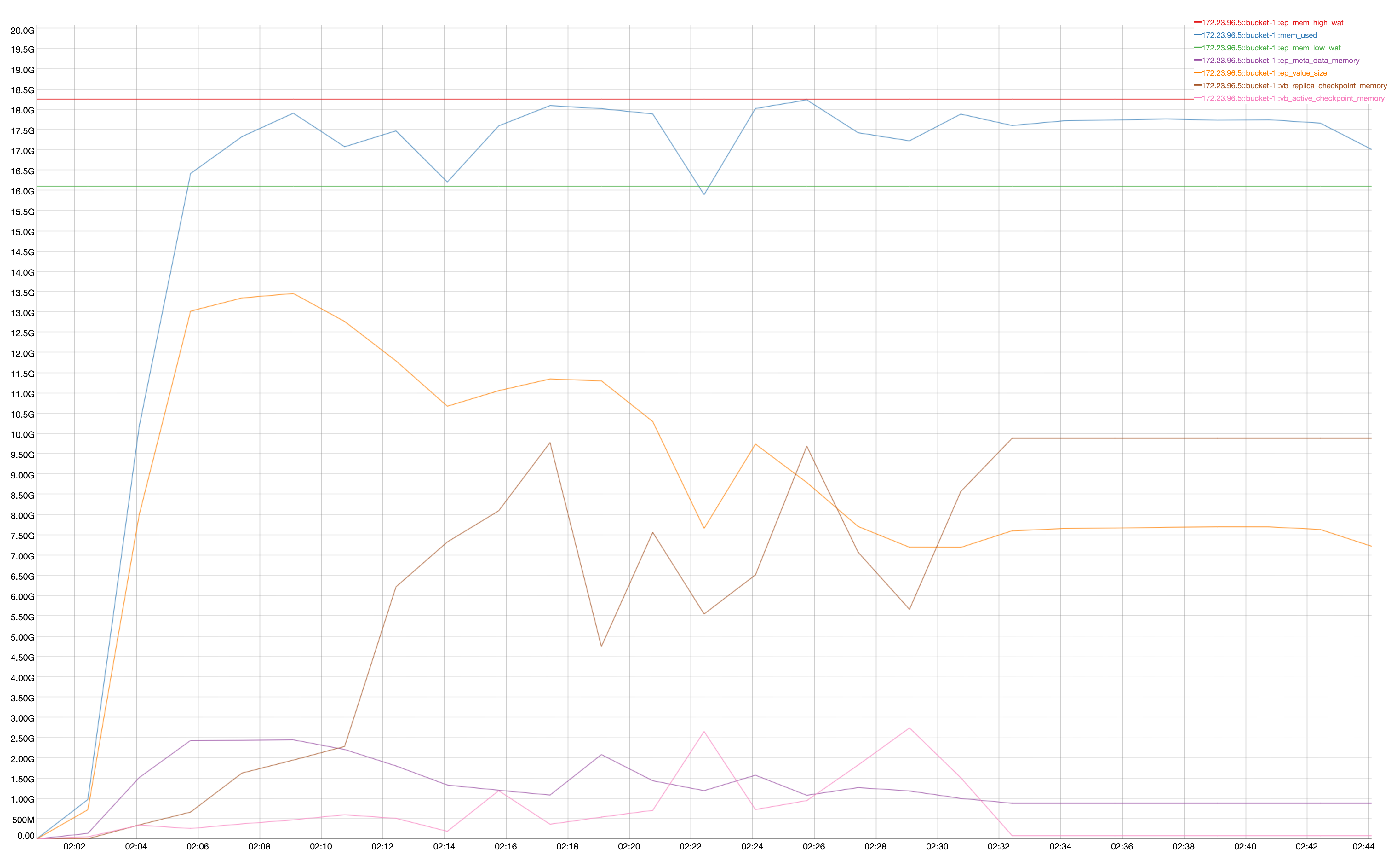
We see that vb_replica_checkpoint_memory increases and never recover at the end of . It is on both node .5 and .7, but on node .7 is more evident:
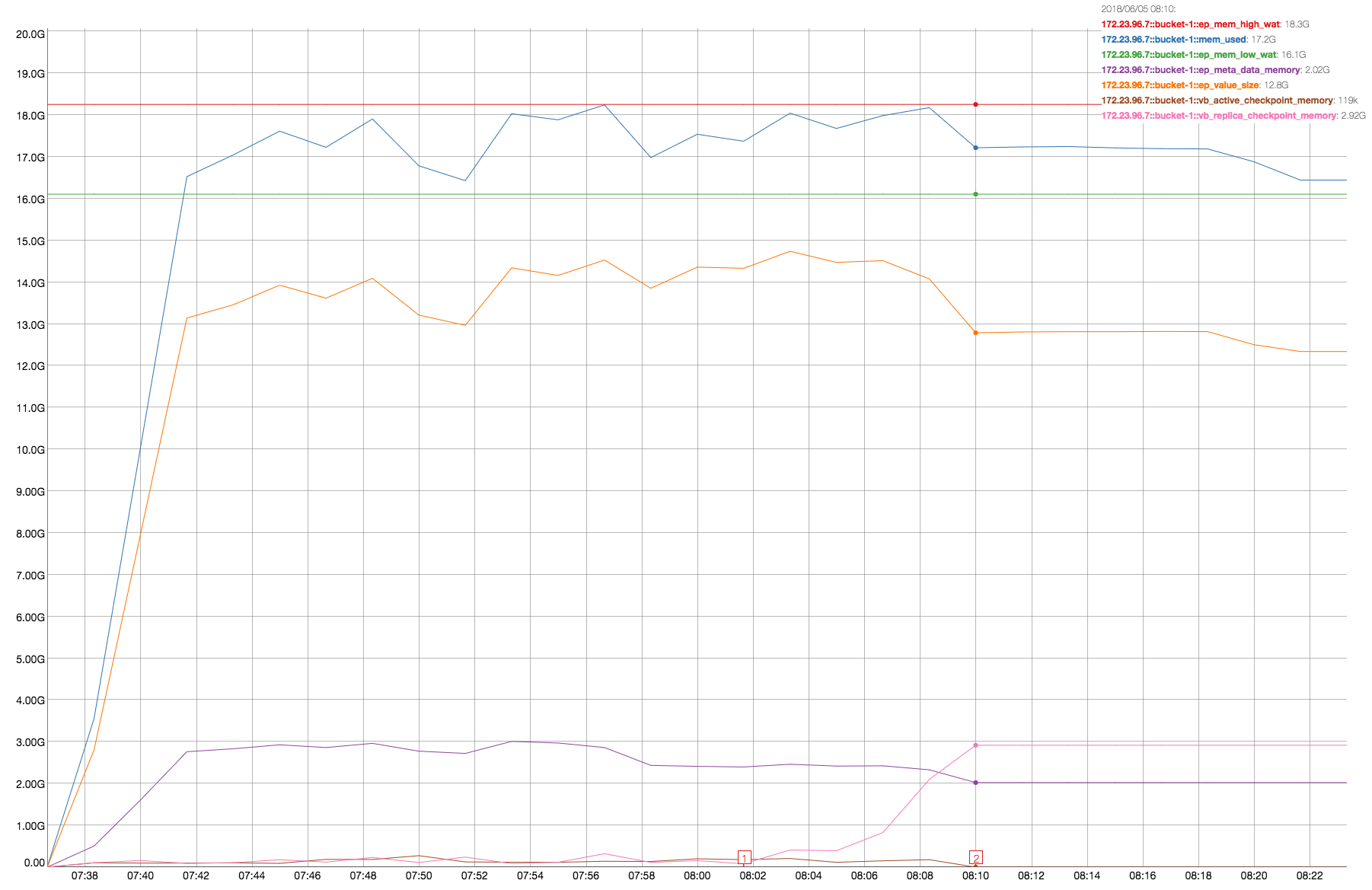
At the end of data load (from Marker-1 to Marker-2) vb_replica_checkpoint_memory increases from ~80MB to ~3GB. The resident-ratio (active/replica %) decreases from 14/12 to 8/8.
This time we have stats. Note that on node .7 we have active-vbucket:[512, 1023] and replica-vbucket:[0, 511] :
Paolos-MacBook-Pro:cbcollect_info_ns_1@172.23.96.7_20180605-152143 paoloc$ grep "vb_.*mem_usage" stats.log | cut -d '_' -f 2,3 | cut -d ':' -f 1,2,3 | sort -n
|
0:mem_usage: 13852449
|
1:mem_usage: 796506
|
2:mem_usage: 5425972
|
3:mem_usage: 10019939
|
4:mem_usage: 14113819
|
..
|
507:mem_usage: 13833426
|
508:mem_usage: 5896141
|
509:mem_usage: 687031
|
510:mem_usage: 14660846
|
511:mem_usage: 422026
|
512:mem_usage: 233
|
513:mem_usage: 233
|
514:mem_usage: 233
|
515:mem_usage: 233
|
516:mem_usage: 233
|
..
|
1019:mem_usage: 233
|
1020:mem_usage: 233
|
1021:mem_usage: 233
|
1022:mem_usage: 233
|
1023:mem_usage: 233
|
Paolos-MacBook-Pro:cbcollect_info_ns_1@172.23.96.7_20180605-152143 paoloc$ grep "vb_.*num_checkpoint" stats.log | cut -d '_' -f 2,3,4 | cut -d ':' -f 1,2,3 | sort -n
|
0:num_checkpoint_items: 26518
|
0:num_checkpoints: 1
|
1:num_checkpoint_items: 1524
|
1:num_checkpoints: 1
|
2:num_checkpoint_items: 10385
|
2:num_checkpoints: 1
|
3:num_checkpoint_items: 19176
|
3:num_checkpoints: 1
|
4:num_checkpoint_items: 27010
|
4:num_checkpoints: 1
|
..
|
507:num_checkpoint_items: 26483
|
507:num_checkpoints: 1
|
508:num_checkpoint_items: 11287
|
508:num_checkpoints: 1
|
509:num_checkpoint_items: 1314
|
509:num_checkpoints: 1
|
510:num_checkpoint_items: 28065
|
510:num_checkpoints: 1
|
511:num_checkpoint_items: 809
|
511:num_checkpoints: 1
|
512:num_checkpoint_items: 1
|
512:num_checkpoints: 1
|
513:num_checkpoint_items: 1
|
513:num_checkpoints: 1
|
514:num_checkpoint_items: 1
|
514:num_checkpoints: 1
|
515:num_checkpoint_items: 1
|
515:num_checkpoints: 1
|
516:num_checkpoint_items: 1
|
516:num_checkpoints: 1
|
..
|
1019:num_checkpoint_items: 1
|
1019:num_checkpoints: 1
|
1020:num_checkpoint_items: 1
|
1020:num_checkpoints: 1
|
1021:num_checkpoint_items: 1
|
1021:num_checkpoints: 1
|
1022:num_checkpoint_items: 1
|
1022:num_checkpoints: 1
|
1023:num_checkpoint_items: 1
|
1023:num_checkpoints: 1
|
Also, note that we have all in-memory streams. From node .5:
eq_dcpq:replication:ns_1@172.23.96.5->ns_1@172.23.96.7:bucket-1:stream_0_state: in-memory
|
eq_dcpq:replication:ns_1@172.23.96.5->ns_1@172.23.96.7:bucket-1:stream_100_state: in-memory
|
eq_dcpq:replication:ns_1@172.23.96.5->ns_1@172.23.96.7:bucket-1:stream_101_state: in-memory
|
eq_dcpq:replication:ns_1@172.23.96.5->ns_1@172.23.96.7:bucket-1:stream_102_state: in-memory
|
eq_dcpq:replication:ns_1@172.23.96.5->ns_1@172.23.96.7:bucket-1:stream_103_state: in-memory
|
..
|
So, on replica vbuckets on node .7 we have many cases of:
- num_checkpoint_items > chk_max_items
- num_checkpoints < max_checkpoints
The reason is that we don't enforce the chk_max_items limit on replica-vbuckets.
In general, for a replica-vbucket we close the current open checkpoint (and then deallocating memory) in two cases:
- when the Consumer receives snapshot_marker (it is the snapshot-start message sent by the Producer)
- when the Consumer receives the snapshot-end mutation
Looking at the code. PassiveStream::processMarker() (http://src.couchbase.org/source/xref/vulcan/kv_engine/engines/ep/src/dcp/stream.cc#2673):
2673 void PassiveStream::processMarker(SnapshotMarker* marker) {
|
2674 VBucketPtr vb = engine->getVBucket(vb_);
|
2675
|
2676 cur_snapshot_start.store(marker->getStartSeqno());
|
2677 cur_snapshot_end.store(marker->getEndSeqno());
|
2678 cur_snapshot_type.store((marker->getFlags() & MARKER_FLAG_DISK) ?
|
2679 Snapshot::Disk : Snapshot::Memory);
|
2680
|
2681 if (vb) {
|
2682 auto& ckptMgr = *vb->checkpointManager;
|
2683 if (marker->getFlags() & MARKER_FLAG_DISK && vb->getHighSeqno() == 0) {
|
2684 vb->setBackfillPhase(true);
|
2685 // calling setBackfillPhase sets the openCheckpointId to zero.
|
2686 ckptMgr.setBackfillPhase(cur_snapshot_start.load(),
|
2687 cur_snapshot_end.load());
|
2688 } else {
|
2689 if (marker->getFlags() & MARKER_FLAG_CHK ||
|
2690 vb->checkpointManager->getOpenCheckpointId() == 0) {
|
2691 ckptMgr.createSnapshot(cur_snapshot_start.load(),
|
2692 cur_snapshot_end.load());
|
2693 } else {
|
2694 ckptMgr.updateCurrentSnapshotEnd(cur_snapshot_end.load());
|
2695 }
|
2696 vb->setBackfillPhase(false);
|
..
|
We close the open checkpoint for memory-snapshot at line 2691 when we call CheckpointManager::createSnapshot()).
Looking at the code for PassiveStream::handleSnapshotEnd() (http://src.couchbase.org/source/xref/vulcan/kv_engine/engines/ep/src/dcp/stream.cc#2715):
2715 void PassiveStream::handleSnapshotEnd(VBucketPtr& vb, uint64_t byseqno) {
|
2716 if (byseqno == cur_snapshot_end.load()) {
|
2717 auto& ckptMgr = *vb->checkpointManager;
|
2718 if (cur_snapshot_type.load() == Snapshot::Disk &&
|
2719 vb->isBackfillPhase()) {
|
2720 vb->setBackfillPhase(false);
|
2721 const auto id = ckptMgr.getOpenCheckpointId() + 1;
|
2722 ckptMgr.checkAndAddNewCheckpoint(id, *vb);
|
2723 } else {
|
2724 size_t mem_threshold = engine->getEpStats().mem_high_wat.load();
|
2725 size_t mem_used =
|
2726 engine->getEpStats().getEstimatedTotalMemoryUsed();
|
2727 /* We want to add a new replica checkpoint if the mem usage is above
|
2728 high watermark (85%) */
|
2729 if (mem_threshold < mem_used) {
|
2730 const auto id = ckptMgr.getOpenCheckpointId() + 1;
|
2731 ckptMgr.checkAndAddNewCheckpoint(id, *vb);
|
2732 }
|
..
|
We close the open checkpoint for memory-snapshot at line 2731 when we call CheckpointManager::checkAndAddNewCheckpoint()), but only if mem_used > mem_threshold, which is not the case on charts above.
So, we have a situation where (for memory-snapshots):
- we close the open checkpoint only when we receive a snapshot-start
- so, we don't close the open checkpoint (and we don't deallocate memory) after we have received the last snapshot (as there is no new snapshot-start) if mem_used < mem_threshold.
Attachments
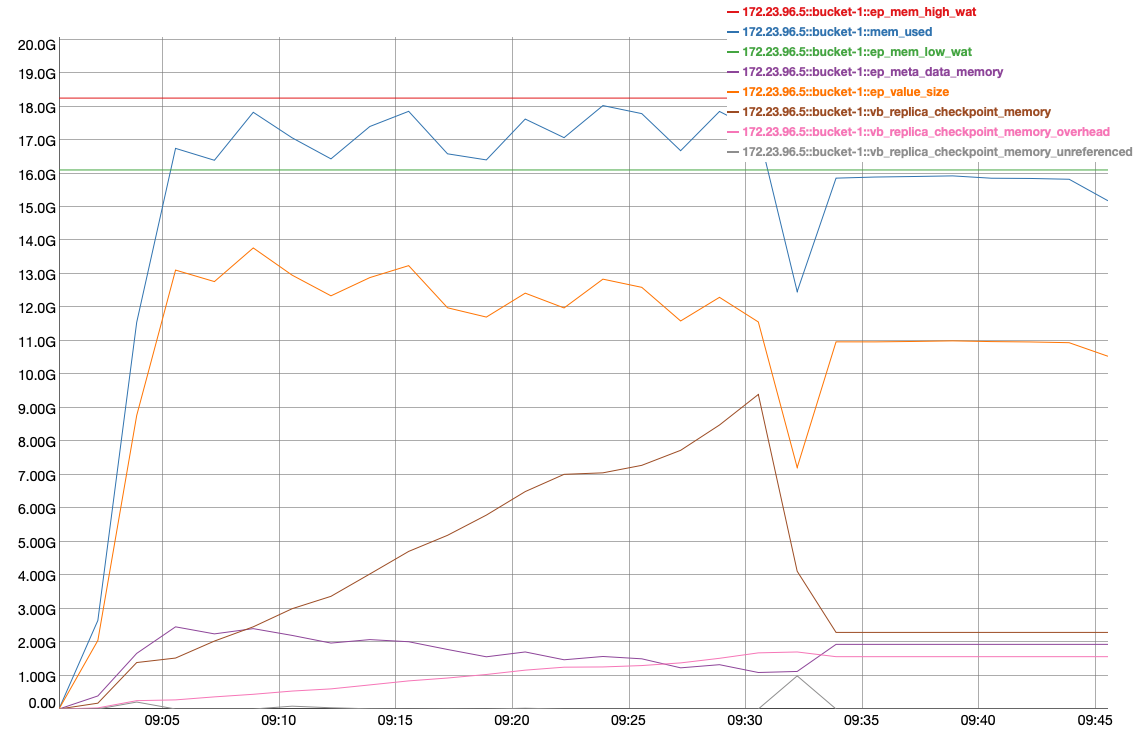
Issue Links
| For Gerrit Dashboard: MB-30019 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 97015,3 | MB-30019: Always close replica-checkpoint at snapshot-end | master | kv_engine | Status: NEW | -1 | -1 |