Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
5.5.0
-
Untriaged
-
-
Unknown
Description
Build : 5.5.0-2884
Test : GSI component test : -test tests/2i/test_idx_rebalance_replica_vulcan_kv_opt.yml -scope tests/2i/scope_idx_rebalance_replica_vulcan.yml
Scale : 3
Iteration : 3rd iteration (~20 hrs of run)
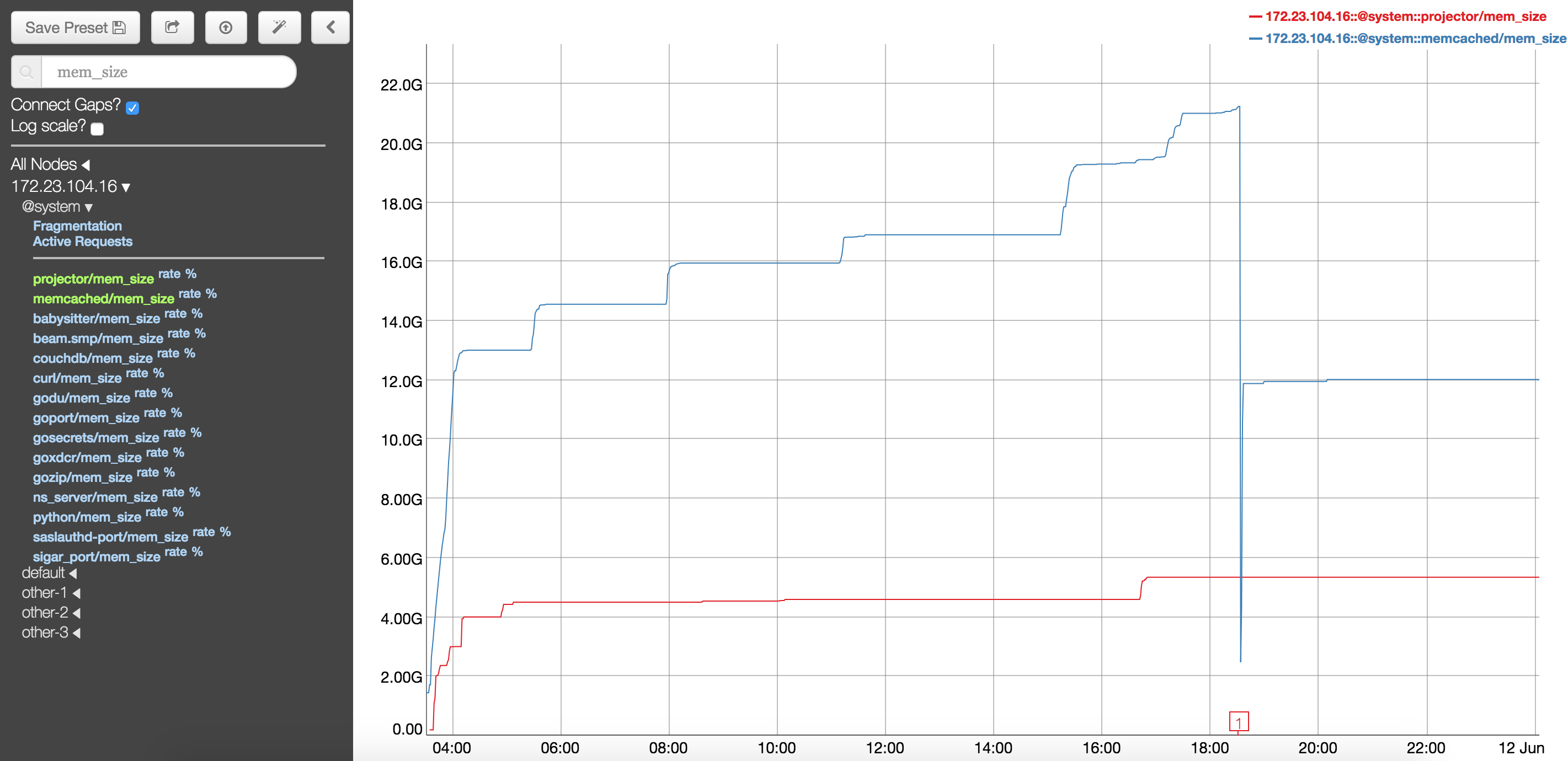
In the 3rd iteration, the step in the test to rebalance out a KV node fails when memcached crashes on the master node. The cluster becomes pretty unusable after this. The subsequent rebalance has got stuck (see MB-30073), the buckets are in warmup state forever
The following error is shown on the diag log:
Service 'memcached' exited with status 137. Restarting. Messages:
|
2018-06-11T18:33:16.430335Z WARNING 106: Slow operation. {"cid":"172.23.106.161:40160/81905100","duration":"4193 ms","trace":"request=10723899535396330:4193337","command":"GET","peer":"172.23.106.161:40160"}
|
2018-06-11T18:33:16.433047Z WARNING 110: Slow operation. {"cid":"172.23.106.161:40210/31c25100","duration":"4205 ms","trace":"request=10723899526306866:4205138","command":"GET","peer":"172.23.106.161:40210"}
|
2018-06-11T18:33:16.433697Z WARNING (other-3) Slow runtime for 'Running a flusher loop: shard 2' on thread writer_worker_0: 4198 ms
|
2018-06-11T18:33:16.521086Z WARNING (other-1) Slow runtime for 'Checkpoint Remover on vb 213' on thread nonIO_worker_1: 20 ms
|
2018-06-11T18:33:16.581773Z WARNING (other-2) Slow runtime for 'Checkpoint Remover on vb 498' on thread nonIO_worker_0: 33 ms
|
2018-06-11T18:33:17.253240Z WARNING (other-2) Slow runtime for 'Backfilling items for a DCP Connection' on thread auxIO_worker_0: 346 ms
|
2018-06-11T18:33:18.229913Z WARNING (default) Slow runtime for 'Backfilling items for a DCP Connection' on thread auxIO_worker_0: 623 ms
|
2018-06-11T18:33:19.469135Z WARNING (other-1) Slow runtime for 'Checkpoint Remover on vb 339' on thread nonIO_worker_0: 20 ms
|
Following is seen in the debug log:
[error_logger:error,2018-06-11T18:33:24.935-07:00,ns_1@172.23.104.16:error_logger<0.6.0>:ale_error_logger_handler:do_log:203]
|
=========================CRASH REPORT=========================
|
crasher:
|
initial call: erlang:apply/2
|
pid: <0.12839.0>
|
registered_name: []
|
exception error: no match of right hand side value {error,closed}
|
in function mc_client_binary:stats_recv/4 (src/mc_client_binary.erl, line 164)
|
in call from mc_client_binary:stats/4 (src/mc_client_binary.erl, line 406)
|
in call from ns_memcached:do_handle_call/3 (src/ns_memcached.erl, line 460)
|
in call from ns_memcached:worker_loop/3 (src/ns_memcached.erl, line 228)
|
ancestors: ['ns_memcached-default',<0.12824.0>,
|
'single_bucket_kv_sup-default',ns_bucket_sup,
|
ns_bucket_worker_sup,ns_server_sup,ns_server_nodes_sup,
|
<0.170.0>,ns_server_cluster_sup,<0.89.0>]
|
messages: []
|
links: [<0.12825.0>,#Port<0.9577>]
|
dictionary: [{last_call,verify_warmup},{sockname,{{127,0,0,1},51713}}]
|
trap_exit: false
|
status: running
|
heap_size: 6772
|
stack_size: 27
|
reductions: 241838516
|
neighbours:
|
|