Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
5.5.0
-
None
-
Untriaged
-
Ubuntu 64-bit
-
Unknown
Description
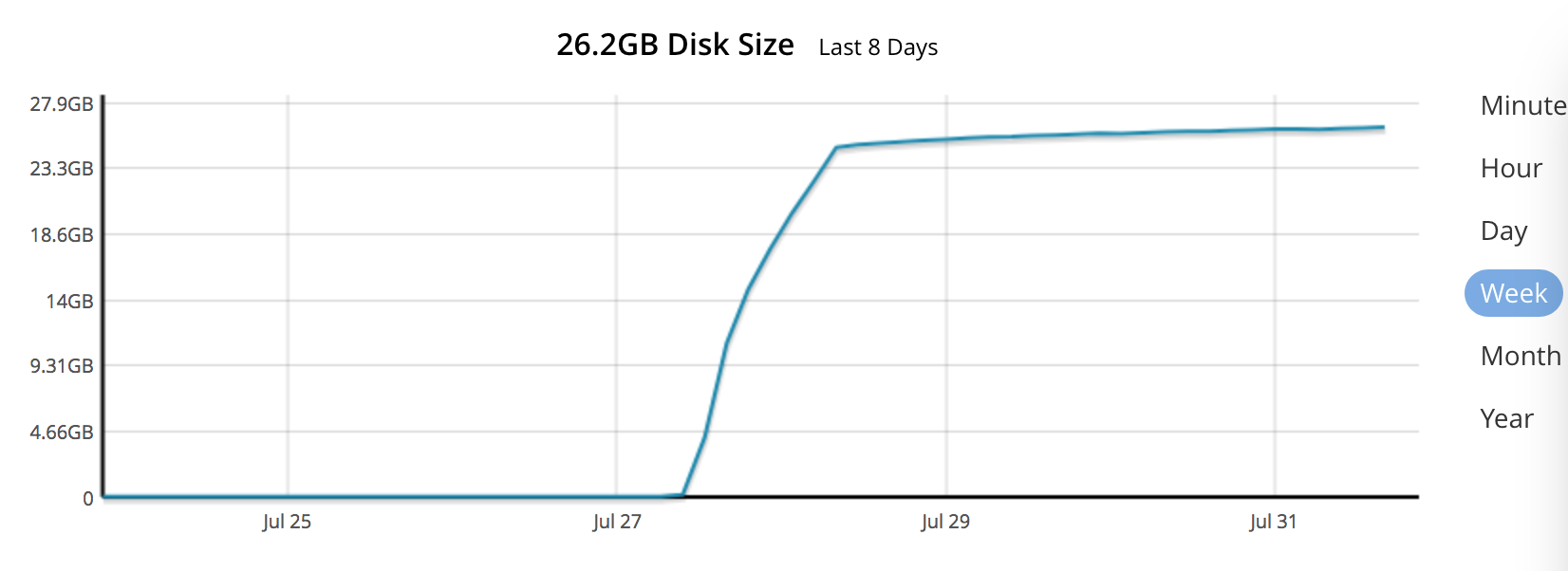
Noticed this on our perflab (http://172.23.121.90:8091/) cluster which is storage for all performance results and backend database for the ShowFast.
Looks like it happened after upgrade from 5.1 to 5.5 but I don't know for sure.
At some point some random indexes started growing in size until it take whole disk space and node starts throwing disk errors. Amount of documents didn't change.
cbcollect from one of the nodes:
scp root@172.23.104.212:/root/index_grows.zip index_grows.zip
I've also copied index folder there:
scp -r root@172.23.104.212:/root/mainIndex ..
There were two indexes "in trouble" on that node:
weekly_weekly_by_build
clusters_clusters_by_name
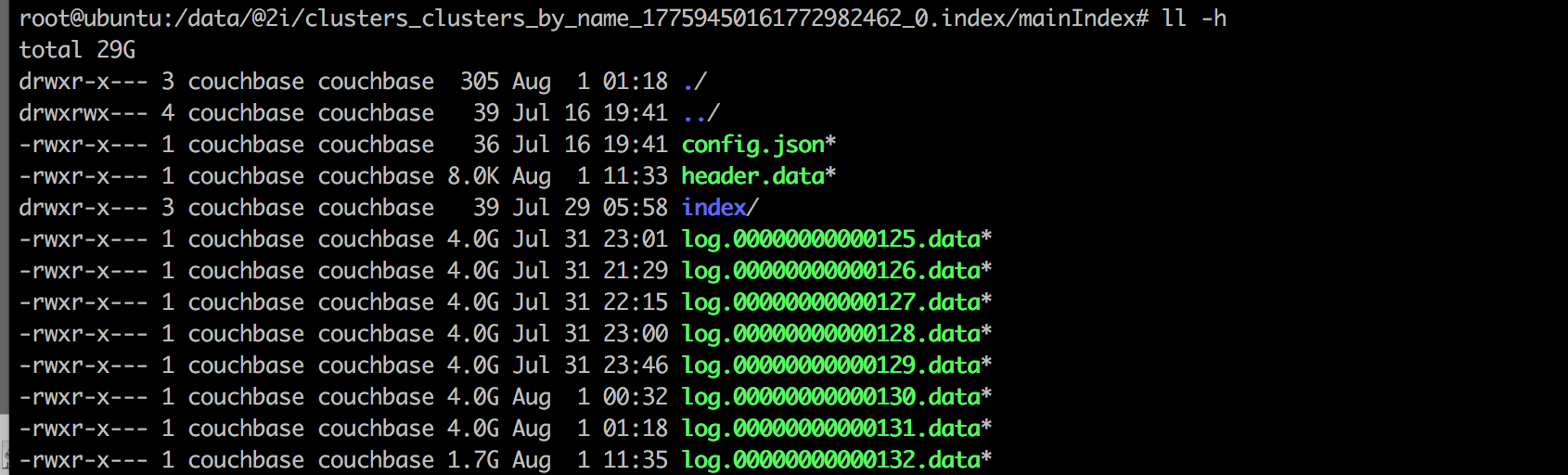
Here is what's taking space:

Attachments

Issue Links
- relates to
-
-
- Closed
-