Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
6.0.0
-
fts perf. cluster
-
Untriaged
-
Centos 64-bit
-
No
-
FTS Sprint Nov-23-2018
Description
.. and also weird behavior.
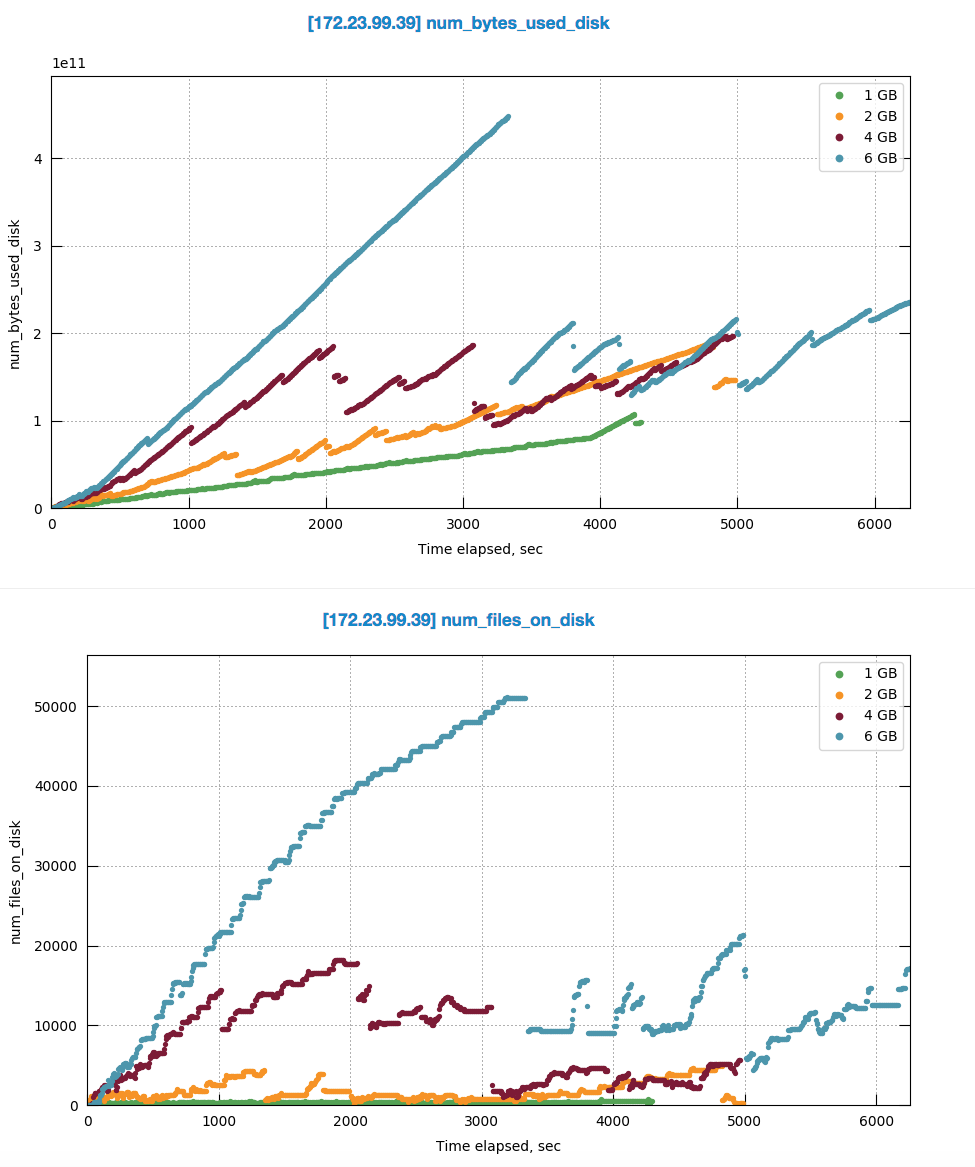
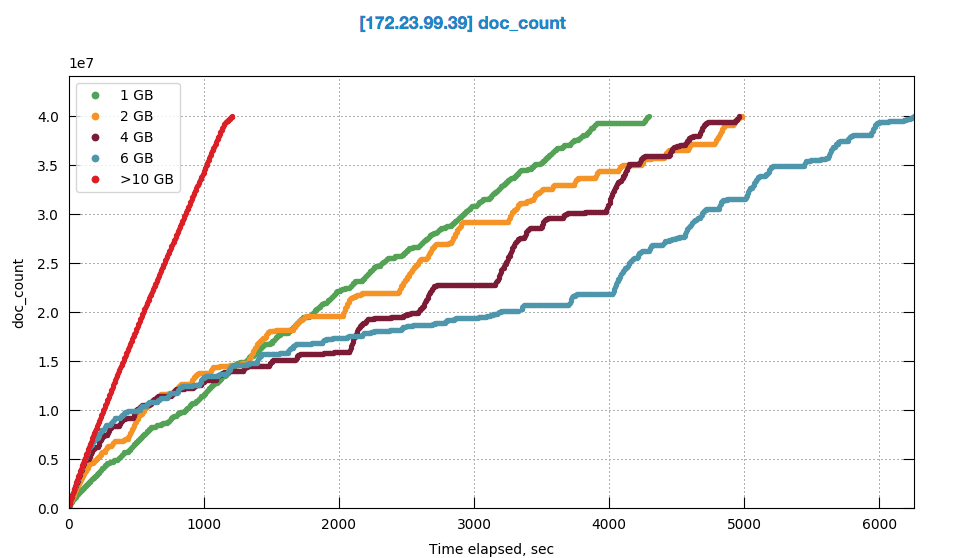
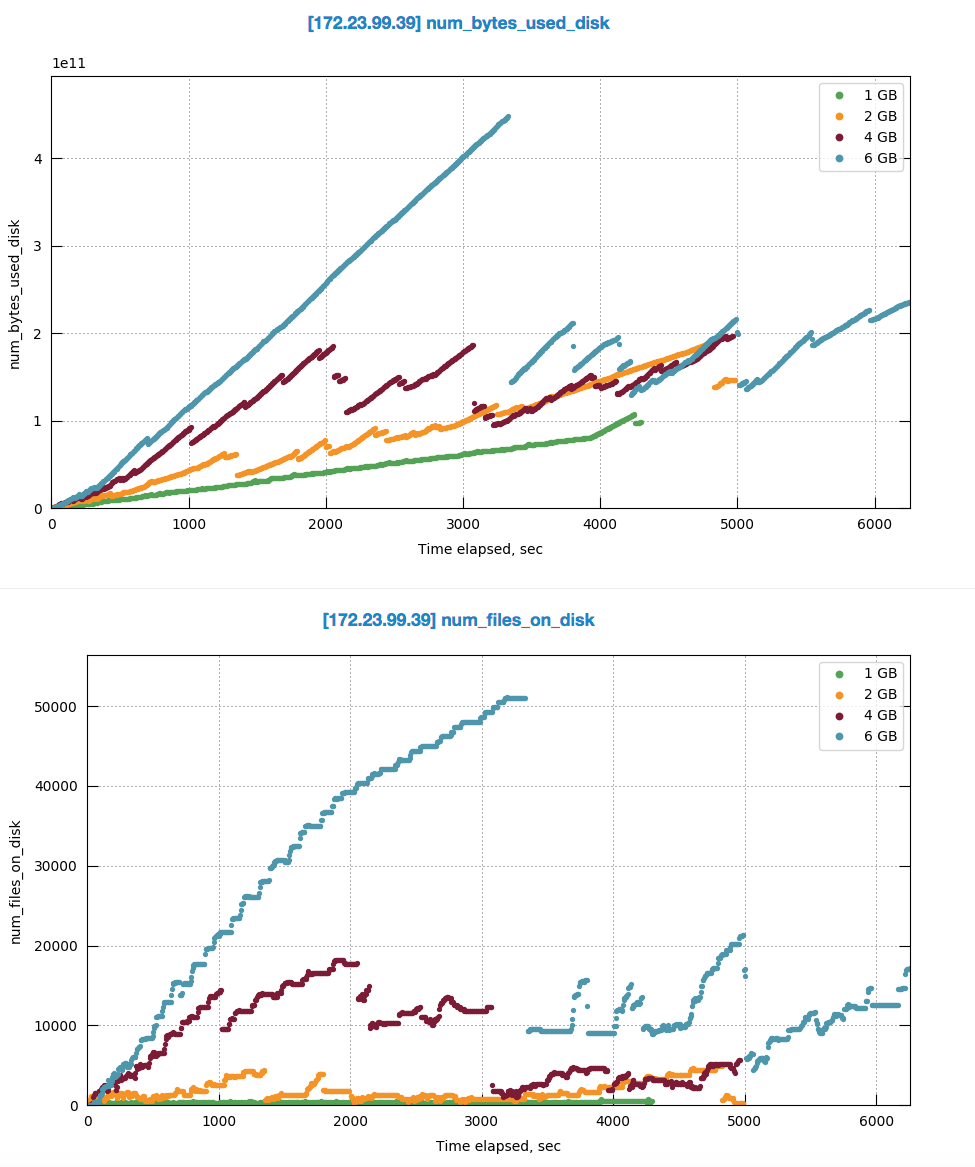
The test: Initial indexing fo 40M dataset, single FTS node, 32GB RAM, various quotas.
First run was with very high FTS quota to measure the max RAM fts would use when initial indexing.
The experiment shows that on single FTS node, to support its maximum indexing throughput of 40 MB/sec the fts uses 10GB of RAM
Having that in mind, I ran few tests with quota lower that 10GB considering that tests as "DGM" kind of scenarios.
The behavior is: the higher the quota within those 10GB the slower the indexing and the more disk space it uses.
First, the indexing duration:
Once we get into DGM, the indexing throughput drops 4-5 times. And the higher the quota the slower it gets:
| Quota, GB | duration, sec |
| >10 GB | 1219 |
| 1 | 4301 |
| 2 | 4991 |
| 4 | 4971 |
| 6 | 6266 |
| 8 | 5498 |
Same is with disk size, but even on larger scale:
| Quota, GB | max disk usage, GB |
| >10 GB | 112 |
| 1 | 103 |
| 2 | 177 |
| 4 | 178 |
| 6 | 423 |
| 8 | 347 |
Here is comparison of disk usage pattern with various quota sizes:
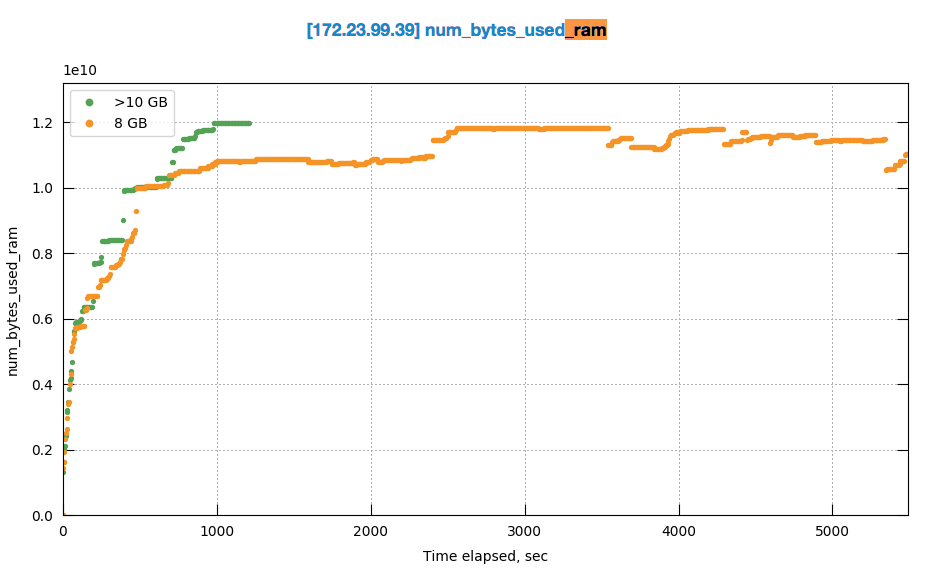
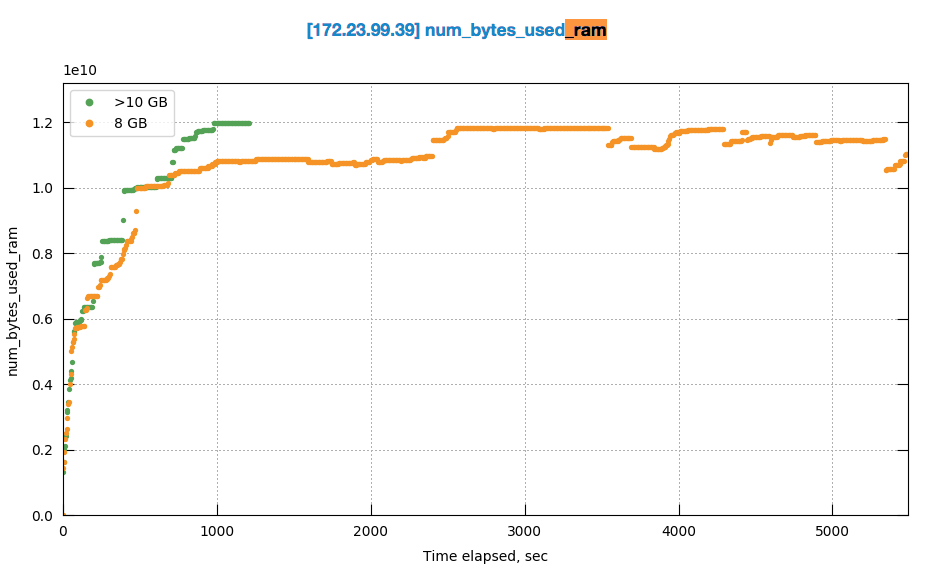
Its getting fun when comparing how system behaves with 10GB and 8GB quota assuming that we just 20% less that max required:
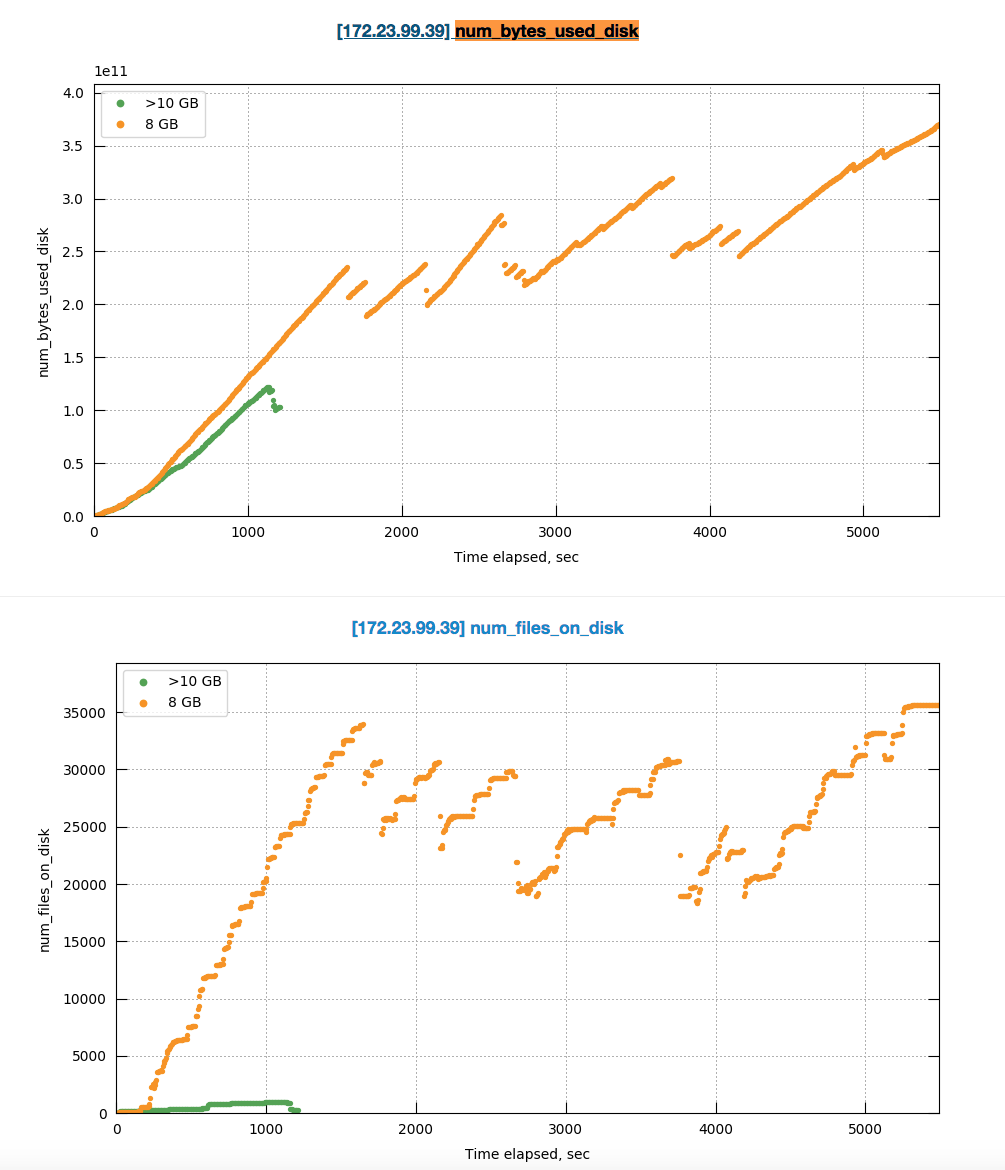
Especially because it uses the same amount of memory ![]()
Logs: