Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
6.5.0
-
Build : 6.0.0-1529
-
Untriaged
-
Unknown
Description
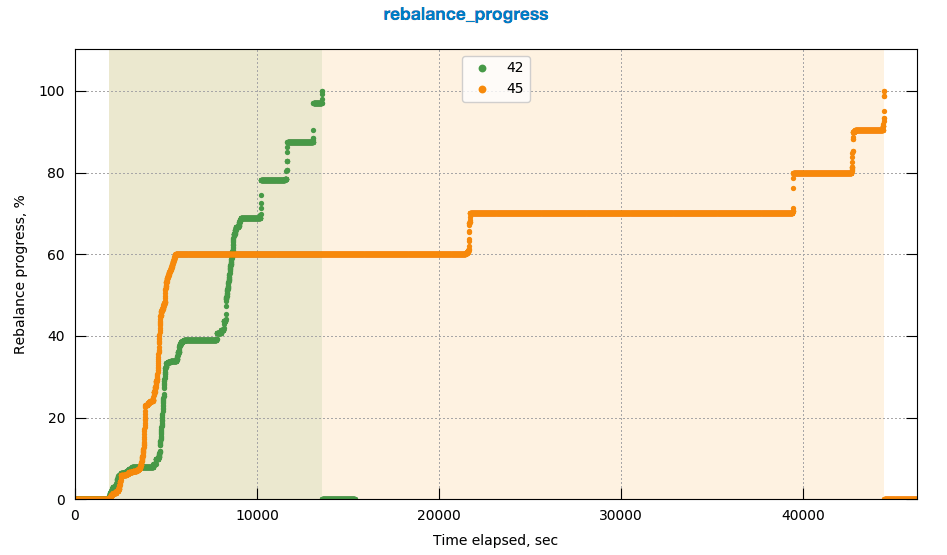
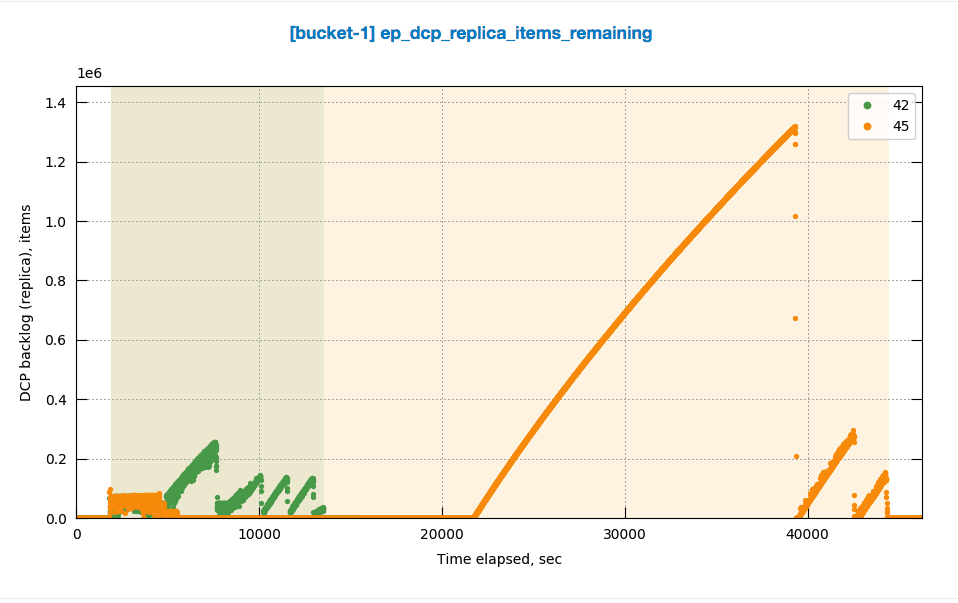
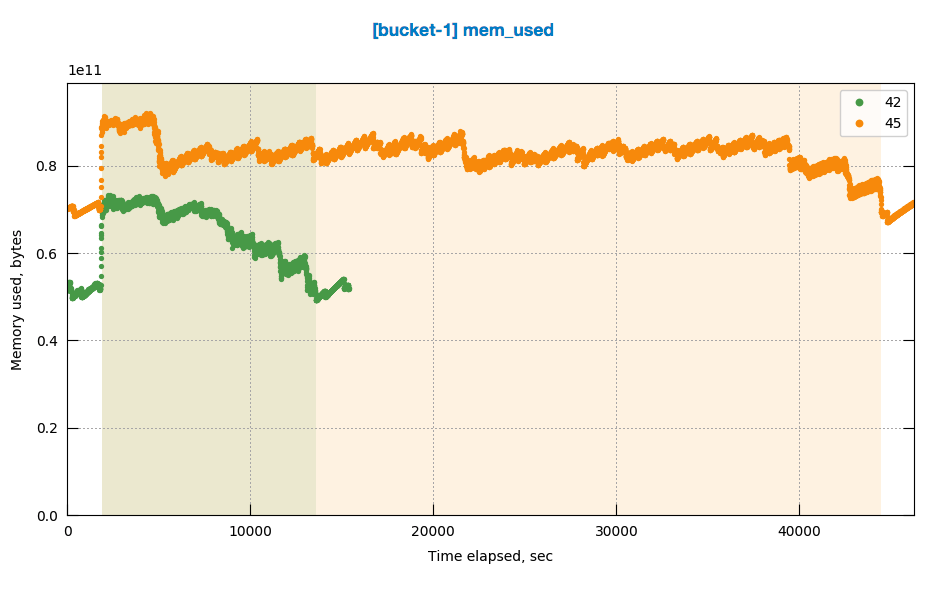
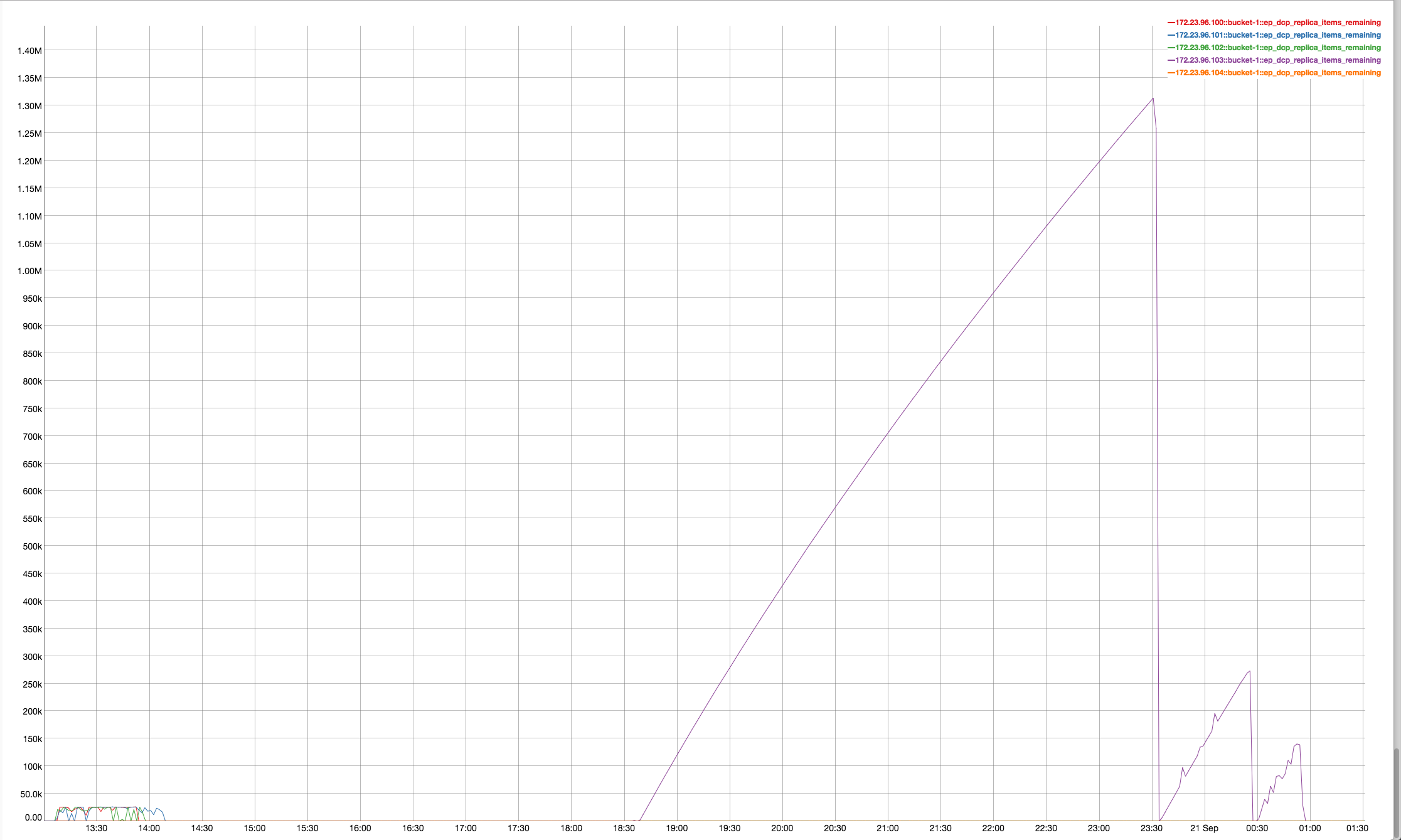
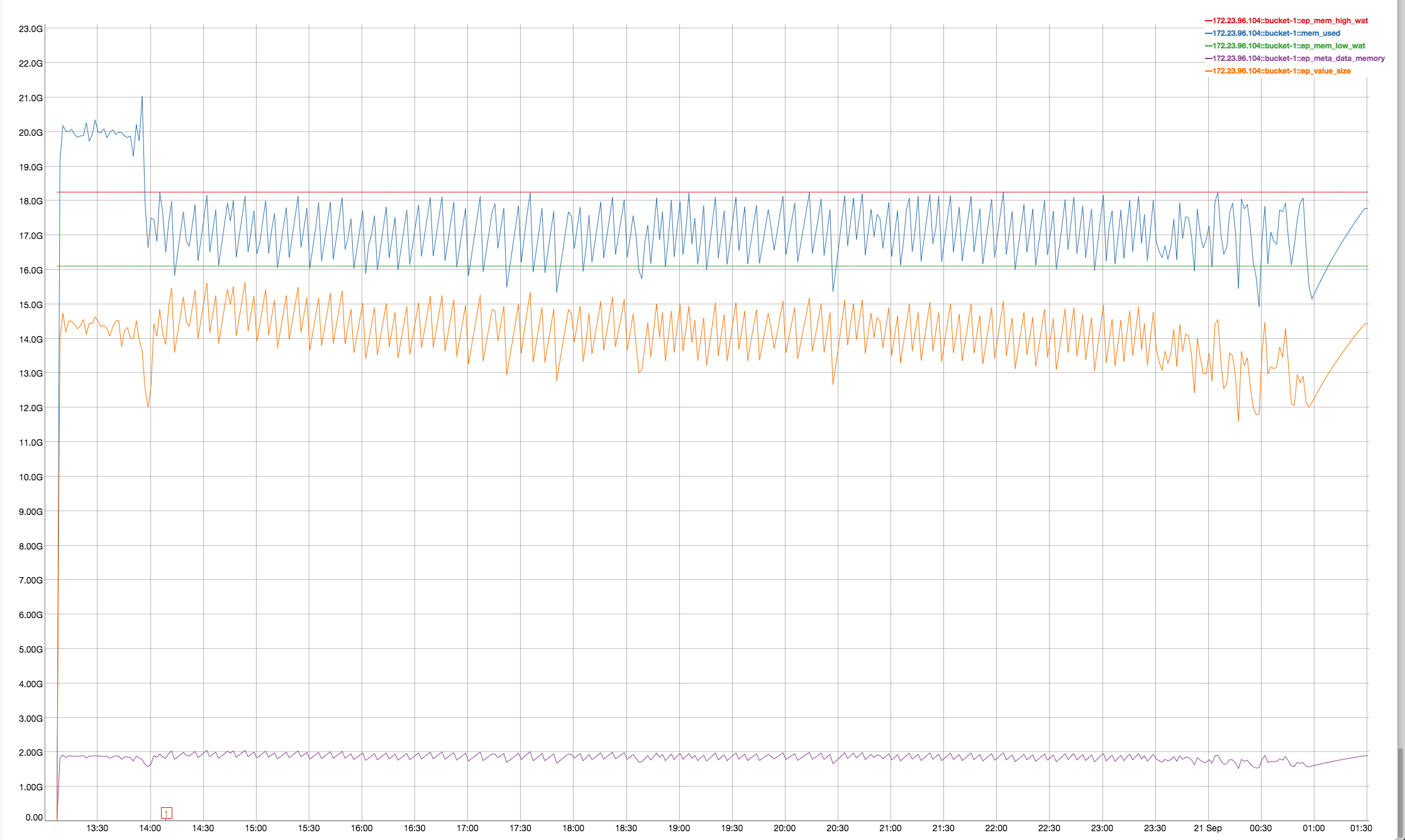
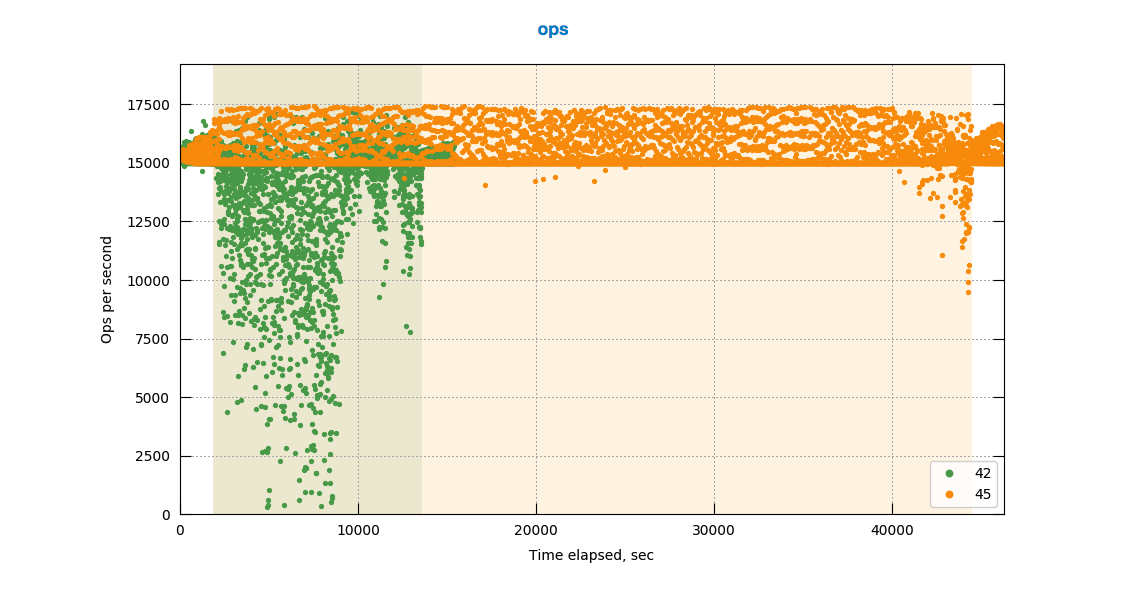
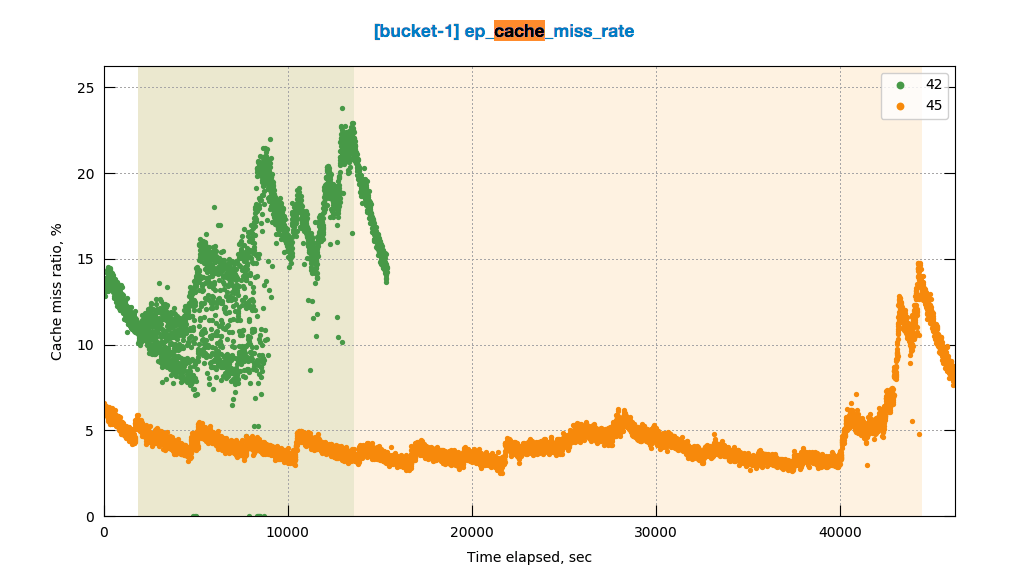
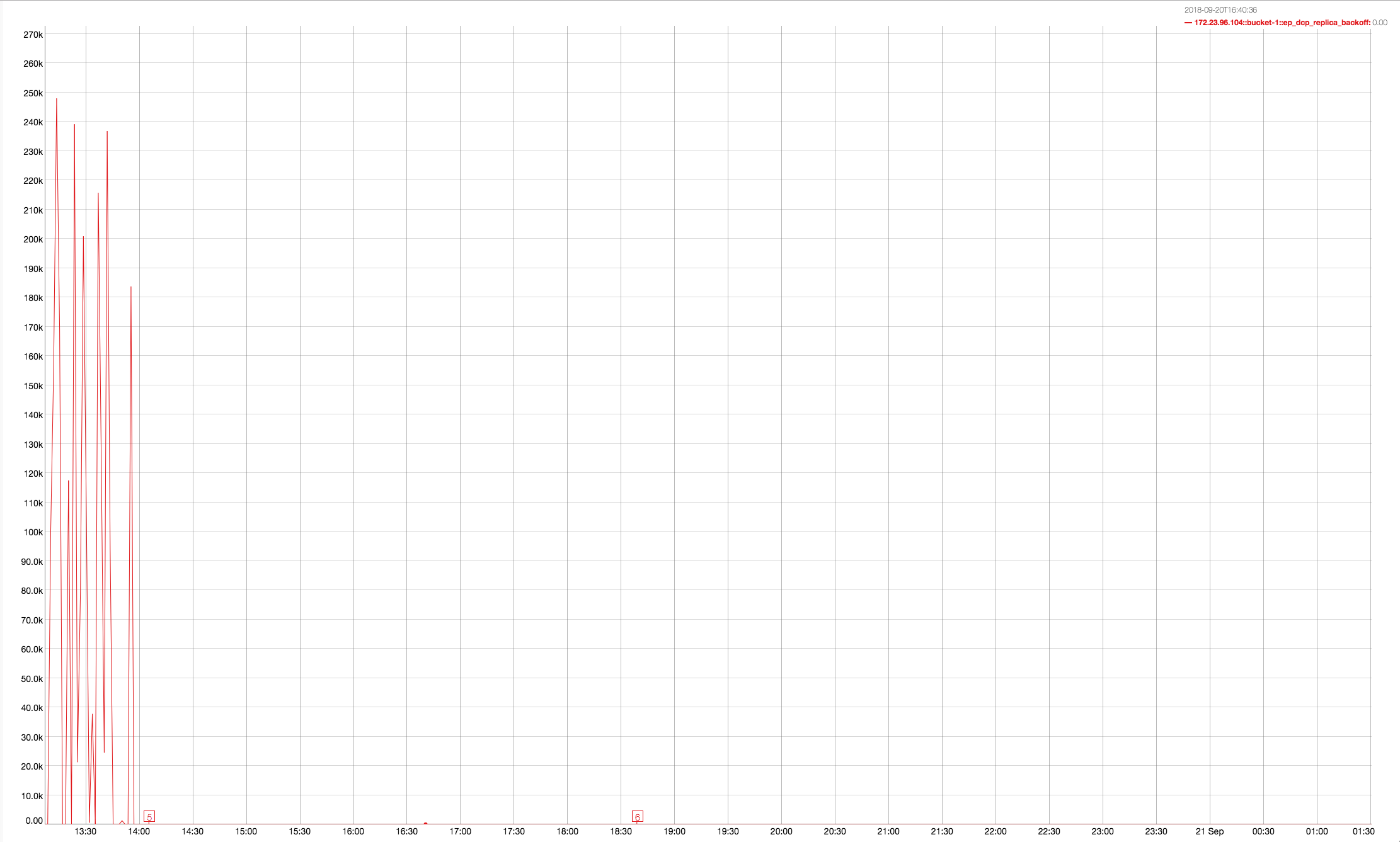
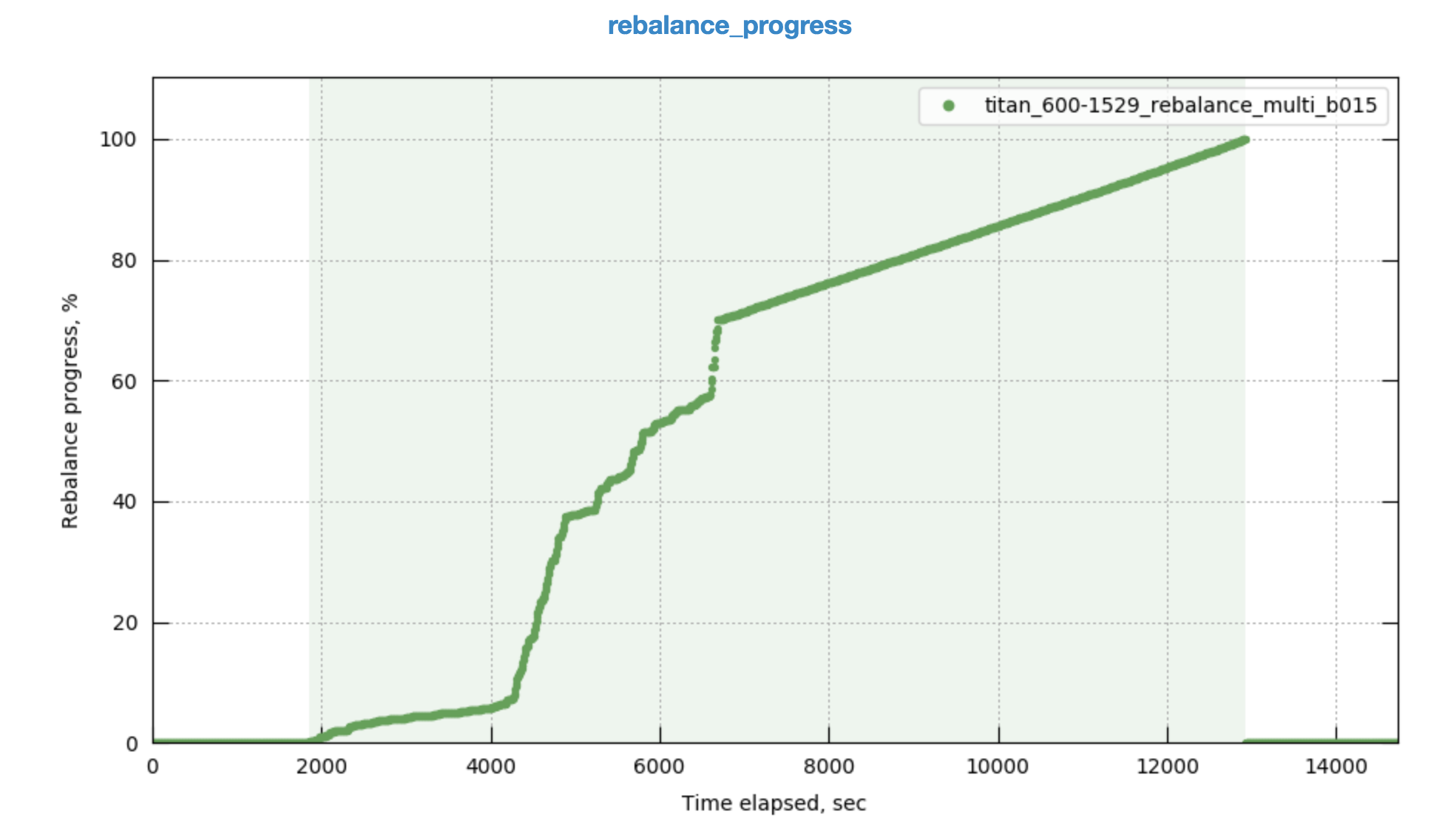
Observing high rebalance time up-to 10hrs when multiple rebalances (in, out , swap) are made on same 4 node cluster with continuous ops running on the cluster
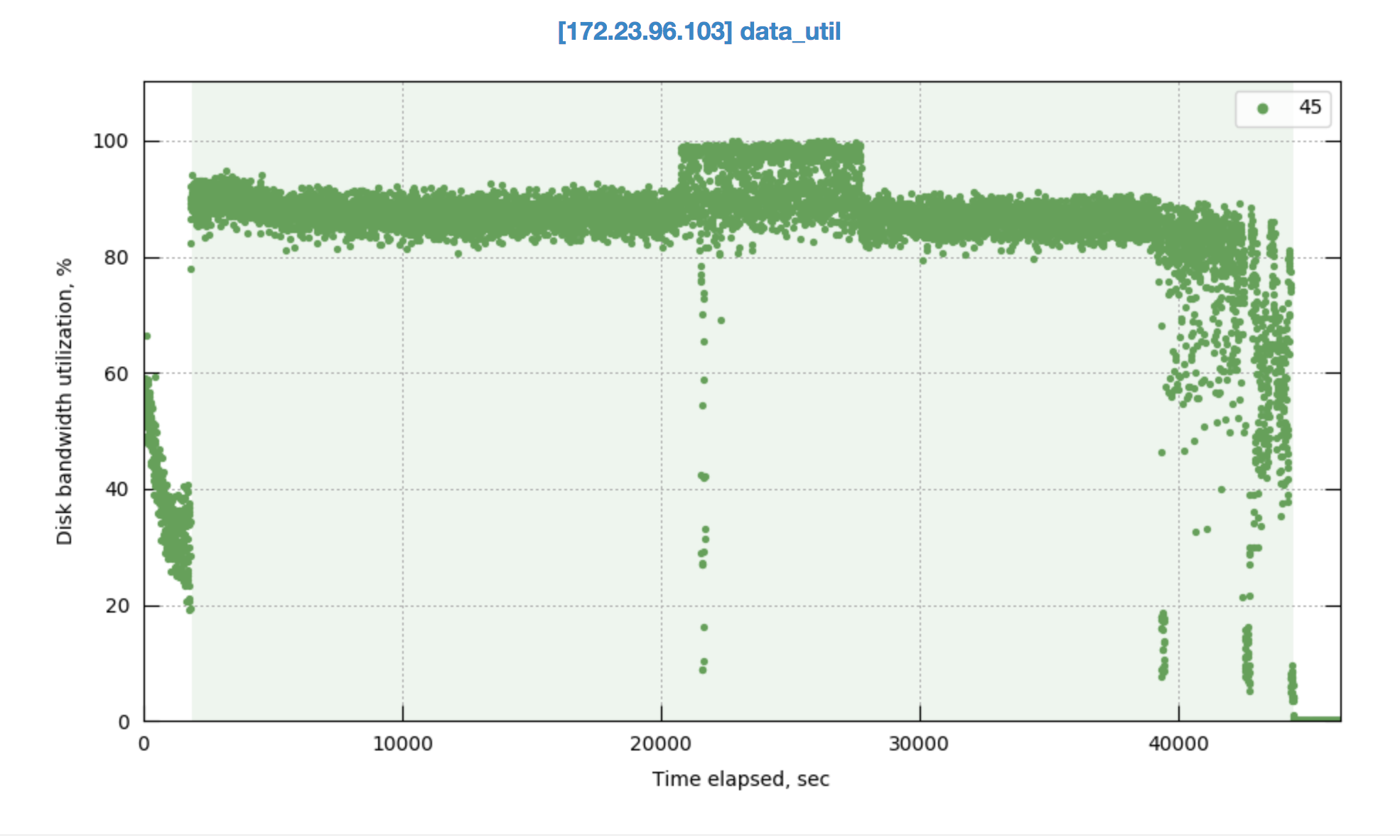
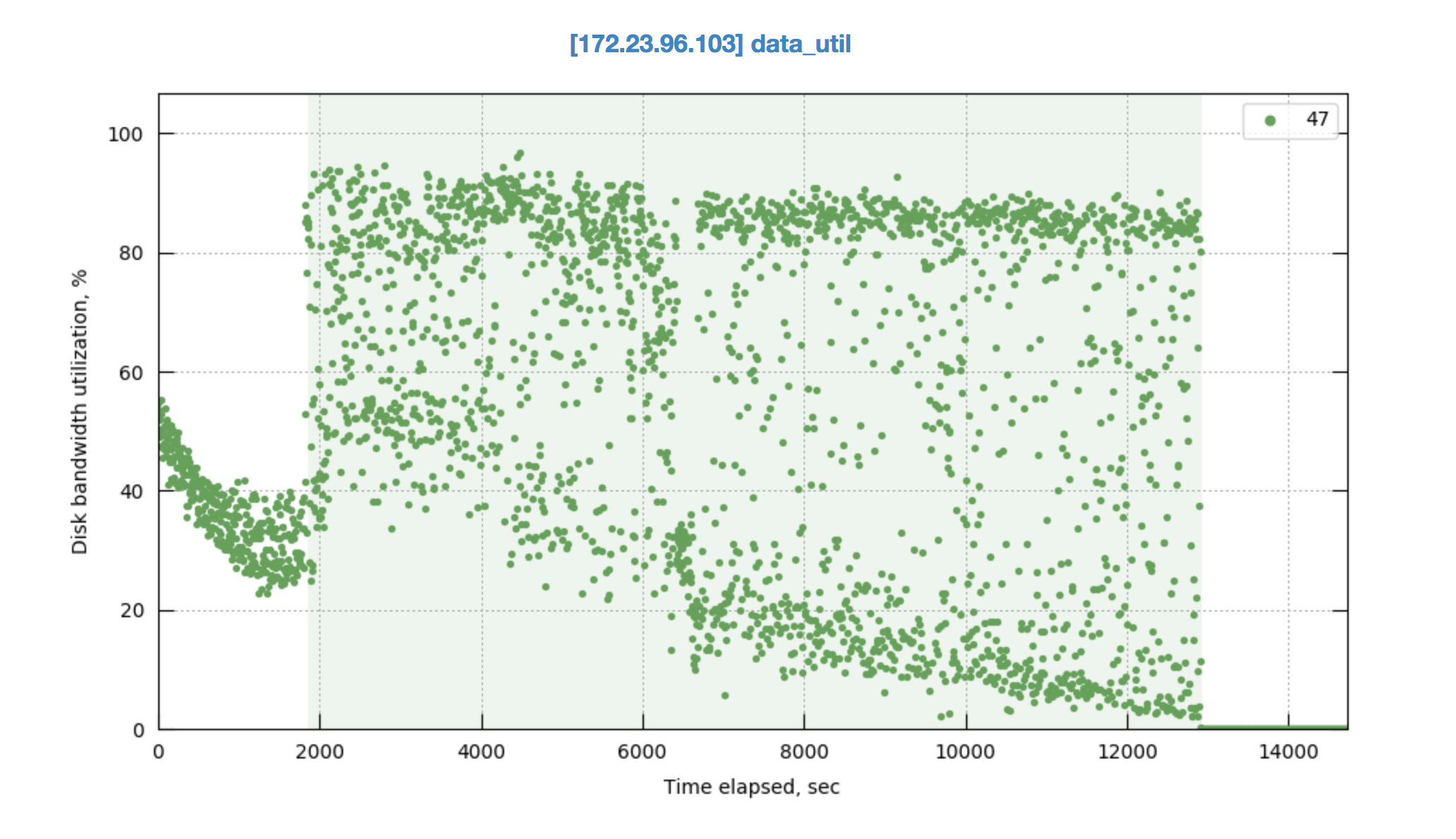
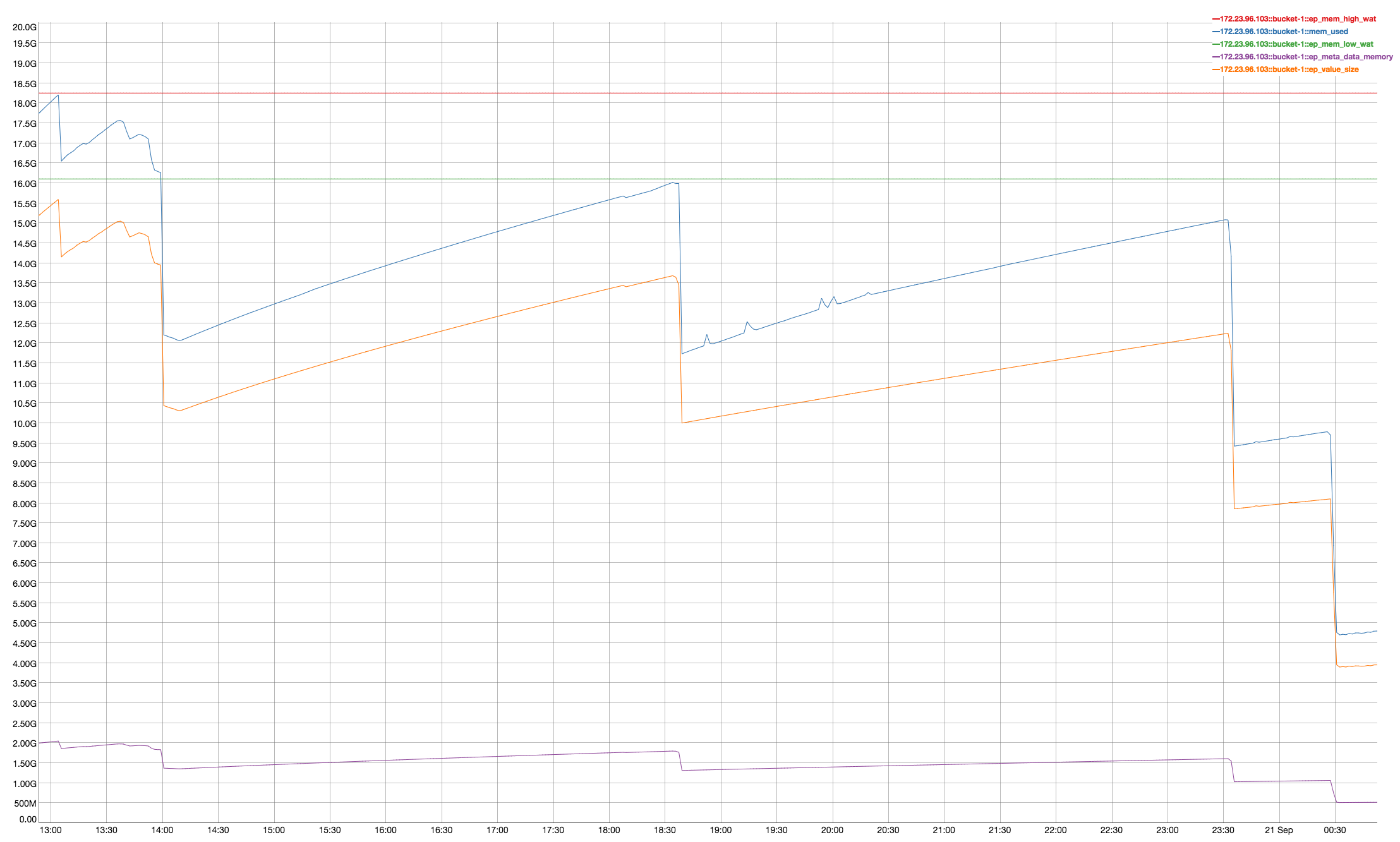
It looks like rebalancing goes on hung status when data compaction kicks in . Please take a look into this issue
Data set up :
- Initial data load - 2 Billion docs
- Continuous operatons - 15 k, 5% Update , 5% Create
Rebalancing steps :
- Step - Rebalance-In (4-3)
- Step - Rebalance-Out (3-4)
- Step - Rebalance Swap ( 4 -4 )
Multi Job -
http://perf.jenkins.couchbase.com/job/Titan-reb_Multitests/45/
Individual Jobs (unaffected) -
http://perf.jenkins.couchbase.com/job/Titan-reb_Multitests/42/
http://perf.jenkins.couchbase.com/job/Titan-reb_Multitests/37/
Attachments
Issue Links
- mentioned in
-
Page Loading...