Details
-
Bug
-
Resolution: Won't Fix
-
 Major
Major
-
6.0.0
-
Enterprise Edition 6.0.0 build 1673
-
Untriaged
-
Centos 64-bit
-
-
No
-
CX Sprint 122
Description
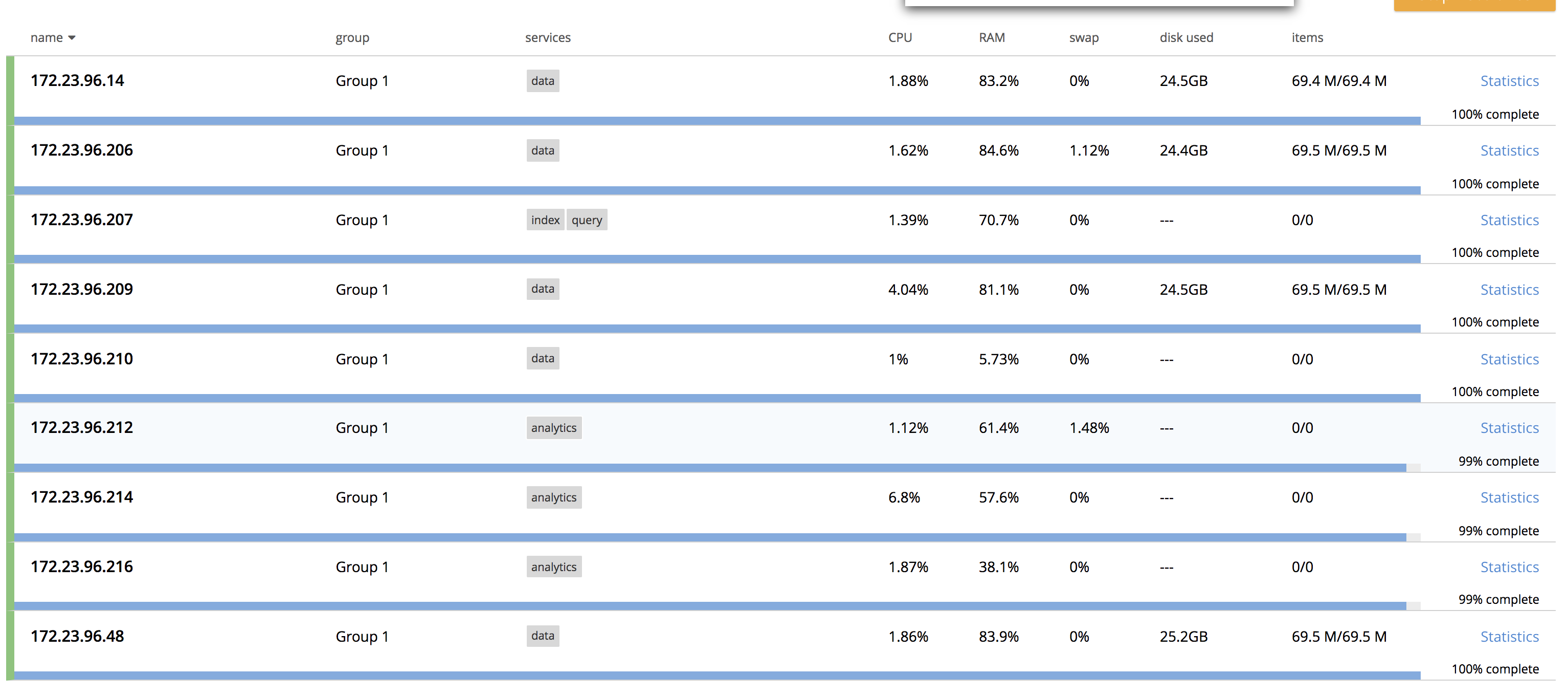
9 Node cluster, 6 KV and 3 CBAS
CentOS7, 8 core VM's
Note: I am assuming Analytics rebalance is struck based on rebalance % displayed on UI. It shows 99% for analytics and 100% for data nodes. Refer attached screenshot