Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
5.0.0, 5.1.0, 5.5.0
-
4 nodes of data, 2 of query +index
-
Triaged
-
No
Description
Problem
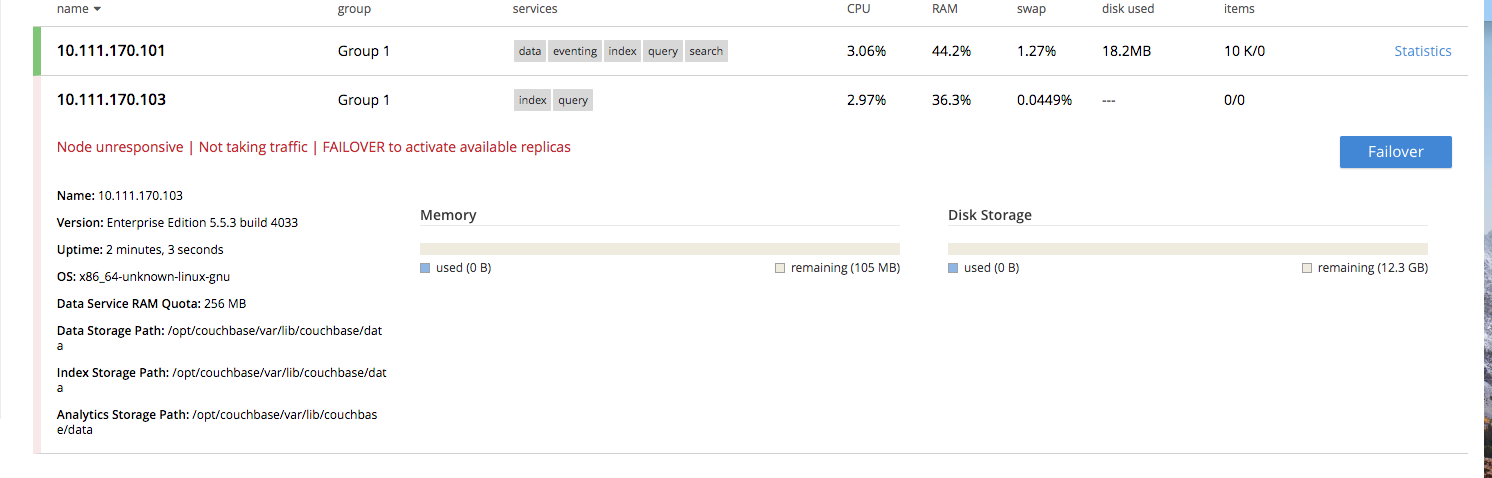
Backup is hangs instead of returning an error when trying to backup a cluster which is not in full capacity (1 data node is down, not failed over):
Copying at 0B (estimating time remaining) 0 items / 0B
|
beer-sample [ ] 100.00%
|
Background
When trying to backup a cluster, if 1 or more node(s) is down, when fail-over is not active, backup should fail,
Steps to reproduce
- turn off auto-failover
- stop the couchbase-server on 1 data node
- try to do a backup with cbbackupmgr on that cluster
- backup would hang without error message
- starting the server again on that node would not change the state
Request
cbbackupmgr should fail with an error when a node is down and message the client that there is a data integrity issue and a backup cannot be completed at this time.#
Logs
2018-06-07T16:47:40.461+00:00 (Cmd) config -a /home/vagrant/backup -r test
|
2018-06-07T16:47:40.461+00:00 (Cmd) Backup repository `test` created successfully in archive `/home/vagrant/backup`
|
2018-06-07T16:48:22.858+00:00 (Cmd) backup -a /home/vagrant/backup -r test -c localhost -u Administrator -p ********
|
2018-06-07T16:48:22.859+00:00 (Rest) GET http://localhost:8091/pools 200
|
2018-06-07T16:48:22.863+00:00 (Rest) GET http://localhost:8091/pools/default/buckets 200
|
2018-06-07T16:48:22.864+00:00 (Plan) Executing transfer plan
|
2018-06-07T16:48:22.864+00:00 (Plan) Checking for data movement restrictions between beer-sample and beer-sample
|
2018-06-07T16:48:22.868+00:00 (Rest) GET http://localhost:8091/pools/default/buckets 200
|
2018-06-07T16:48:22.870+00:00 (Rest) GET http://localhost:8091/pools/default 200
|
2018-06-07T16:48:22.870+00:00 Transfering from Couchbase Server 5.1.0
|
2018-06-07T16:48:22.871+00:00 Lowering forestdb buffer cache size to 1073741824 due to insufficient memory
|
2018-06-07T16:48:22.871+00:00 Lowering forestdb buffer cache size to 536870912 due to insufficient memory
|
2018-06-07T16:48:22.900+00:00 [INFO][FDB] Forestdb blockcache size 536870912 initialized in 28688 us
|
|
2018-06-07T16:48:22.900+00:00 [INFO][FDB] Forestdb opened database file /home/vagrant/backup/test/2018-06-07T16_48_22.864320064Z/beer-sample-bde74a655e67fb765d08580b94aeb41a/data/shard_0.fdb
|
2018-06-07T16:48:22.904+00:00 [INFO][FDB] Forestdb closed database file /home/vagrant/backup/test/2018-06-07T16_48_22.864320064Z/beer-sample-bde74a655e67fb765d08580b94aeb41a/data/shard_0.fdb
|
2018-06-07T16:48:22.911+00:00 (Plan) Transfering bucket configuration for beer-sample to beer-sample
|
2018-06-07T16:48:22.916+00:00 (Rest) GET http://localhost:8091/pools/default/buckets 200
|
2018-06-07T16:48:22.917+00:00 (Plan) Transfering views definitions for beer-sample to beer-sample
|
2018-06-07T16:48:22.921+00:00 (Rest) GET http://localhost:8091/pools/default/buckets 200
|
2018-06-07T16:48:22.922+00:00 (Rest) GET http://localhost:8091/pools/default/nodeServices 200
|
2018-06-07T16:48:22.926+00:00 (Rest) GET http://10.112.175.101:8091/pools/default/buckets/beer-sample/ddocs 200
|
2018-06-07T16:48:22.927+00:00 (Plan) Transfering GSI index definitions for beer-sample to beer-sample
|
2018-06-07T16:48:22.927+00:00 (Rest) GET http://localhost:8091/pools/default/nodeServices 200
|
2018-06-07T16:48:22.928+00:00 (Plan) Transfering full text index definitions for beer-sample to beer-sample
|
2018-06-07T16:48:22.928+00:00 (Rest) GET http://localhost:8091/pools/default/nodeServices 200
|
2018-06-07T16:48:22.928+00:00 (Plan) Deciding which key value data to transfer for beer-sample
|
2018-06-07T16:48:22.928+00:00 (Rest) GET http://localhost:8091/pools/default/nodeServices 200
|
Attachments
Issue Links
- relates to
-
-
- Closed
-