Details
-
Bug
-
Resolution: User Error
-
 Major
Major
-
5.5.4
-
Enterprise Edition 5.5.4 build 4340
-
Untriaged
-
Centos 64-bit
-
No
Description
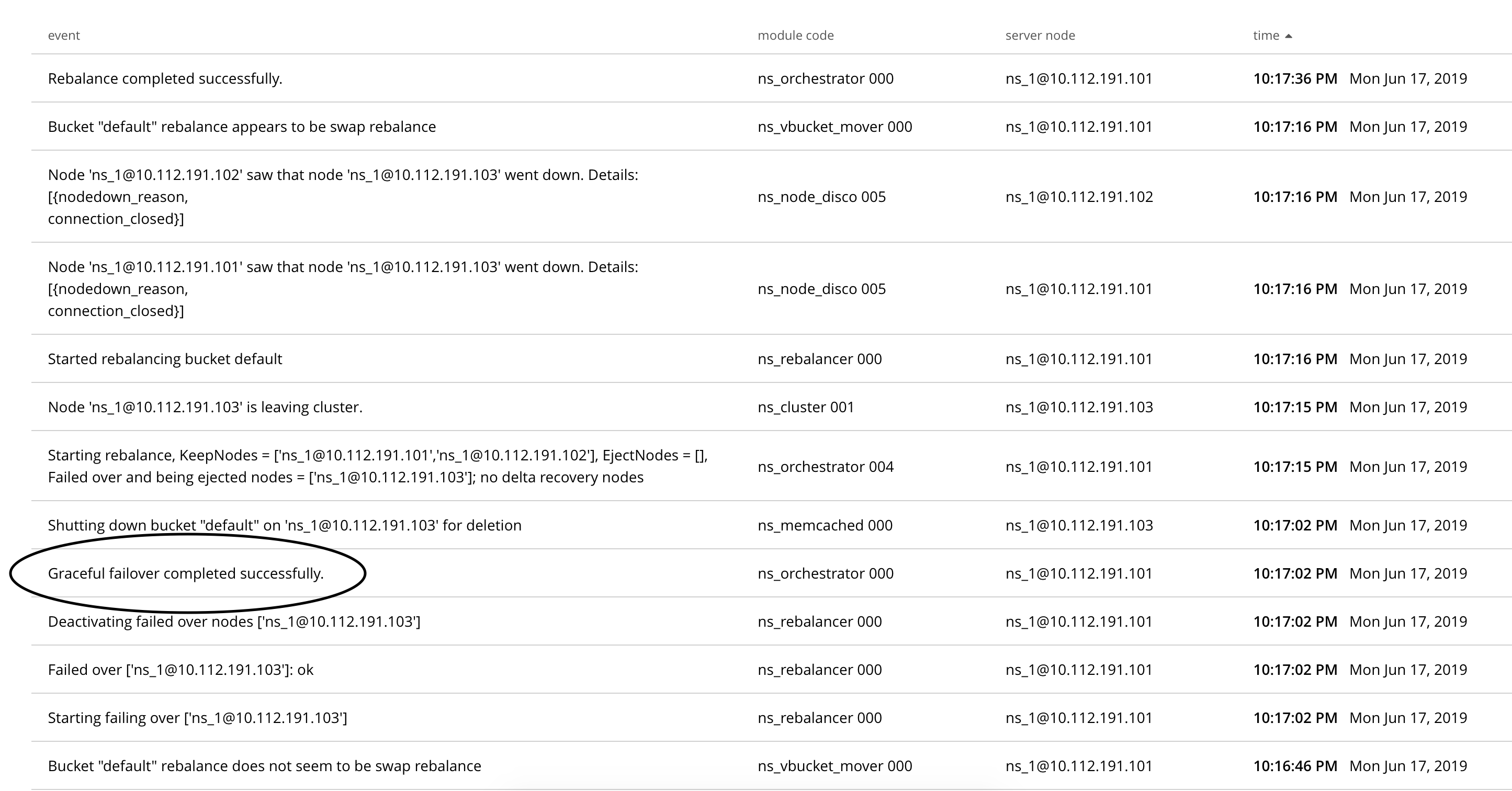
Build: 5.5.4 build 4340
Scenario:
- Create 3 node cluster
- Create "default" couchbase bucket with replica=0
- Do graceful failover of 1 node from the cluster
- Before rebalancing the cluster, perform doc_ops, such that it affects the vbucket of the "gracefully failover" node
- All operation will failed with the memcached error #7: Not my vbucket
Same can happen when 'graceful failover' of,
- 2 nodes with replica=1
- 3 nodes with replica=2
- 4 nodes with replica=3
Expected behavior:
User should not be allowed to perform graceful failover when there is no active node left behind in the server and failover operation must fail.
Because in graceful failover, user is not expected to get any failures related to doc_operations. And in these cases, users should only be allowed to perform 'hard failover'