Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
6.0.3, 6.5.0
-
Triaged
-
Unknown
-
KV-Engine Mad-Hatter GA
Description
Summary
During investigation of SyncWrite persistTo performance, is was observed that the op/s for a single-threaded persist_majority workload would drop to zero for a number of seconds, recovering after 10s.
Steps to Reproduce
- Start a two-node cluster run:
./cluster_run -n2 --dont-rename./cluster_connect -n2 - Drive with a SyncWrite workload (SyncWrites not strictly necessary, but makes the bug very apparent as delay in flusher will cause op/s to go to zero). See attached sync_repl.py script.
./engines/ep/management/sync_repl.py localhost:12000 Administrator asdasd default loop_setD key value 100000 3 - Observe op/s on UI.
Expected Results
Op/s should be broadly constant, with only small (sub-second) drops in op/s when compaction runs.
Actual Results
Op/s drops to zero:
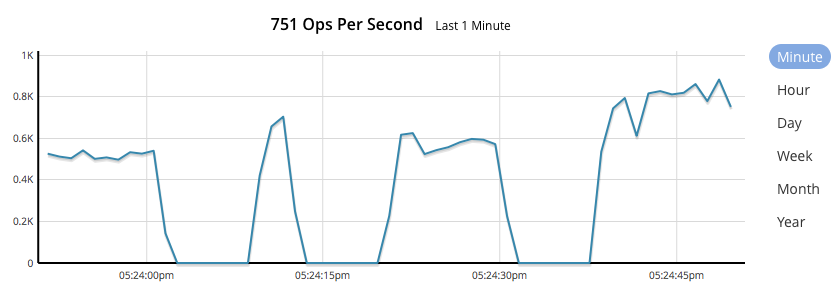
During such "blips", Slow operation log messages were observed, each time the "slow" operation took very close to 4 or 8 seconds:
‡ grep "Slow operation" logs/n_0/memcached.log.00000*
|
logs/n_0/memcached.log.000000.txt:2019-10-08T09:51:14.753174+01:00 WARNING 48: Slow operation. {"cid":"[::1]:50067/b2034b5a","duration":"4003 ms","trace":"request=378423659125160:4003656 store=378423659139440:15 sync_write.ack_remote=378423660320419:0 sync_write.ack_local=378427662099819:0 sync_write.prepare=378423659147291:4002977 store=378427662773987:0","command":"SET","peer":"[::1]:50067","bucket":"default"}
|
logs/n_0/memcached.log.000000.txt:2019-10-08T09:51:23.697168+01:00 WARNING 48: Slow operation. {"cid":"[::1]:50067/63159010","duration":"4005 ms","trace":"request=378432601417239:4005461 store=378432601426289:20 sync_write.ack_remote=378432603242164:0 sync_write.ack_local=378436606766192:0 sync_write.prepare=378432601435464:4005363 store=378436606870788:1","command":"SET","peer":"[::1]:50067","bucket":"default"}
|
48: Slow operation. {"cid":"[::1]:50312/747df525","duration":"8005 ms","trace":"request=379458120957691:8005773 store=379458120963442:16 sync_write.ack_local=379458121688761:0 sync_write.ack_remote=379466126503925:0 sync_write.prepare=379458120968581:8005592 store=379466126719482:1","command":"SET","peer":"[::1]:50312","bucket":"default"}
|
Attachments

Issue Links
| For Gerrit Dashboard: MB-36380 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 116083,4 | MB-36380 [1/2]: Regression test for missing Flusher wakeup | master | kv_engine | Status: MERGED | +2 | +1 |
| 116084,5 | MB-36380 [2/2]: Fix missing Flusher wakeup | master | kv_engine | Status: MERGED | +2 | +1 |