Details
Description
Cluster is configured with a "default" bucket of 8 nodes each with 8GB of ram configuration. Server has 16GB of ram.
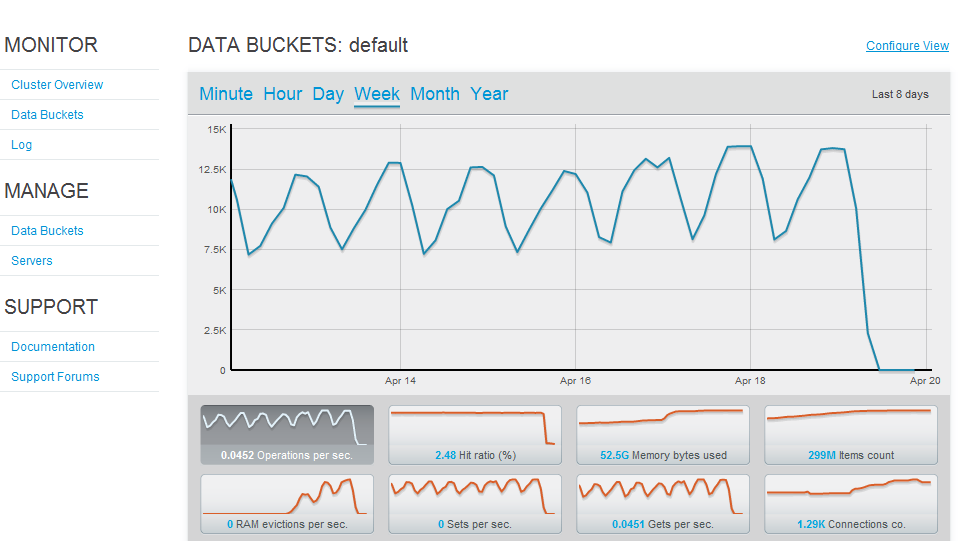
The cluster was online for many many weeks and suddenly returned 0 cache hits yesterday. Upon login I see that the stats are functioning and that one node has been shutdown 209.151.227.98 due to ns_memcached002 code. However, the second this event happened, the entire cluster/bucket no longer returns cache hits or any data whatsoever.
What happend on 209.151.227.98 node. I can confirm that 209.151.227.98's membase server crashed and the processes with it are no longer active on the server. It appears the .98 suffered a hardware error and file system went into read-only mode.
sd 0:0:0:0: SCSI error: return code = 0x08000002
sda: <<DEFERRED>>: sense key: Hardware Error
Add. Sense: Mechanical positioning error
Info fld=0xb021bc
end_request: I/O error, dev sda, sector 4317391
Buffer I/O error on device sda1, logical block 27602
lost page write due to I/O error on sda1
Aborting journal on device sda1.
ext3_abort called.
EXT3-fs error (device sda1): ext3_journal_start_sb: Detected aborted journal
Remounting filesystem read-only
However, this still does not explain how the bucket for the entire cluster is no longer returning cache hits.
Attached the log generated by the membase cli as well as a image capture of the GUI showing you the drop-off this single node failure caused the cluster to become unusable.