Details
-
Task
-
Resolution: Unresolved
-
 Major
Major
-
6.5.0
Description
(Separated out from MB-36827)
The hottest function in the profile for workers in this benchmark is HashTable::findInner - the actual function which searches the HashTable for a given key. This is used during both set() and get() to locate a StoredValue to operate on:
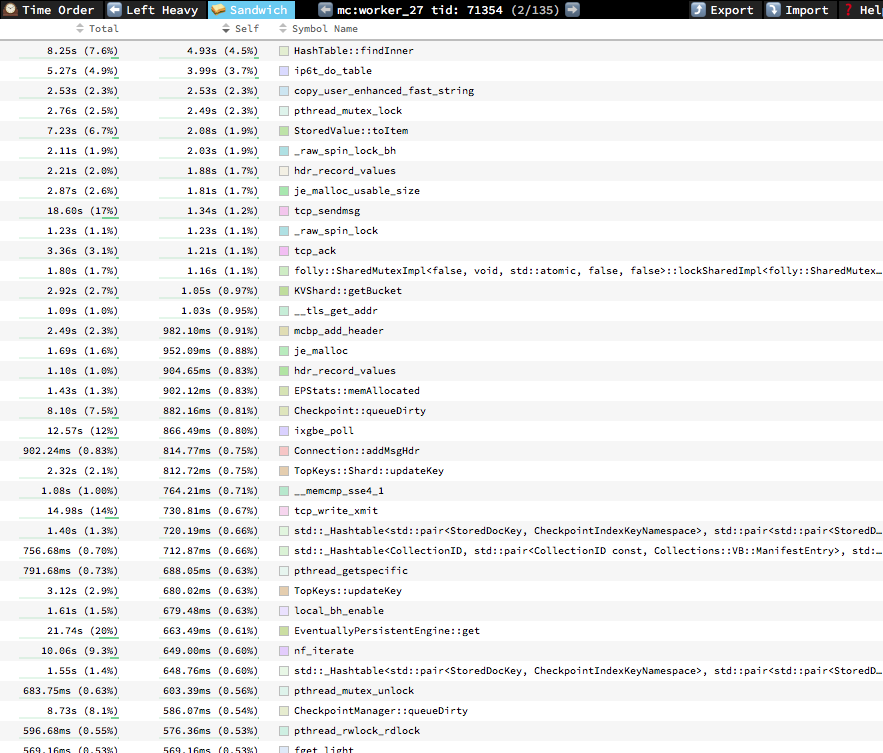
Note this function has been changed as part of Sync Replication - it now returns pointers to committed and prepared StoredValues in the HashTable. Due to the way this is implemented, it must now scan the entire HashTable chain looking for committed and prepared StoredValues - this was not the case pre-SyncWrites (i.e. 6.0) where it would return immediately as soon as a match was found (only one match possible).
Given this particular benchmark doesn't use SyncWrites, this extra walking of the HashTable chain is potentially expensive, as it basically involves walking a tiny linked lists which are likely not in CPU cache.
I performed an experiment to see what happens if the function is essentially reverted to the Alice behaviour - return as soon as a Committed item is found, avoiding unnecessary linked list traversal (see http://review.couchbase.org/117972):
@@ -327,6 +322,7 @@ HashTable::FindInnerResult HashTable::findInner(const DocKey& key) {
|
} else {
|
Expects(!foundCmt);
|
foundCmt = v;
|
+ break;
|
}
|
}
|
}
|
This was put into a toy build (based off build 4788) and run as: http://perf.jenkins.couchbase.com/job/triton/28607/
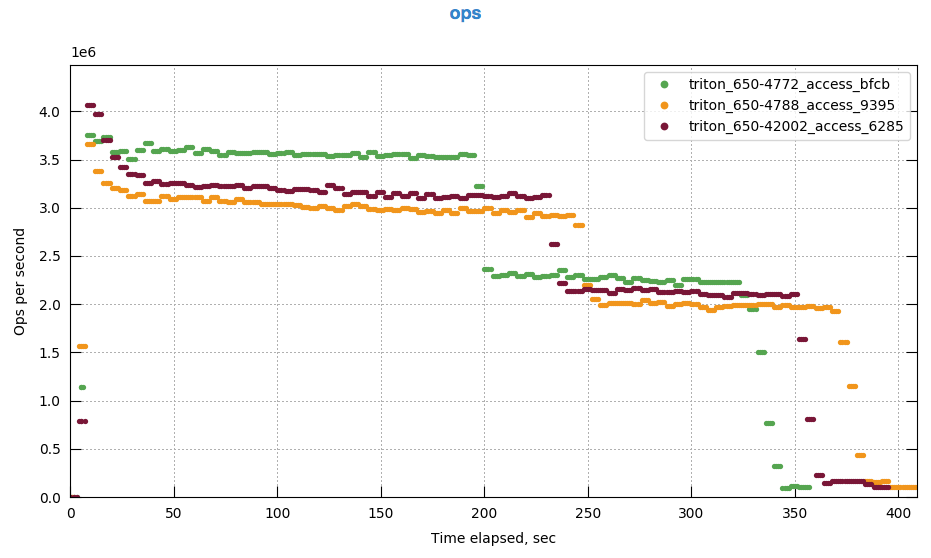
This gives the following performance compared to builds 4722 and 4788:
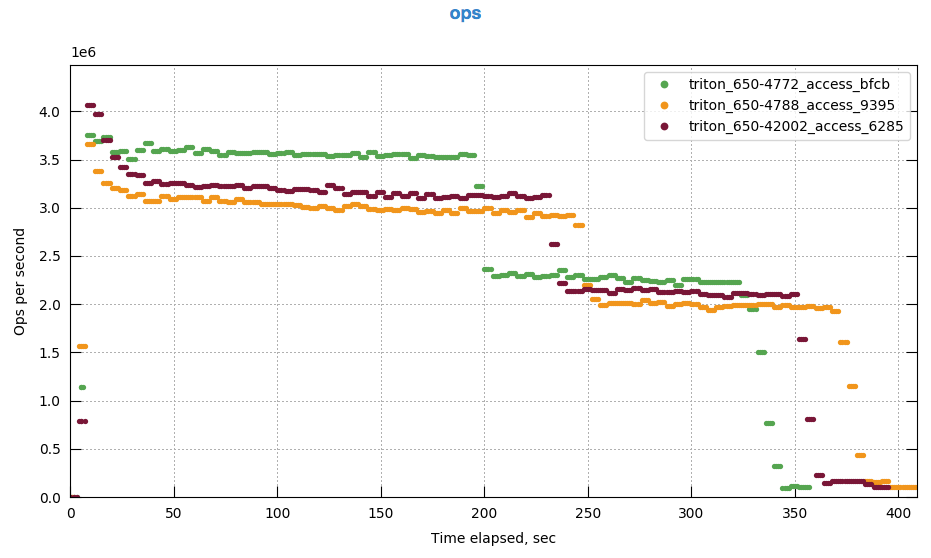
(Full comparison: http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=triton_650-4772_access_bfcb&snapshot=triton_650-4788_access_9395&snapshot=triton_650-42002_access_6285 )
| Build | Max Throughput (ops/s) |
|---|---|
| 6.5.0-4788 | 3,111,731 |
| 6.5.0-42002 (toy: HashTable early return) | 3,265,769 |
i.e. 5% greater Max Throughput as measured by perfrunner, and overall higher throughput as seen in the graph.
Note This change by itself is not valid; we obviously do need to keep looking for prepared values in case they do exist. However, it does highlight that there's significant performance to be gained if we can avoid unnecessarily walking the HashTable chain when we know there is no prepare present.
The current implementation of that code dates to (http://review.couchbase.org/#/c/109320/4/engines/ep/src/hash_table.cc) - prior to that only the first StoredValue (prepared or committed) which existed in the HashTable chain was returned. The chain was arranged such that a prepared StoredValue (if one existed for a given key) was before any committed StoredValue - hence as soon as a committed StoredValue was found the search knew there was no prepared StoredValue for this key. The aforementioned patch removed that optimisation when expanding the ways the HashTable could be searched, however I believe conceptually we could restore this layout and hence in the case of a non-SyncWrite workload stop searching once a committed StoredValue was found (i.e. what the toy build does).
Attachments
Issue Links
- relates to
-
MB-36827 16% throughput regression in test "KV : Pillowfight, 80/20 R/W, 256B binary items"
-

- Closed
-