Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
1.7.1
-
Security Level: Public
Description
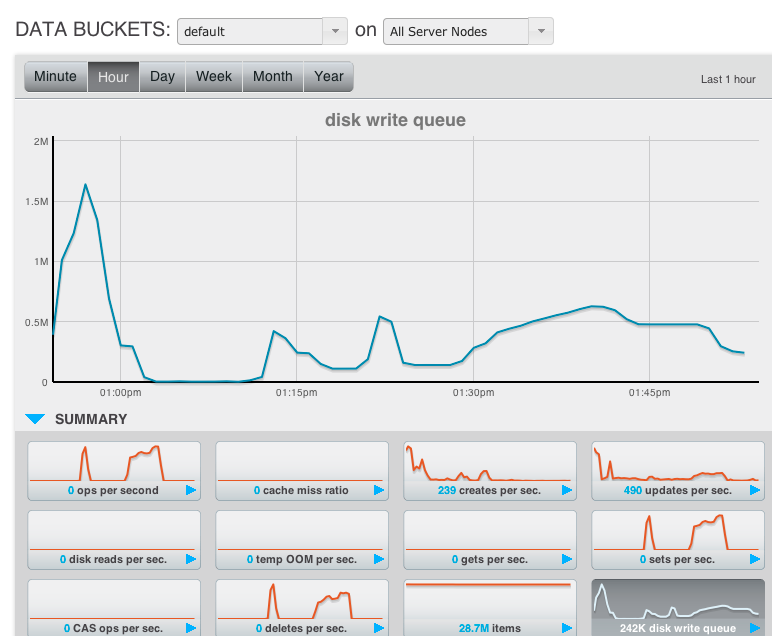
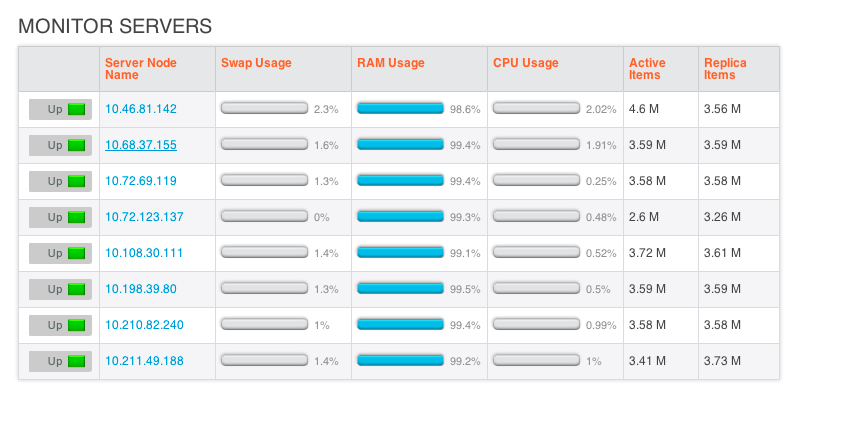
cluster was very stable and was under 20k ops load for quite sometime and i decided to add an 8 th node and rebalance to increase the capacity
Rebalance exited with reason
{mover_failed,timeout}ns_orchestrator002 ns_1@10.46.81.142 13:12:30 - Fri Jul 15, 2011
Node 'ns_1@10.72.123.137' saw that node 'ns_1@10.68.37.155' came up. ns_node_disco004 ns_1@10.72.123.137 12:54:00 - Fri Jul 15, 2011
Node 'ns_1@10.68.37.155' saw that node 'ns_1@10.72.123.137' came up. ns_node_disco004 ns_1@10.68.37.155 12:54:00 - Fri Jul 15, 2011
Bucket "default" loaded on node 'ns_1@10.72.123.137' in 0 seconds. ns_memcached001 ns_1@10.72.123.137 12:54:00 - Fri Jul 15, 2011
Starting rebalance, KeepNodes = ['ns_1@10.46.81.142','ns_1@10.68.37.155',
'ns_1@10.72.69.119','ns_1@10.108.30.111',
'ns_1@10.198.39.80','ns_1@10.210.82.240',
'ns_1@10.211.49.188','ns_1@10.72.123.137'], EjectNodes = []
{kind=link}
{kind=link}