Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
6.0.0, 6.0.1, 6.0.2, 6.0.3, 6.0.4, 6.5.1, 6.6.0, 6.5.0
-
Untriaged
-
1
-
Unknown
-
KV Sprint 2020-Oct
Description
Ephemeral buckets set to auto_delete with replicas configured can reach deadlock due to eviction.
Ephemeral buckets set to auto_delete can only evict items from active vbuckets, as replica vbuckets must remain consistent with their actives.
However, eviction is not coordinated across nodes.
Considering the simple case of a three node cluster (nodes A, B, and C) with one or more replicas configured.
When node A reaches the high watermark, it responds by deleting items from its active vbuckets. Once these deletions are replicated, this will lower the memory usage of B and C. As a result, B and C may now be further away from hitting the high watermark, and need not delete active items yet.
As B and C receive more ops, their active vbuckets grow, as do the replica vbuckets on A. Now, A has a smaller fraction of its quota available for active items.
This can occur repeatedly, driving the number of active items on A lower and lower.
As the replicas on A continue to grow, replica memory usage can eventually exceed the high watermark. At this point, the eviction pager will run constantly and all active items on A will be immediately evicted.
While this is a very poor situation, node A could eventually recover if the active vb memory usage on B and C are reduced by eviction, expiry, or deletions.
Unfortunately node A can become deadlocked if the replica memory usage exceeds 99% of the quota. At this point, node A will already have evicted all active items, and will now back off on incoming replication. This will not recover without intervention, as even when B and C do evict A will not stream these deletions as replication is stalled waiting for memory usage to drop.
Ephemeral buckets which typically delete or expire items at a sufficient rate to avoid reaching the high watermark will be unaffected by this issue. The full deadlock also requires 3 or more nodes as replica memory can not reach 99% of a node's quota with just two nodes; that would require the active memory on the other node to reach 99%, which eviction should prevent.
A greater number of nodes, or a greater number of replicas may make this scenario more likely.
Issue is easily reproduced with pillowfight and cluster_run.
Issue presents as item count dropping on a single node
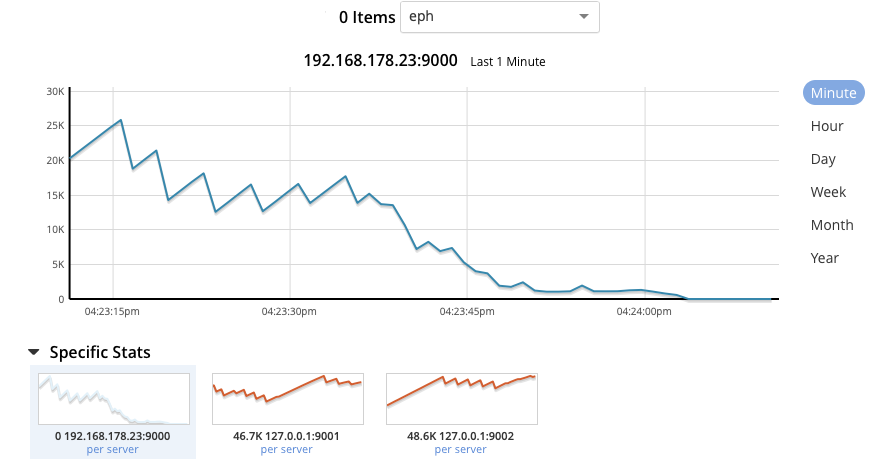
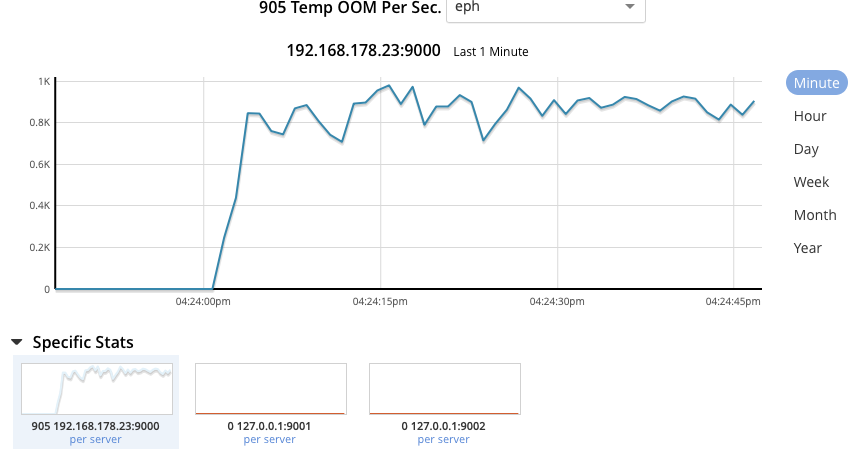
and eventual temp ooms from that node
Attachments

Issue Links
| For Gerrit Dashboard: MB-41804 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 140589,9 | Adding functional test for MB-41804 | mad-hatter | TAF | Status: NEW | 0 | 0 |