Description
7.0.0 Build 3530
I setup a 3-node cluster with all services on all nodes. I've loaded some data and indexes, but there's little-to-no-load on the system.
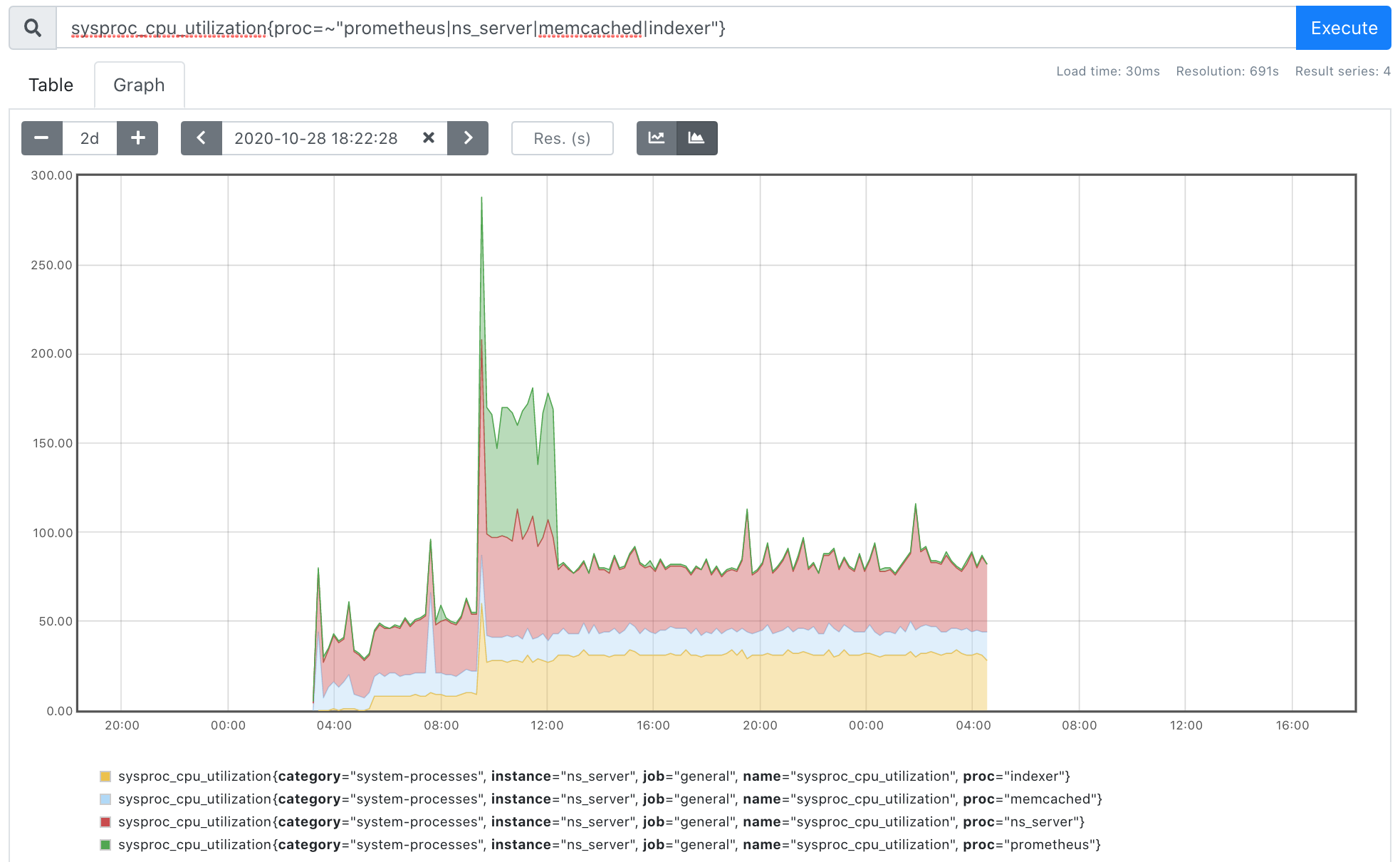
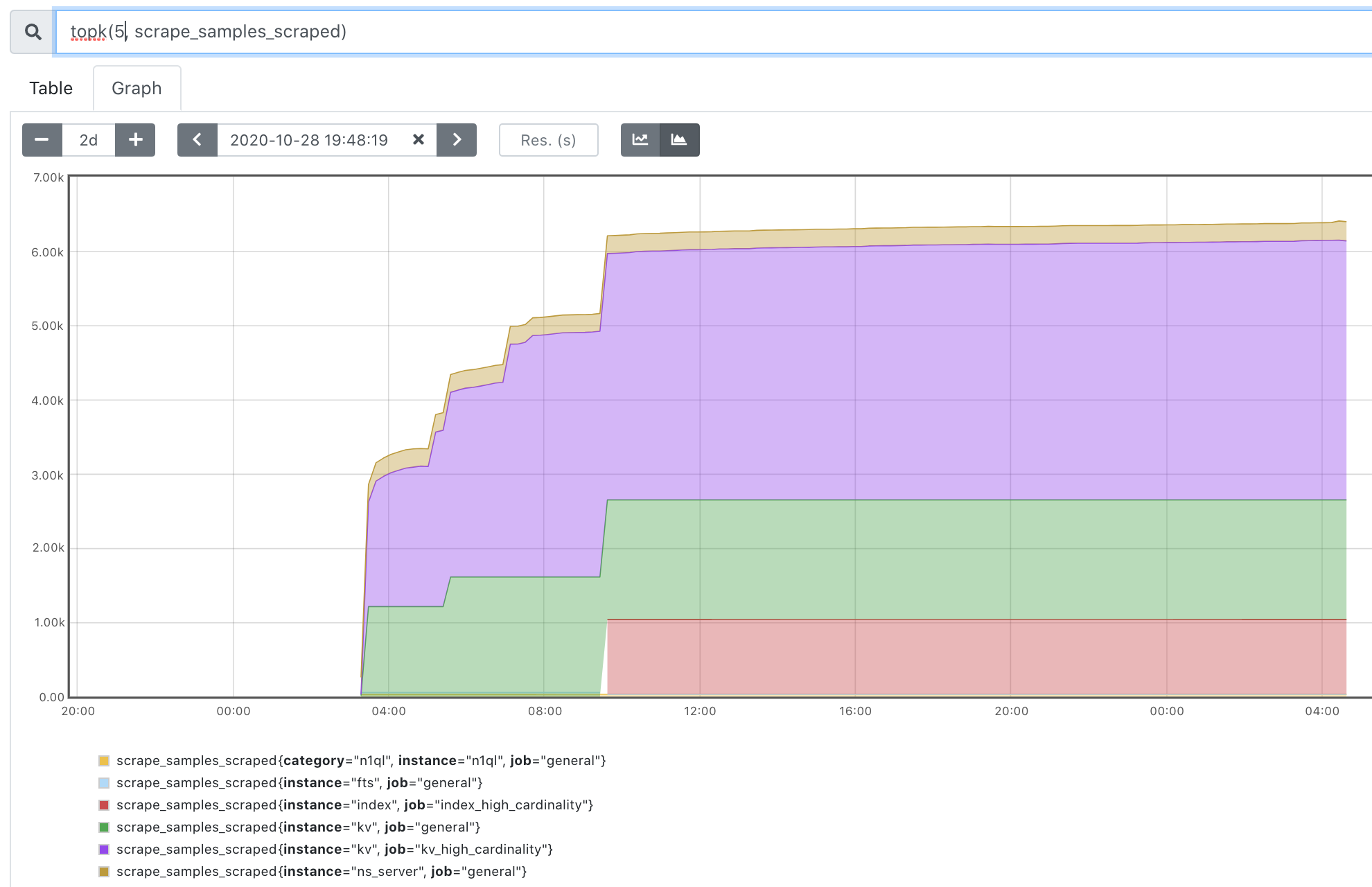
I'm noticing very high CPU usage from beam.smp, indexer, memcached and prometheus. Let me know if it would be better to have separate tickets for each component.
The UI is very sluggish, log collection is taking a very long time and I'm even unable to drop an index it seems (I'll open a separate ticket for that).
I also noticed on at least one node, that python3 was taking up >100% CPU during log collection.
FWIW these are 3 of our internal VMs and all running on the same host. I'll ask IT what the underlying resources and overcommit is like and whether we can move them to different systems...but it does seem pretty bad right now with little indication of why.
Logs are at:
https://s3.amazonaws.com/cb-engineering/perry/prometheus_cpu/collectinfo-2020-10-28T111956-ns_1%40172.23.97.84.zip
https://s3.amazonaws.com/cb-engineering/perry/prometheus_cpu/collectinfo-2020-10-28T111956-ns_1%40172.23.97.85.zip
https://s3.amazonaws.com/cb-engineering/perry/prometheus_cpu/collectinfo-2020-10-28T111956-ns_1%40172.23.97.86.zip
https://s3.amazonaws.com/cb-engineering/perry/prometheus_cpu/stats_data.zip