Details
-
Bug
-
Resolution: Not a Bug
-
 Major
Major
-
None
-
Cheshire-Cat
-
7.0.0-4375-enterprise
-
Triaged
-
Centos 64-bit
-
1
-
No
Description
Script to Repro
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/win10-bucket-ops.ini rerun=False,quota_percent=95,crash_warning=True -t bucket_collections.collections_drop_recreate_rebalance.CollectionsDropRecreateRebalance.test_data_load_collections_with_hard_failover_rebalance_out,nodes_init=6,nodes_failover=2,bucket_spec=single_bucket.buckets_1000_collections,GROUP=set2'
|
Steps to Repro
1) Create a 5 node cluster
2021-02-04 06:16:54,292 | test | INFO | pool-1-thread-6 | [table_view:display:72] Rebalance Overview
------------------------------------
| Nodes | Services | Status |
------------------------------------
| 172.23.98.196 | kv | Cluster node |
| 172.23.98.195 | None | <--- IN — |
| 172.23.121.10 | None | <--- IN — |
| 172.23.104.186 | None | <--- IN — |
| 172.23.120.206 | None | <--- IN — |
------------------------------------
2) Create bucket/scopes and 1000 collections.
2021-02-04 06:25:07,243 | test | INFO | MainThread | [table_view:display:72] Bucket statistics
----------------------------------------------------------------------------
| Bucket | Type | Replicas | Durability | TTL | Items | RAM Quota | RAM Used | Disk Used |
----------------------------------------------------------------------------
| Ew-5-44000 | couchbase | 2 | none | 0 | 10000 | 10485760000 | 857682648 | 666273212 |
----------------------------------------------------------------------------
3) In a continuous loop drop/recreate scopes/collections till rebalance completes.
4) Hard failover 2 nodes
2021-02-04 06:25:07,362 | test | INFO | MainThread | [collections_drop_recreate_rebalance:load_collections_with_failover:184] failing over nodes [ip:172.23.98.196 port:8091 ssh_username:root, ip:172.23.98.195 port:8091 ssh_username:root]
|
2021-02-04 06:29:47,776 | test | INFO | MainThread | [collections_drop_recreate_rebalance:wait_for_failover_or_assert:74] 2 nodes failed over as expected in 0.0899999141693 seconds
|
Rebalance completes successfully.
See

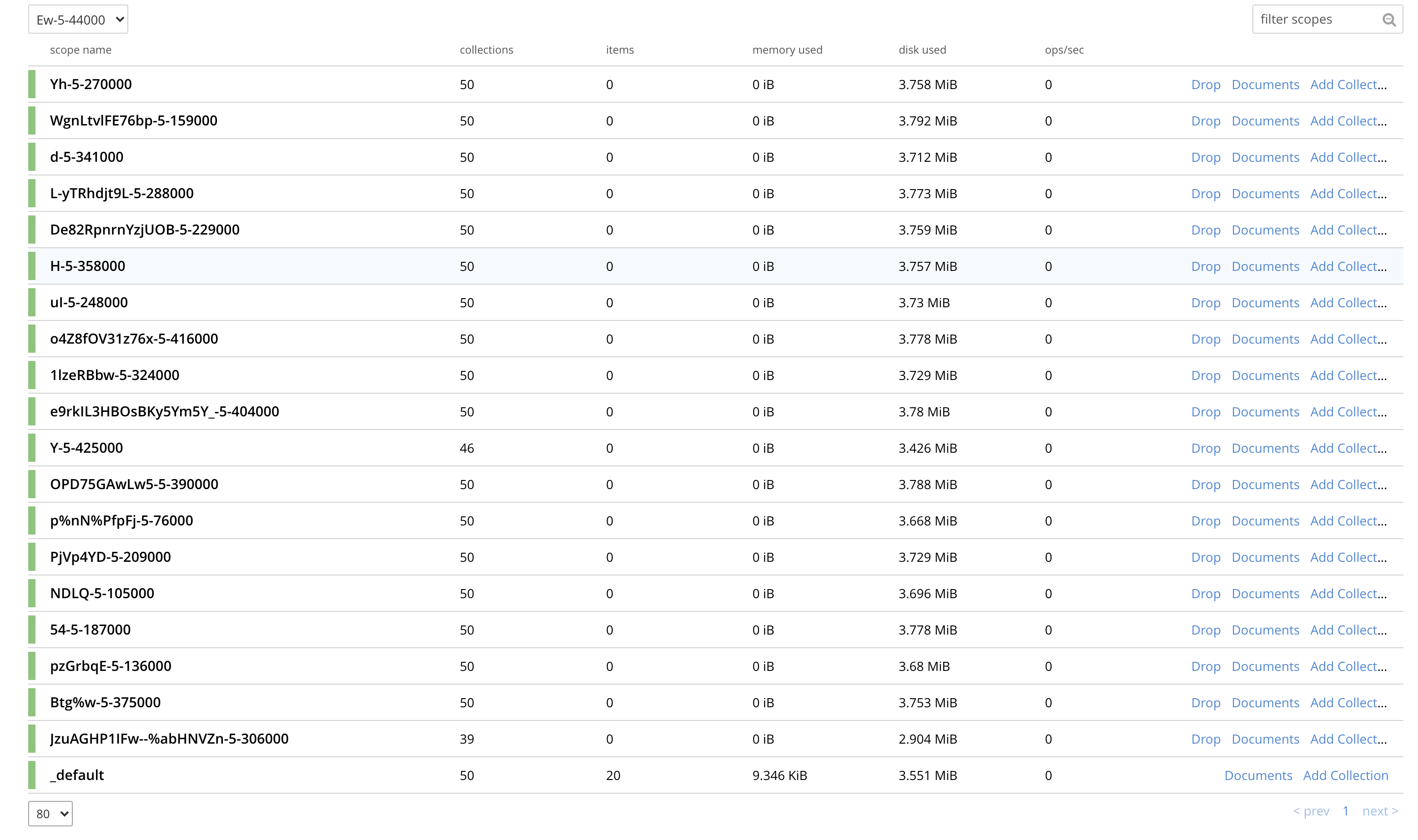
I also did manual compaction. I don't see how it can take 1.21GB data on RAM and 2.45GB on disk. Total size of docs is < 100MB. Even if we add metadata of scope/collections. I am not sure how the space used adds up. Could it be a stats issue?
Sumedh Basarkod mentioned it could be the same as MB-41801 as this bug uses the same set of TC's as that bug. MB-41801 is however closed now. Hence raising a new bug.
cbcollect_info attached.
Attachments
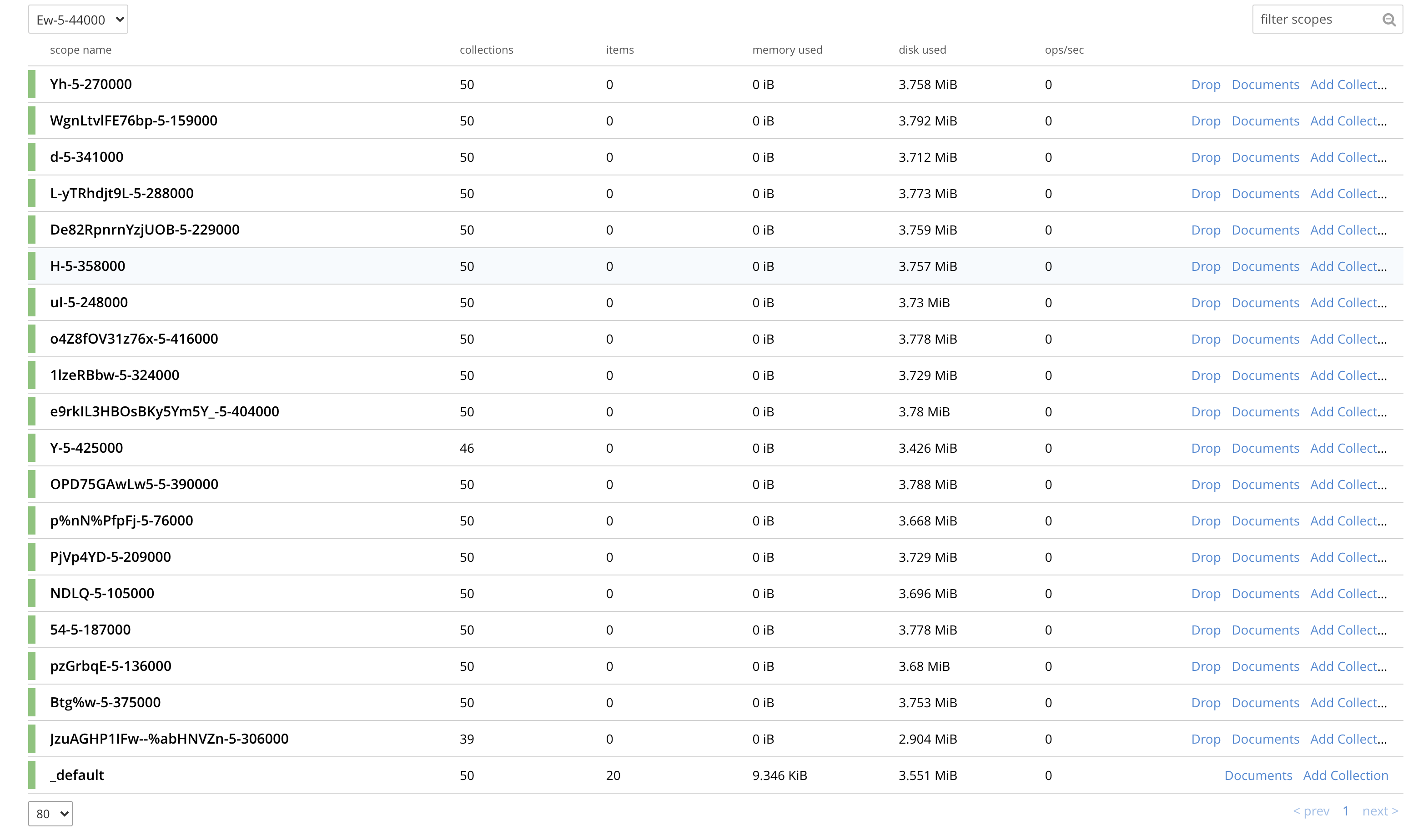

Issue Links
- relates to
-
-
- Closed
-