Details
-
Bug
-
Resolution: Done
-
 Critical
Critical
-
6.5.1
-
Untriaged
-
1
-
Unknown
Description
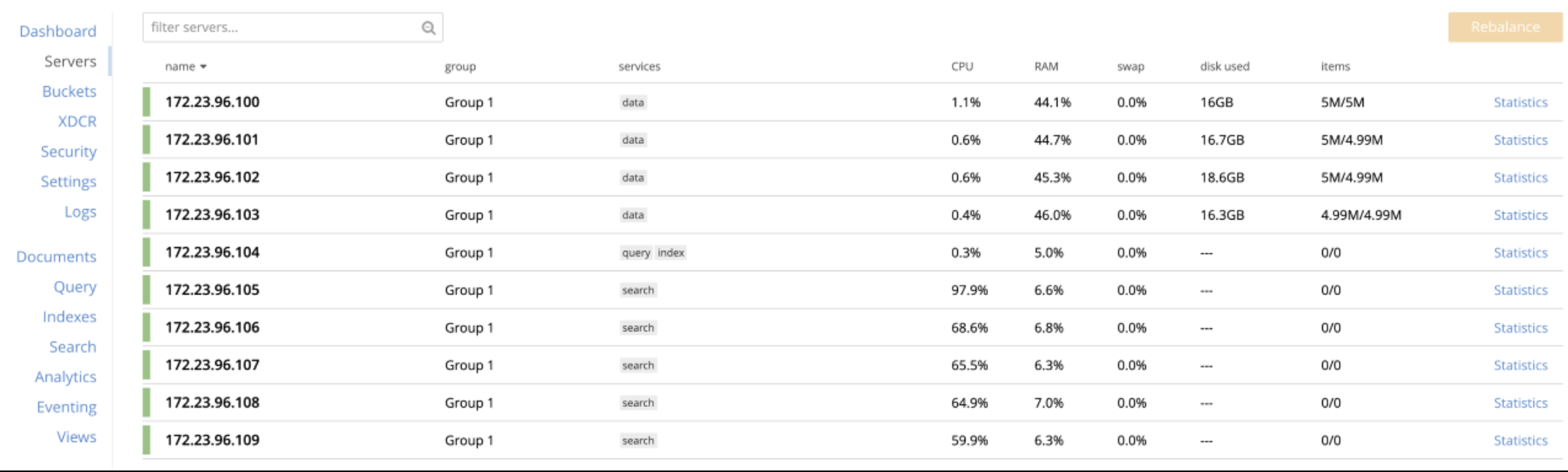
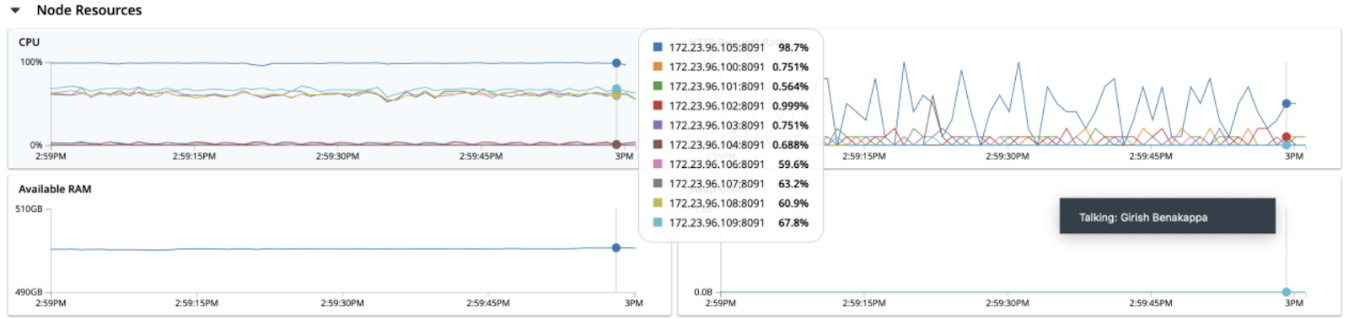
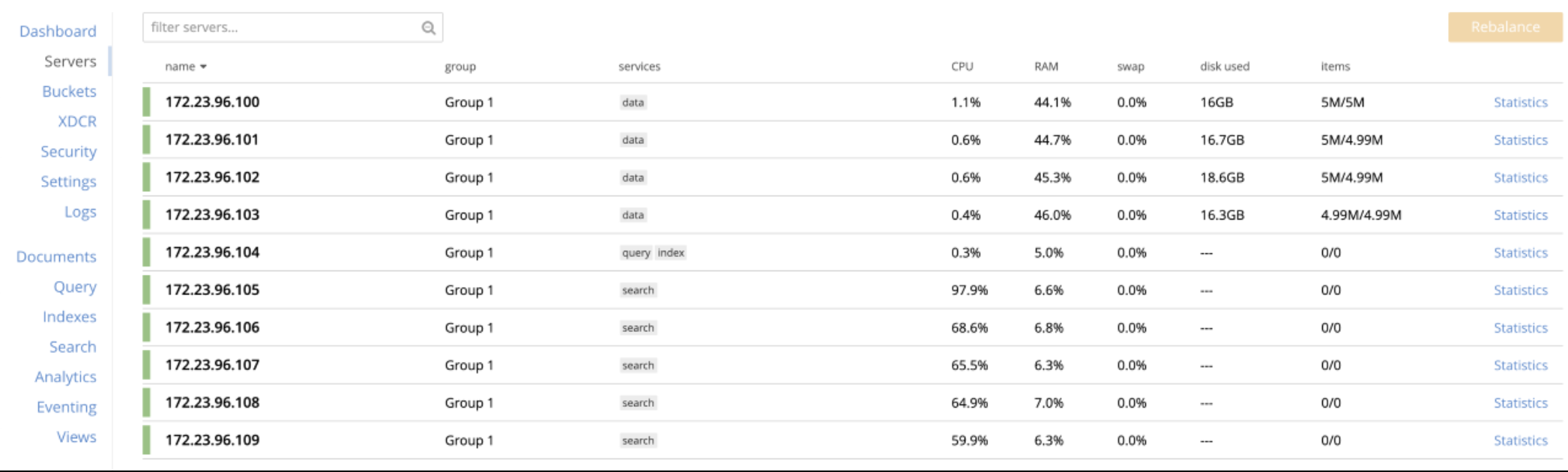
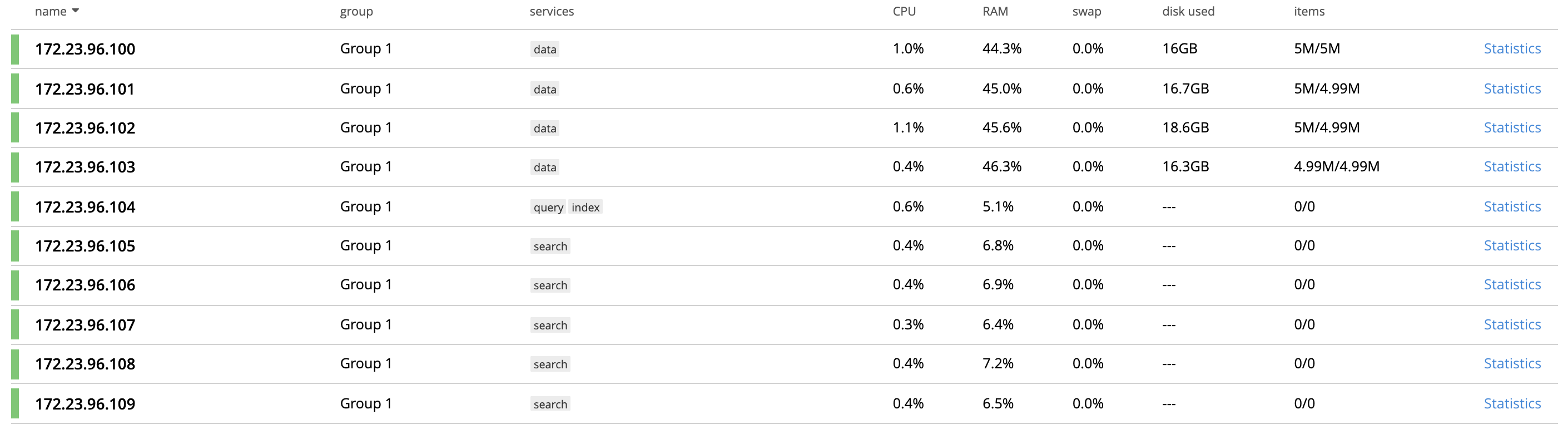
Observing disproportionate cpu utilization in a multi-search-node cluster with non-default(>6) index partitions and index replicas
Test/Cluster setup
- Nodes : 10
- KV/Search : 5:5
- Total docs : 20 M
- num of search Index : 1
- num of fields : 6
- Index Partition : 16
- index replica : 1
- workers : 20
- queryType : 1_conjuncts_2_disjuncts
- number_cores; 16