Details
-
Bug
-
Resolution: Not a Bug
-
 Critical
Critical
-
Cheshire-Cat
-
Enterprise Edition 7.0.0 build 4554
Description
Build: 7.0.0-4554
Scenario:
- 7 node cluster, Ephemeral bucket with replicas=2
- Load 25K initial docs into the bucket
- Restart couchbase-server on one of the node and start rebalance when the node is warming up
Observation:
Rebalance fails with reason "pre_rebalance_janitor_run_failed" for node 172.23.123.102
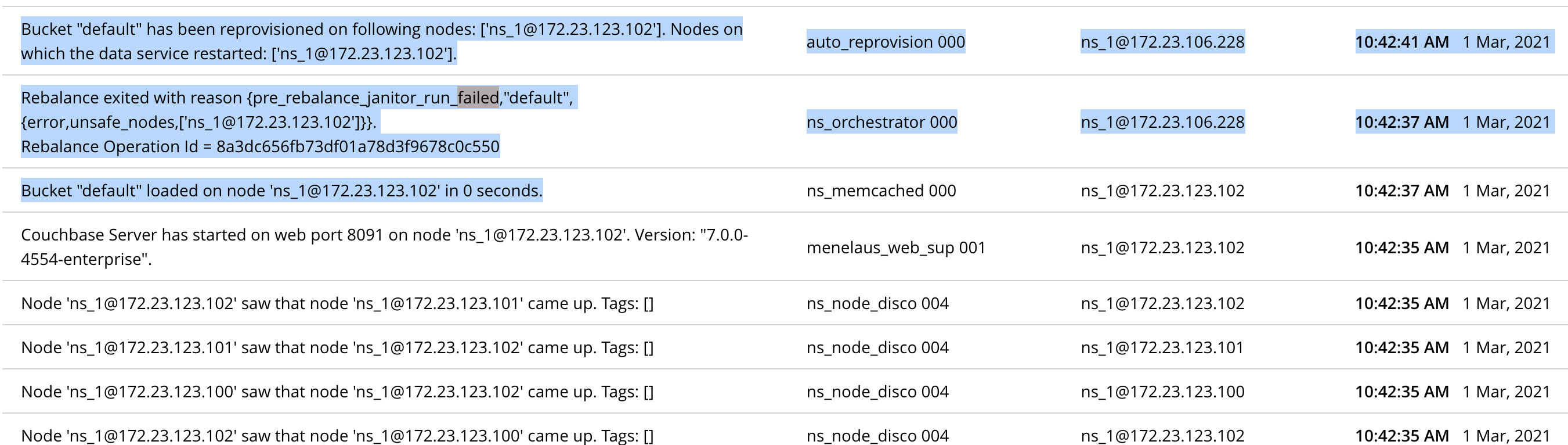
Test case:
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/testexec.29663.ini sdk_retries=10,num_items=250000,GROUP=P1;durability,EXCLUDE_GROUP=not_for_ephemeral,durability=MAJORITY,bucket_type=ephemeral,get-cbcollect-info=True,upgrade_version=7.0.0-4554 -t rebalance_new.rebalance_out.RebalanceOutTests.rebalance_out_with_warming_up,value_size=1024,bucket_type=ephemeral,upgrade_version=7.0.0-4554,sdk_retries=10,GROUP=P1;durability,nodes_out=5,EXCLUDE_GROUP=not_for_ephemeral,max_verify=100000,get-cbcollect-info=False,replicas=2,durability=MAJORITY,log_level=error,nodes_init=7,num_items=250000,infra_log_level=critical'
|
Jenkins log: http://qa.sc.couchbase.com/job/test_suite_executor-TAF/96698/console
Attachments

| For Gerrit Dashboard: MB-44682 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 154697,2 | MB-44682: Adding sleep for eph_bucket rebalance during warmup case | master | TAF | Status: MERGED | +2 | +1 |