Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Centos 7 64 bit; CB EE 7.0.0-4588
-
Untriaged
-
Centos 64-bit
-
-
1
-
Unknown
-
KV-Engine 2021-March
Description
Summary:
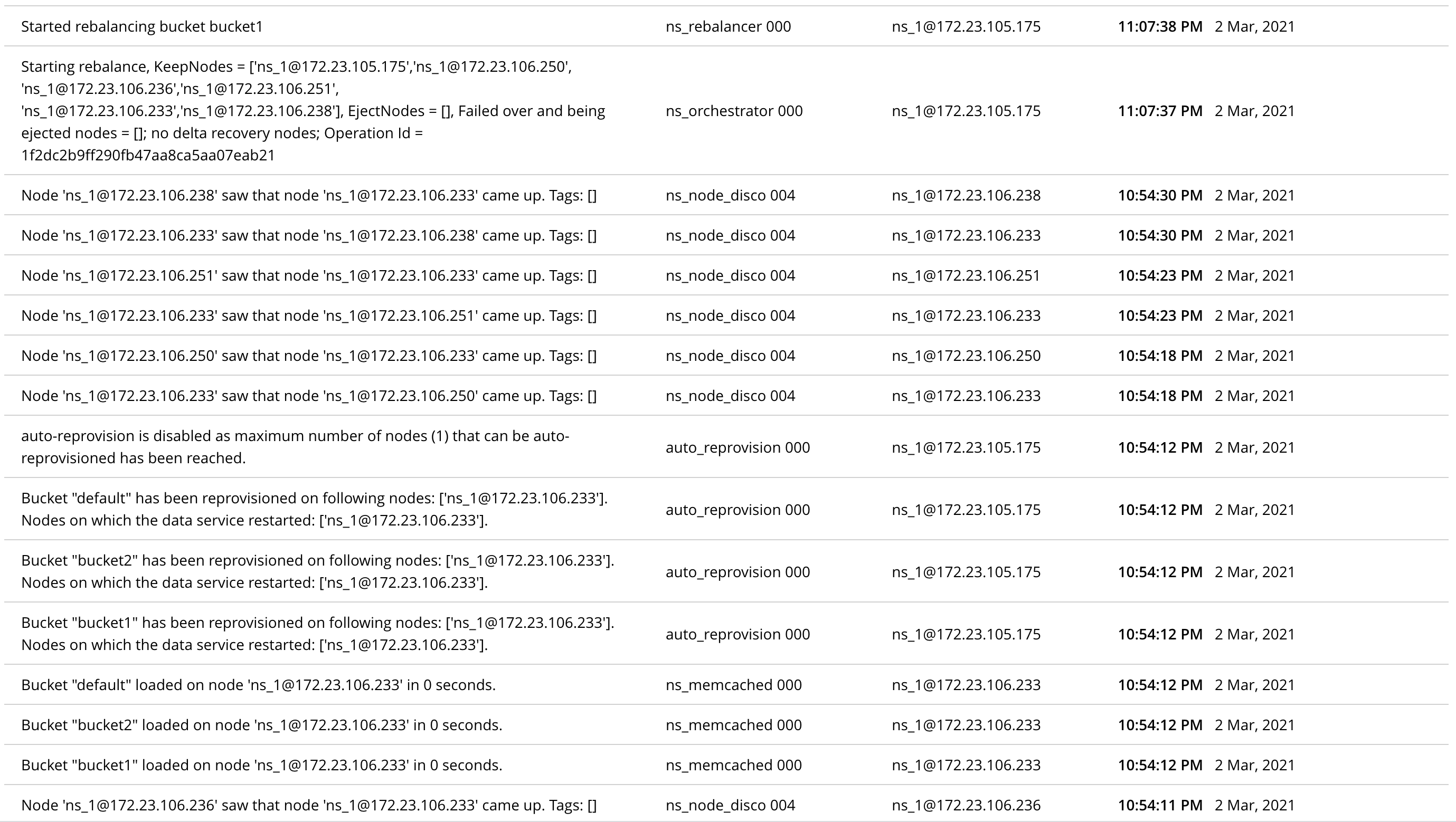
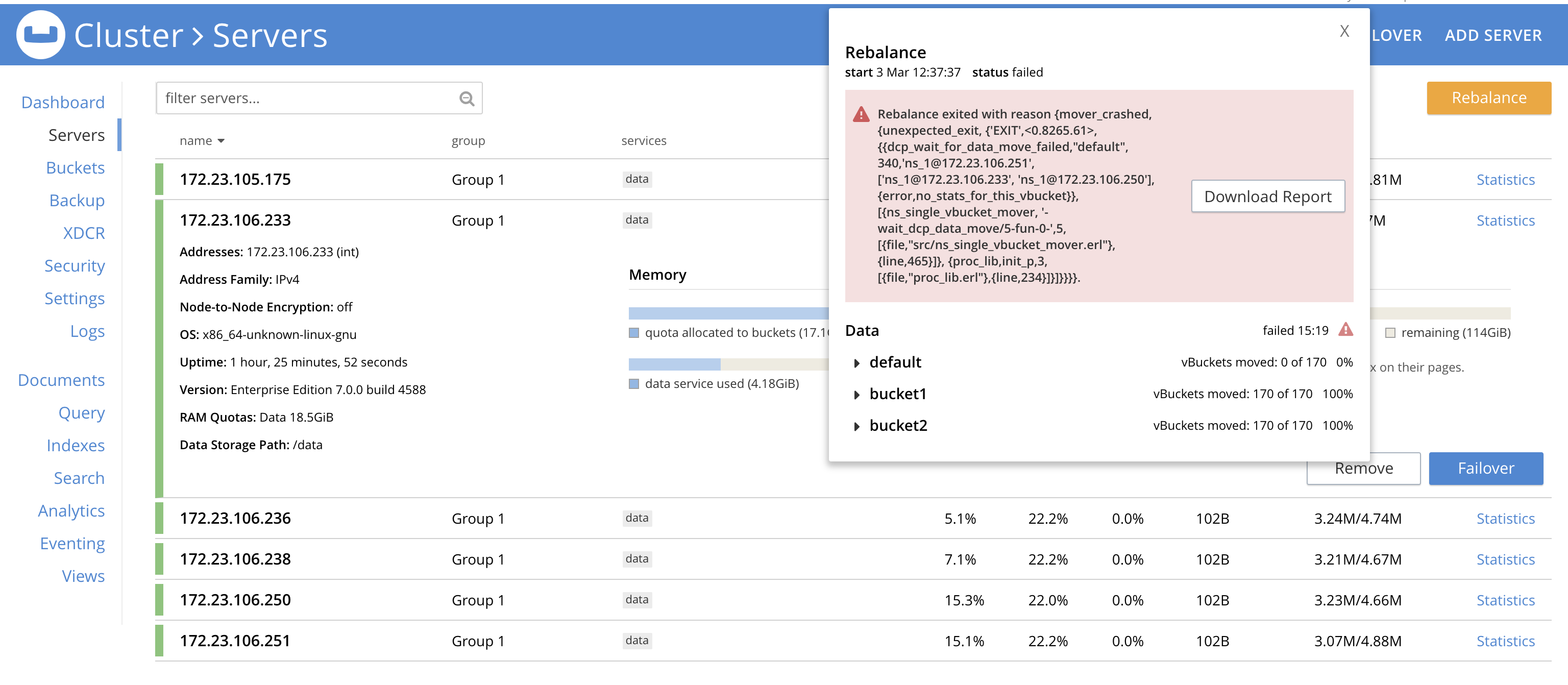
Rebalance in volume test failed at this step:
2021-03-02 22:52:40,614 | test | INFO | MainThread | [Collections_autofailover:test_volume_taf:289] Step 14: restart_machine -> Autoreprovision -> Rebalance
|
Buckets statistics at this step
2021-03-02 22:52:40,614 | test | INFO | MainThread | [table_view:display:72] Bucket statistics
|
+---------+-----------+----------+------------+-----+----------+--------------+-------------+-----------+
|
| Bucket | Type | Replicas | Durability | TTL | Items | RAM Quota | RAM Used | Disk Used |
|
+---------+-----------+----------+------------+-----+----------+--------------+-------------+-----------+
|
| bucket1 | ephemeral | 2 | none | 0 | 1500 | 1887436800 | 92255216 | 204 |
|
| bucket2 | ephemeral | 2 | none | 0 | 1500 | 1887436800 | 91652128 | 204 |
|
| default | ephemeral | 2 | none | 0 | 20000000 | 106954752000 | 20736031328 | 204 |
|
+---------+-----------+----------+------------+-----+----------+--------------+-------------+-----------+
|
Timeline for this step:
-> Induce failure (restart_machine) on 172.23.106.233
2021-03-02 22:53:01,595 | test | INFO | MainThread | [Collections_autofailover:rebalance_after_autofailover:103] Inducing failure restart_machine on nodes: [ip:172.23.106.233 port:8091 ssh_username:root]
|
-> Sleep and wait for autoreprovison and then rebalance
2021-03-02 23:02:28,339 | test | INFO | MainThread | [common_lib:sleep:22] Sleep 300 seconds. Reason: keep the cluster with the failure(autofailover test)/warmup to complete(autoreprovision test)
|
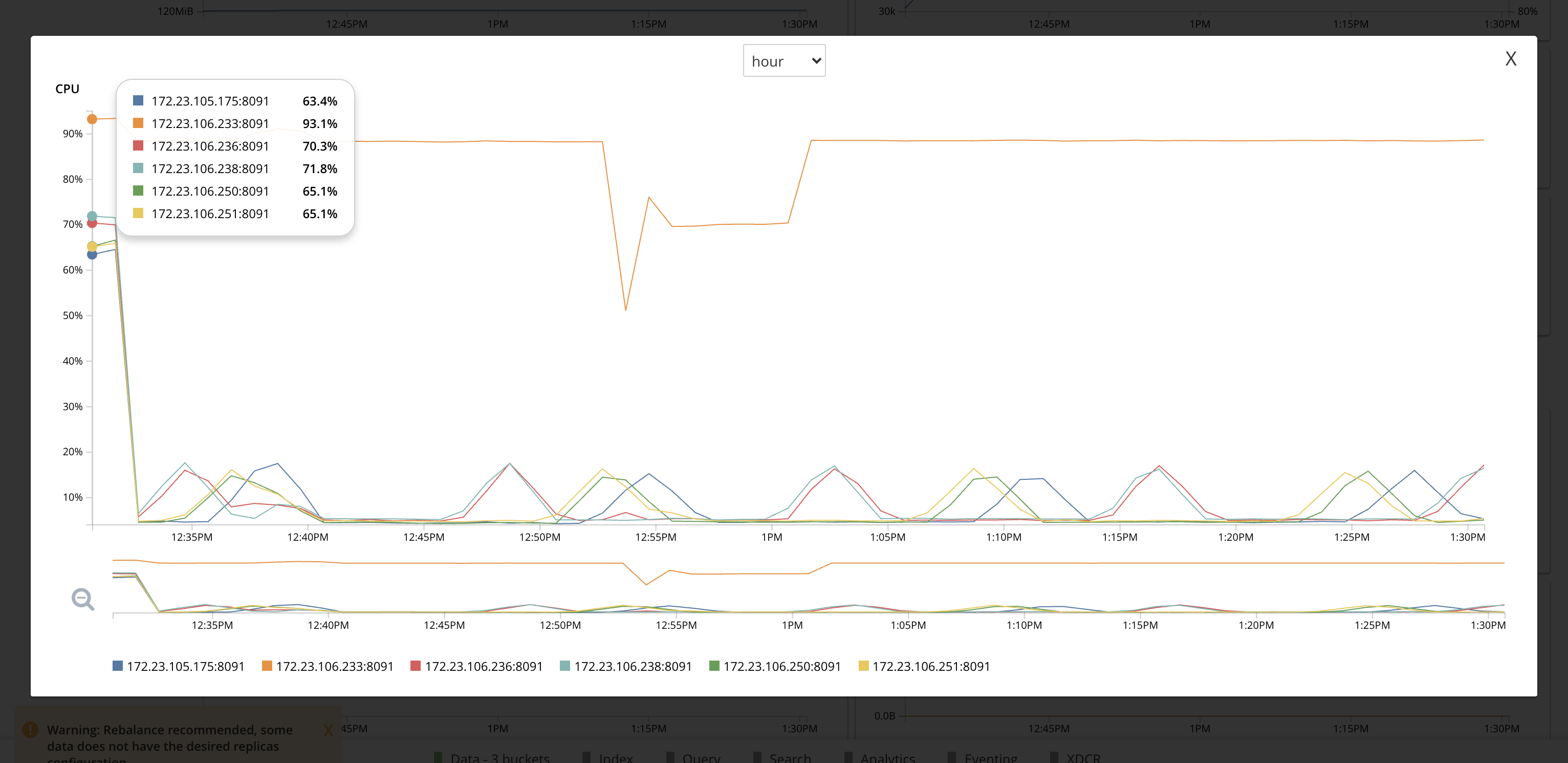
2021-03-02 23:07:37,821 | test | INFO | pool-1-thread-17 | [table_view:display:72] Rebalance Overview
|
+----------------+----------+-----------------------+---------------+--------------+
|
| Nodes | Services | Version | CPU | Status |
|
+----------------+----------+-----------------------+---------------+--------------+
|
| 172.23.105.175 | kv | 7.0.0-4588-enterprise | 15.7456472369 | Cluster node |
|
| 172.23.106.250 | kv | 7.0.0-4588-enterprise | 13.1572327044 | Cluster node |
|
| 172.23.106.236 | kv | 7.0.0-4588-enterprise | 8.60201511335 | Cluster node |
|
| 172.23.106.251 | kv | 7.0.0-4588-enterprise | 12.4278182275 | Cluster node |
|
| 172.23.106.233 | kv | 7.0.0-4588-enterprise | 88.3878241263 | Cluster node |
|
| 172.23.106.238 | kv | 7.0.0-4588-enterprise | 5.36836811667 | Cluster node |
|
+----------------+----------+-----------------------+---------------+--------------+
|
Observations
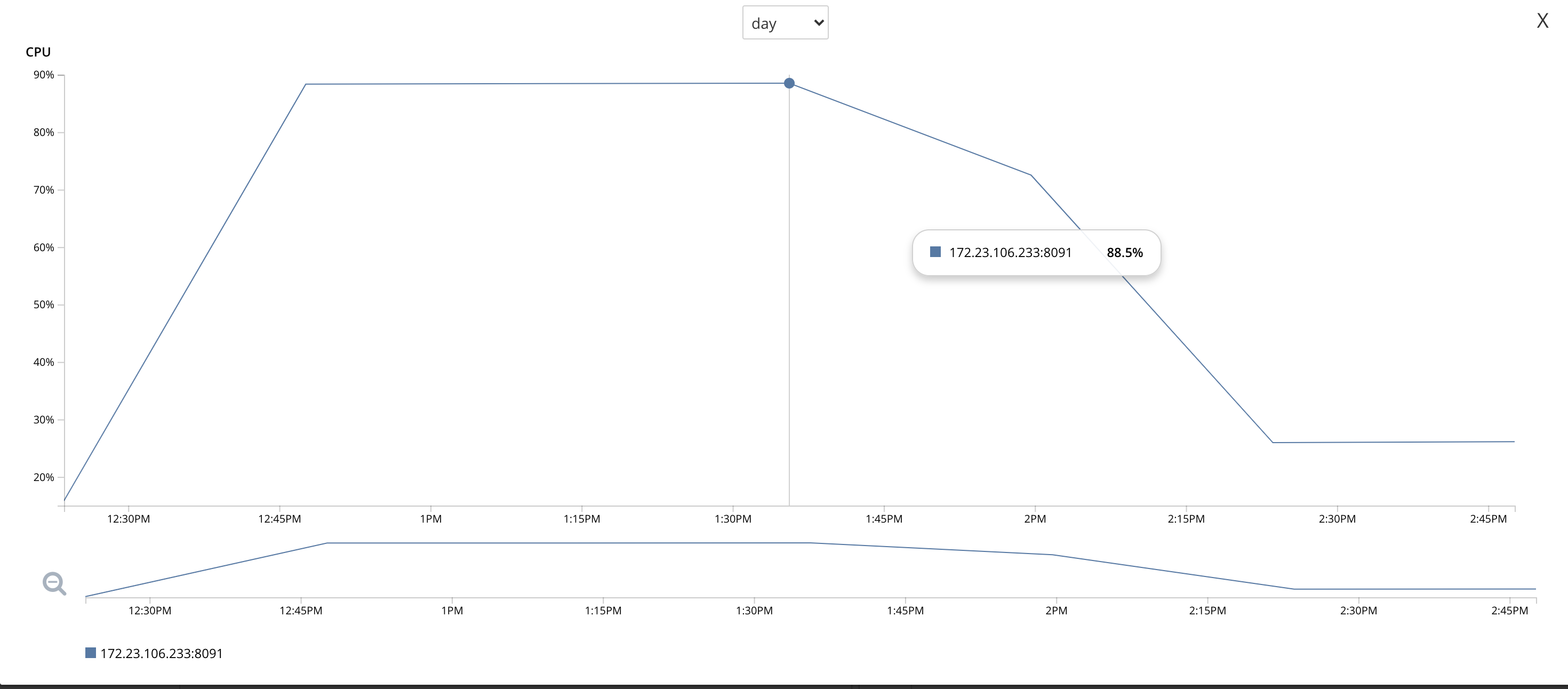
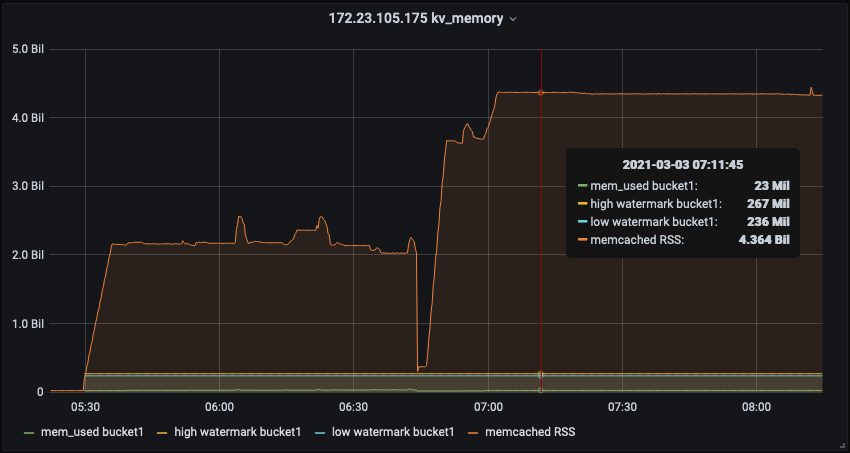
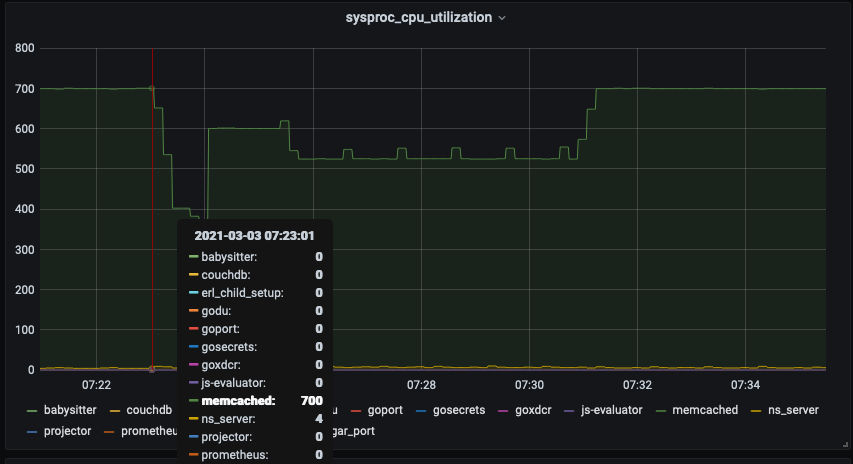
1. The CPU usage on .233 (node that was restarted) was unsually high ~88% at the time of rebalance. All other nodes had a very low CPU usage. (So rebalance failure could be be due unusual high cpu usage on .233)
2. Even after the rebalance failed, and so when the cluster was idle the node's cpu usage continued to remain high at 88% for some time
Running top command
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
2722 couchba+ 20 0 7939468 4.2g 9244 S 692.0 17.9 525:00.41 memcached
|
11867 couchba+ 20 0 3060060 23556 3224 S 8.3 0.1 0:00.25 beam.smp
|
2540 couchba+ 20 0 4586772 318860 4804 S 5.6 1.3 6:10.55 beam.smp
|
11877 couchba+ 20 0 4356 348 276 S 5.6 0.0 0:00.17 erl_child_setup
|
2676 couchba+ 20 0 972856 136808 21888 S 0.7 0.6 3:05.17 prometheus
|
2027 root 0 -20 4348 540 432 S 0.3 0.0 0:04.52 atopacctd
|
10740 root 20 0 156984 5872 4424 S 0.3 0.0 0:00.22 sshd
|
10787 couchba+ 20 0 6644 1340 952 S 0.3 0.0 0:00.09 goport
|
10793 couchba+ 20 0 283396 12472 4524 S 0.3 0.1 0:00.89 python3
|
1 root 20 0 193644 6684 4160 S 0.0 0.0 0:02.42 systemd
|
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
|
3. grep WARN memcached.log* | grep -v Slow | grep -v "The stream closed early because the conn was disconnected"
on .175 (looks similar to MB-44685)
2021-03-03T00:11:54.865556-08:00 WARNING (default) CheckpointManager::addStats: An error occurred while adding stats: std::bad_alloc
|
2021-03-03T00:11:54.865663-08:00 WARNING (default) CheckpointManager::addStats: An error occurred while adding stats: std::bad_alloc
|
2021-03-03T00:11:54.866164-08:00 WARNING (default) StatCheckpointVisitor::addCheckpointStat: error building stats: std::bad_alloc
|
2021-03-03T00:11:54.866393-08:00 WARNING (default) CheckpointManager::addStats: An error occurred while adding stats: std::bad_alloc
|
on .233
2021-03-02T23:23:49.809649-08:00 WARNING 95: [ {"ip":"127.0.0.1","port":43762} - {"ip":"127.0.0.1","port":11209} (<ud>@ns_server</ud>) ] dcp.mutation returned cb::engine_errc::disconnect
|