Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Centos 7 64 bit; CB EE 7.0.0-4721
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
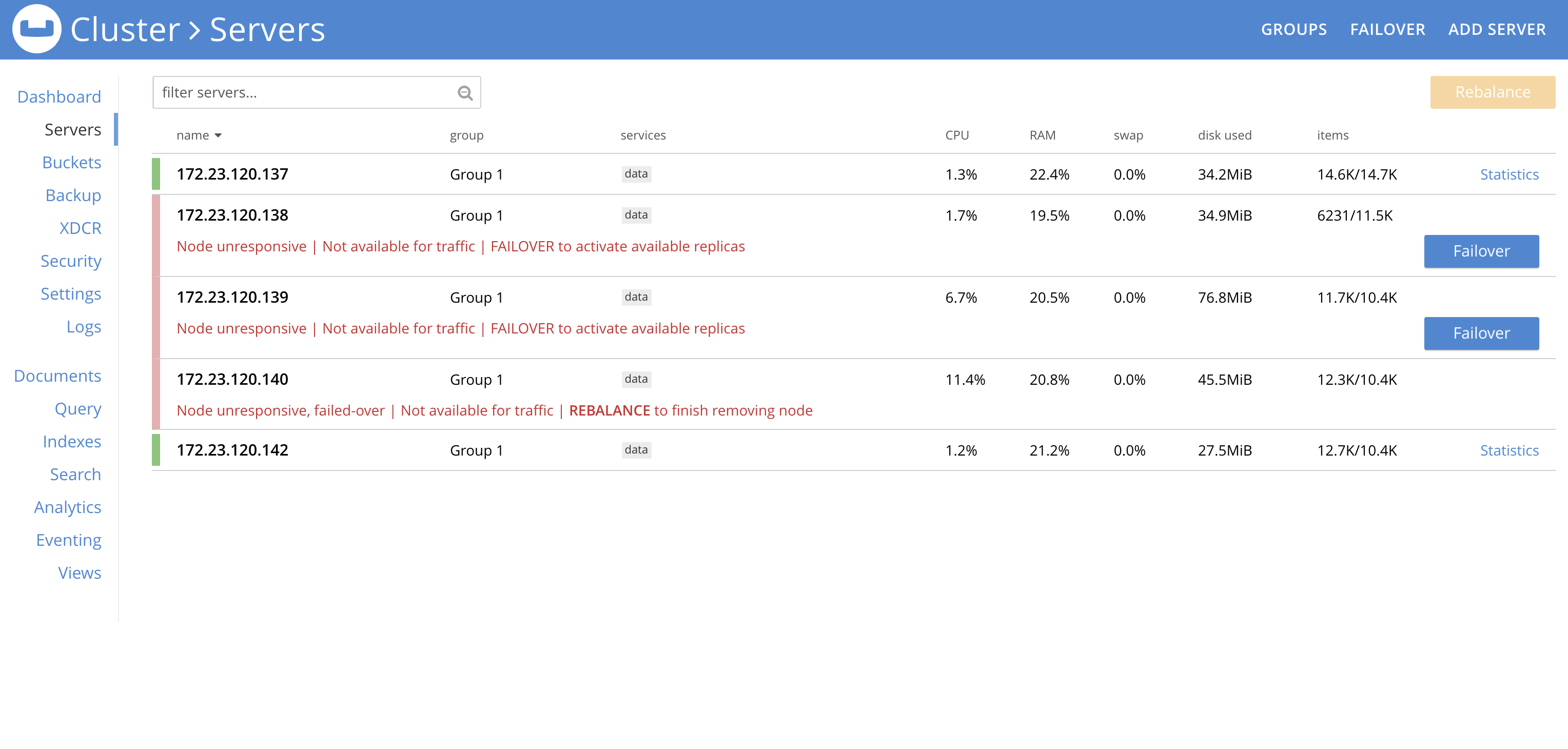
Steps to Reproduce:
1. Create a 5 node cluster: .137, .138, .139, .140, .142
2. Stop-server on .140 and when the node becomes unresponsive, fail it over, but don't rebalance it out yet.
3. Now stop server on .138, .139 nodes.
Now it appears that we can't get the unresponsive nodes from steps 2 and 3 out of the cluster.
We can't quorum failover .138 and .139 as we have another failed node: .140. So attempts to quorum failover will fail as
Unexpected server error: {error,
|
{aborted,
|
#{failed_peers =>
|
['ns_1@172.23.120.140',
|
* Connection #0 to host 172.23.120.137 left intact
|
'ns_1@172.23.120.138']}}}
|
There should be a way to potentially avoid this situation of cluster getting permanently stuck with this problem.