Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
7.0.0-4678
-
Untriaged
-
1
-
Unknown
Description
Description:
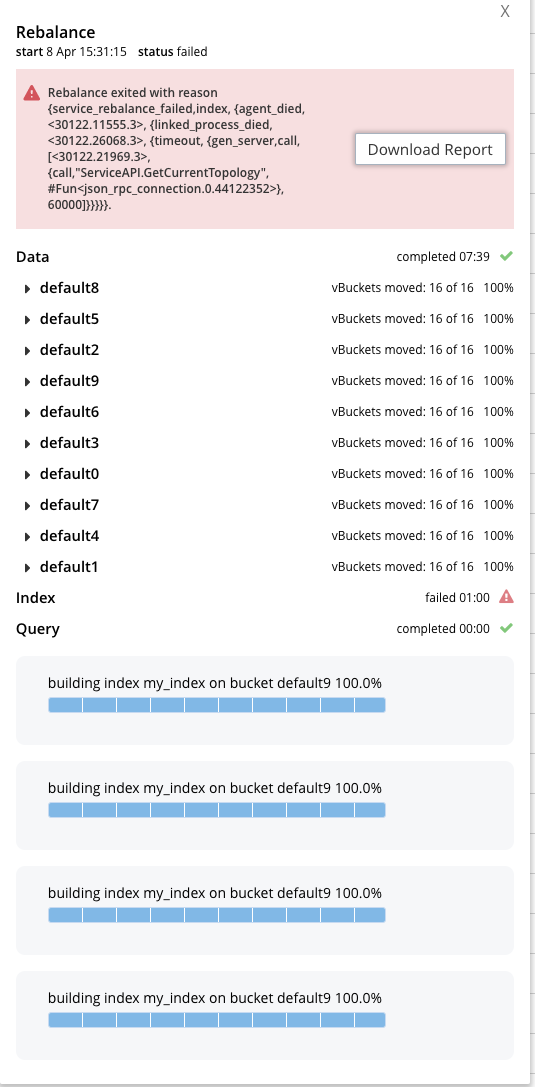
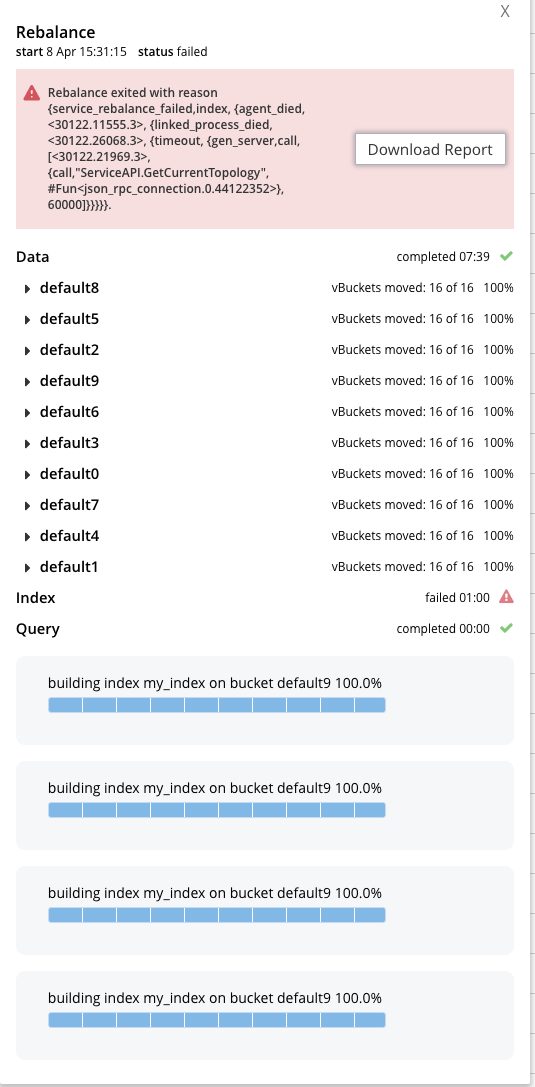
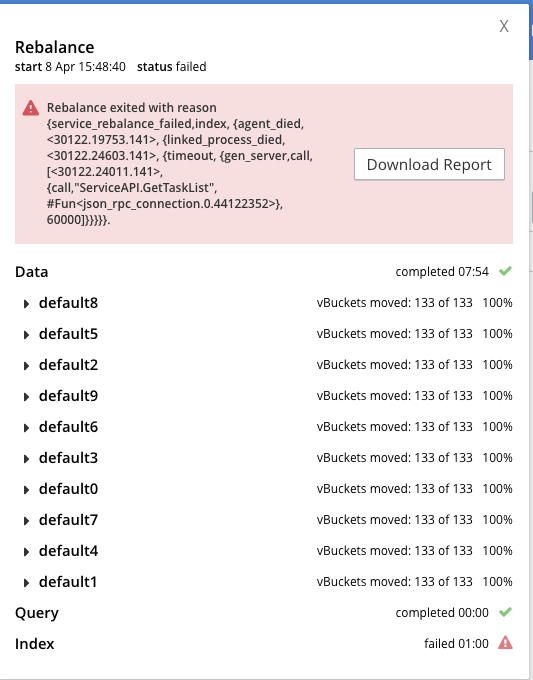
There was a rebalance failure during a full recovery from a graceful failover in the index service.
Cluster environment (130 nodes with a single service per node):
The cluster environment consists of 126 data nodes, 2 index nodes and 2 query nodes.
(The following was deduced/guessed with lots of help from Daniel Owen)
The master node: ns_1@ec2-3-85-225-46.compute-1.amazonaws.com![]()
The error message that was observed in the logs:
Reading the ns_server.debug.log of the master node:
|
ns_server.debug.log |
=========================CRASH REPORT=========================
|
crasher:
|
initial call: misc:'-spawn_monitor/1-fun-0-'/0
|
pid: <0.12685.507>
|
registered_name: 'service_rebalancer-index'
|
exception exit: {agent_died,<30122.11555.3>,
|
{linked_process_died,<30122.26068.3>,
|
{timeout,
|
{gen_server,call,
|
[<30122.21969.3>,
|
{call,"ServiceAPI.GetCurrentTopology",
|
#Fun<json_rpc_connection.0.44122352>},
|
60000]}}}}
|
in function service_rebalancer:run_rebalance/1 (src/service_rebalancer.erl, line 79)
|
ancestors: [<0.14018.497>]
|
message_queue_len: 0
|
messages: []
|
links: []
|
dictionary: []
|
trap_exit: false
|
status: running
|
heap_size: 4185
|
stack_size: 27
|
reductions: 8511
|
neighbours:
|
Looks like ns_server attempts to perform a RPC to ServiceAPI.GetCurrentTopology in secondary indexing (see: Secondary indexer source code).
Guess: Given the error message returned by ns_server and the screenshot indicating the rebalance failing exactly after one minute, perhaps this is a case of the cluster being too big and the timeout being too small.
What I expected to happen:
I expected the rebalance to succeed.
What was happening on the cluster before the rebalance failure:
There were 10 buckets with a 100 collections in each bucket with roughly ~350M documents per bucket (loaded by cbc-pillowfight).
There were several indexes of the form:
CREATE INDEX my_index ON default{bucket_no}._default.collection{collection_no}(Field_1, Field_2, Field_3);
|
(Roughly 20 to 30 indexes for bucket1 and 5 indexes for each bucket1 to bucket9)
There were lots of queries being executed via usage of cbc-n1qlback.
Logs:
Master [ns_server Coordinator, not GSI master] node (services: kv):
Index nodes (services index):
Query nodes (services query):
Rest of the logs (The complete set of logs for all 130 nodes)
https://issues.couchbase.com/browse/CBQE-6754
Supportal
https://supportal.couchbase.com/snapshot/f73d1c329f907432419f026362f25f09::0
130 node testing report
Final notes:
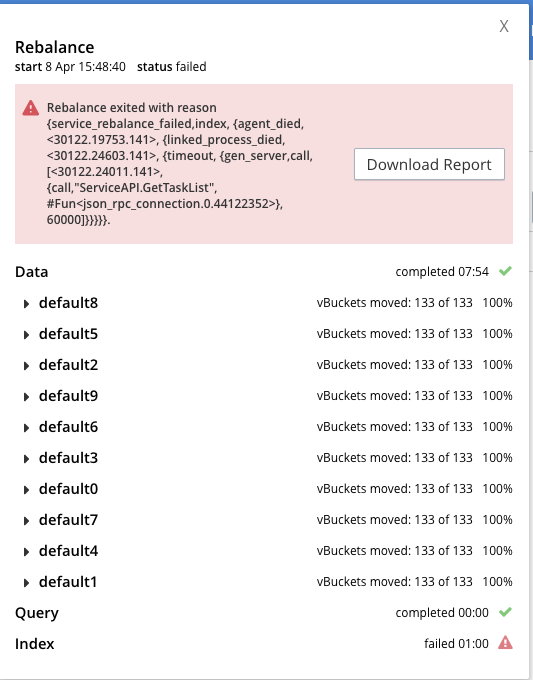
Following this failure, I attempted to remove 10 nodes from the cluster one of which was index node and the rebalance timed out in a similar manner after 1 minute (seems to be timing out on a different RPC this time).
Attachments
Issue Links
- backports to
-
-
- Resolved
-