Description
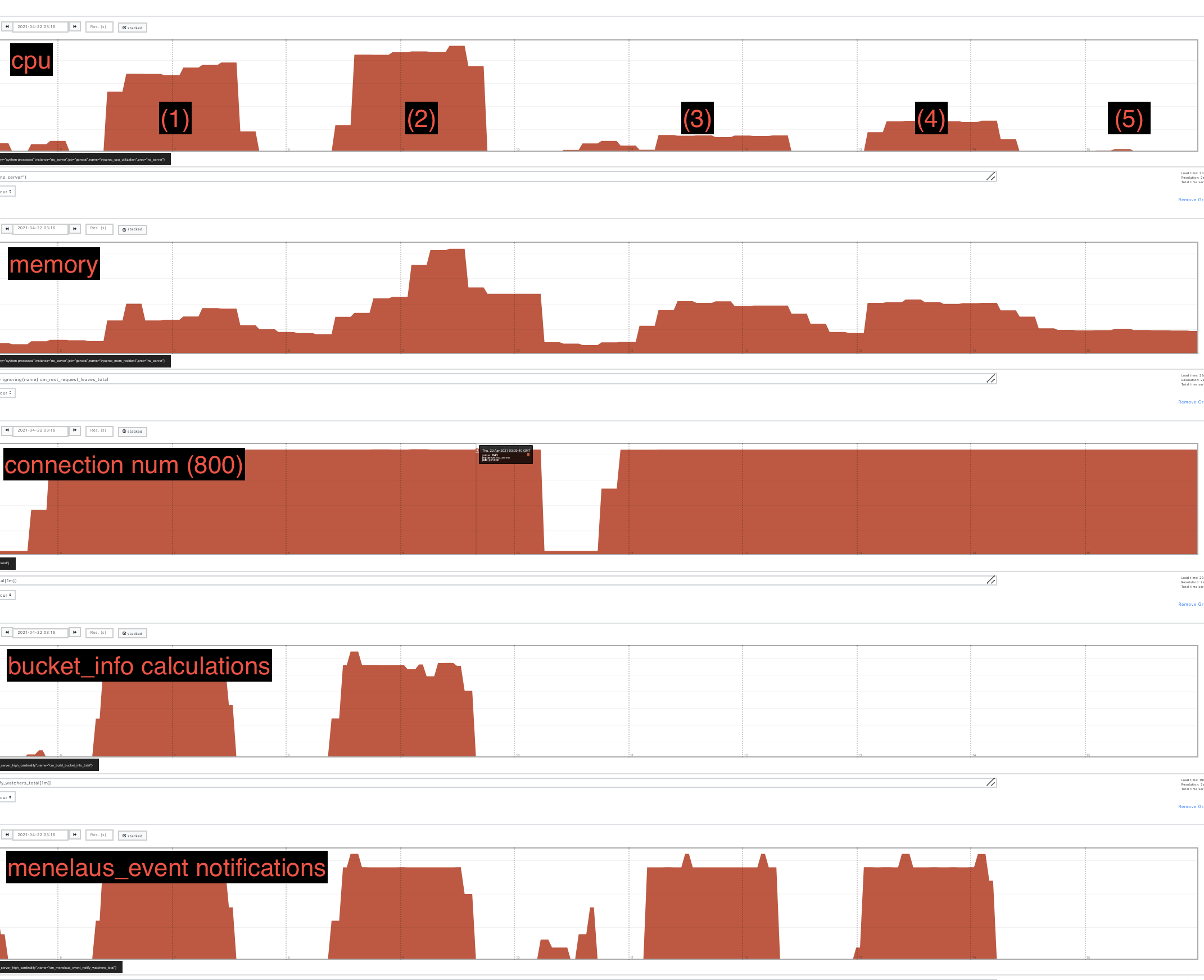
As discussed in MB-45769, the streaming bucket info endpoint (and its terse counterpart) are hibernated processes that are woken up when certain events fire. When these processes are woken up, they recompute what is considered to be the stable part of the payload and compare it to the last stable part that was calculated. If these are the same, the process goes back to sleep; if not the process computes the full payload and sends it to the client.
Most of the events that these hibernated processes listen to are either appropriate (e.g. a change in the bucket configuration) or relatively rare (e.g. a change in the list of nodes in the cluster.) However, a change in the tasks that are running across a large cluster can be neither as under constant load compaction tasks can be running constantly and compaction tasks don't affect bucket info payloads.
I think we should interpret this bug as (hopefully) making a smallish change to not excessively recompute buckets streaming payloads and not as an improvement to largely rewrite all of the eventing and streaming handler piece. (Perhaps we could do something like forwarding the actual events to hibernated processes and allow them to examine the event to determine whether or not the payload should be recomputed?)
Attachments
Issue Links
- relates to
-
MB-45769 Rebalance repeatedly fails during upgrade with Rebalance exited with reason {pre_rebalance_janitor_run_failed,"DISTRICT", {error, {config_sync_failed,push,
-

- Closed
-
| For Gerrit Dashboard: MB-45822 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 151912,3 | MB-45822: Cache build_streaming_info in order to avoid ... | master | ns_server | Status: MERGED | +2 | +1 |