Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
Cheshire-Cat
-
6.6.2-9588 ---> 7.0.0-5006
-
Untriaged
-
Windows 64-bit
-
1
-
No
Description
I was basically left with a 6.6.2 cluster after I tried this :- https://issues.couchbase.com/browse/MB-45061?focusedCommentId=494167&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-494167
Added 2 more 6.6.2 nodes to create a 4 node 6.6.2 cluster.
I had to move the cluster to 7.0.0 to run other tests I had planned. So decide to upgrade of the cluster using swap rebalance.
Added one 7.0.0 node and removed one 6.6.2 node and started a swap rebalance.
1st swap rebalance
Node ns_1@172.23.120.113 joined cluster
|
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.117','ns_1@172.23.120.144'], EjectNodes = ['ns_1@172.23.121.81'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = 807dc28d4915b7f8c8e3b051618ad1dd
|
Rebalance completed successfully.
|
Rebalance Operation Id = 807dc28d4915b7f8c8e3b051618ad1dd
|
It worked fine.
Now started a 2nd swap rebalance. It fails as shown below.
2nd swap rebalance
Node ns_1@172.23.121.81 joined cluster
|
|
|
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.144','ns_1@172.23.121.81'], EjectNodes = ['ns_1@172.23.120.117'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = aea79972c0a135de44cce8b57de12deb
|
Rebalance exited with reason {prepare_rebalance_failed,
|
{error,
|
{failed_nodes,
|
[{'ns_1@172.23.121.81',{error,timeout}}]}}}.
|
Rebalance Operation Id = aea79972c0a135de44cce8b57de12deb
|
Then I try to do proceed to retry failed rebalances. All of them fail.
Retry of failed rebalance 1
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.144','ns_1@172.23.121.81'], EjectNodes = ['ns_1@172.23.120.117'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = da1e6a490afc4381b399c240a7c9033a
|
Rebalance exited with reason {prepare_rebalance_failed,
|
{error,
|
{failed_nodes,
|
[{'ns_1@172.23.121.81',{error,timeout}}]}}}.
|
Rebalance Operation Id = da1e6a490afc4381b399c240a7c9033a
|
Retry of failed rebalance 2
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.144','ns_1@172.23.121.81'], EjectNodes = ['ns_1@172.23.120.117'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = 67efe2fba1dd506a4ee4723396a1435c
|
Rebalance exited with reason {{badmatch,
|
{leader_activities_error,
|
{default,rebalance},
|
{no_quorum,
|
[{required_quorum,majority},
|
{leases,['ns_1@172.23.121.81']}]}}},
|
[{ns_rebalancer,rebalance,5,
|
[{file,"src/ns_rebalancer.erl"},{line,484}]},
|
{proc_lib,init_p_do_apply,3,
|
[{file,"proc_lib.erl"},{line,249}]}]}.
|
Rebalance Operation Id = 67efe2fba1dd506a4ee4723396a1435c
|
Retry of failed rebalance 3
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.117','ns_1@172.23.120.144',
|
'ns_1@172.23.121.81'], EjectNodes = [], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = c5ff54913d49cc70e8950c0b61b82d1c
|
Rebalance exited with reason {prepare_rebalance_failed,
|
{error,
|
{failed_nodes,
|
[{'ns_1@172.23.121.81',{error,timeout}}]}}}.
|
Rebalance Operation Id = c5ff54913d49cc70e8950c0b61b82d1c
|
Rebalance exited with reason {prepare_rebalance_failed,
|
{error,
|
{failed_nodes,
|
[{'ns_1@172.23.121.81',{error,timeout}}]}}}.
|
Rebalance Operation Id = c5ff54913d49cc70e8950c0b61b82d1c
|
Retry of failed rebalance 4
Starting rebalance, KeepNodes = ['ns_1@172.23.120.100','ns_1@172.23.120.113',
|
'ns_1@172.23.120.144','ns_1@172.23.121.81'], EjectNodes = ['ns_1@172.23.120.117'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = 04ba60d7c5abdb6ba8b8235c2568f9d2
|
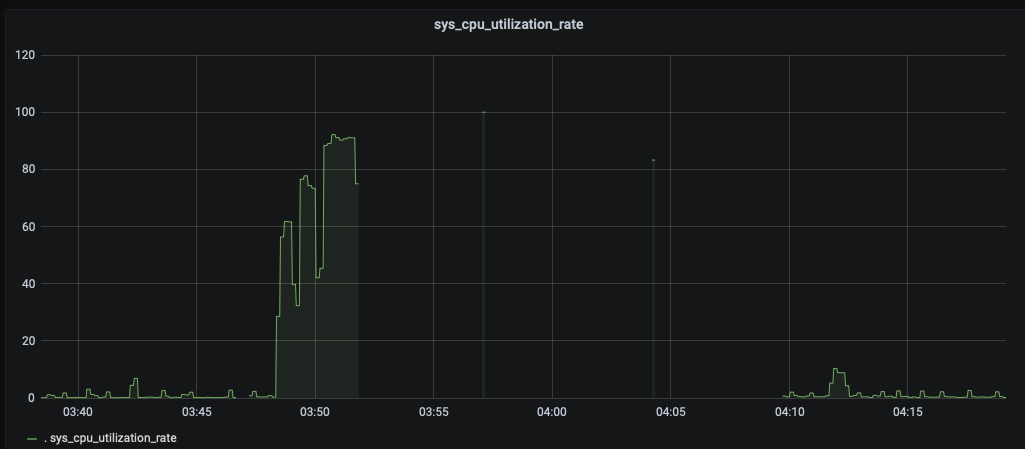
At this point auto failover kicks in and aborts rebalance as shown below
Rebalance interrupted due to auto-failover of nodes ['ns_1@172.23.120.113'].
|
Rebalance Operation Id = 04ba60d7c5abdb6ba8b8235c2568f9d2
|
We also see exits on 172.23.120.113 as shown below
Service 'ns_server' exited with status 1. Restarting. Messages:
|
2021-04-22 03:57:33.932000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{auto_connect,'ns_1@172.23.121.81',{4,#Ref<0.3863052137.397541380.71659>}}}}
|
2021-04-22 03:57:36.348000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{passive_cnct,'ns_1@172.23.121.81'}}}
|
2021-04-22 03:57:40.944000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{'EXIT',<0.20072.17>,setup_timer_timeout}}}
|
2021-04-22 03:57:40.944000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{net_kernel,1054,nodedown,'ns_1@172.23.121.81'}}}
|
2021-04-22 03:57:40.944000
|
args: ['ns_1@172.23.120.113','ns_1@172.23.121.81']
|
format: "global: ~w failed to connect to ~w\n"
|
label: {error_logger,warning_msg}
|
2021-04-22 03:57:40.944000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{disconnect,'ns_1@172.23.121.81'}}}
|
2021-04-22 03:57:47.960000 std_info #{label=>{error_logger,info_report},report=>{net_kernel,{'EXIT',<0.20636.17>,setup_timer_timeout}}}
|
done
|
[os_mon] win32 supervisor port (win32sysinfo): Erlang has closed
|
cbcollect_info attached.
On 172.23.120.113 we see 5d7281f3-5171-4afe-8673-38f95f1a185e.dmp+
Administrator@WIN-1T98IIFH727 /cygdrive/c/Program Files/Couchbase/Server/var/lib/couchbase/crash
|
$ ls -lrt
|
total 264
|
-rwxrwx---+ 1 Administrators SYSTEM 267165 Apr 22 04:09 5d7281f3-5171-4afe-8673-38f95f1a185e.dmp
|
grep CRITICAL on 172.23.120.113
Administrator@WIN-1T98IIFH727 /cygdrive/c/Program Files/Couchbase/Server/var/lib/couchbase/logs
|
$ grep CRITICAL *
|
memcached.log.000000.txt:2021-04-22T04:09:04.737596-07:00 CRITICAL Breakpad caught a crash (Couchbase version 7.0.0-5006). Writing crash dump to c:/Program Files/Couchbase/Server/var/lib/couchbase/crash\5d7281f3-5171-4afe-8673-38f95f1a185e.dmp before terminating.
|
memcached.log.000000.txt:2021-04-22T04:09:04.737651-07:00 CRITICAL Stack backtrace of crashed thread:
|
memcached.log.000000.txt:2021-04-22T04:09:04.739692-07:00 CRITICAL #0 c:\Program Files\Couchbase\Server\bin\memcached.exe(magma::Magma::GetKVStoreUserStats+9742738) [0x00007FF7616AEE6B]
|
memcached.log.000000.txt:2021-04-22T04:09:04.739744-07:00 CRITICAL #1 c:\Program Files\Couchbase\Server\bin\memcached.exe(magma::Magma::GetKVStoreUserStats+9913528) [0x00007FF7616D8991]
|
memcached.log.000000.txt:2021-04-22T04:09:04.739778-07:00 CRITICAL #2 C:\Windows\System32\KERNEL32.DLL(BaseThreadInitThunk+20) [0x00007FFF4C9C84D4]
|
memcached.log.000000.txt:2021-04-22T04:09:04.739819-07:00 CRITICAL #3 C:\Windows\SYSTEM32\ntdll.dll(RtlUserThreadStart+33) [0x00007FFF4EBFE8B1]
|
grep: rebalance: Is a directory
|
cbcollect_info attached.
Strangely I see magma::Magma::GetKVStoreUserStats in the bt, but this is couchbase bucket.
Another one that had this anomaly was MB-45825.
Attachments
Issue Links
- is duplicated by
-
-
- Closed
-