Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Enterprise Edition 7.0.0 build 5060
-
Untriaged
-
Windows 64-bit
-
-
1
-
Unknown
-
Tools: CC Final Sprint
Description
Build: 7.0.0 - 5060
Steps:
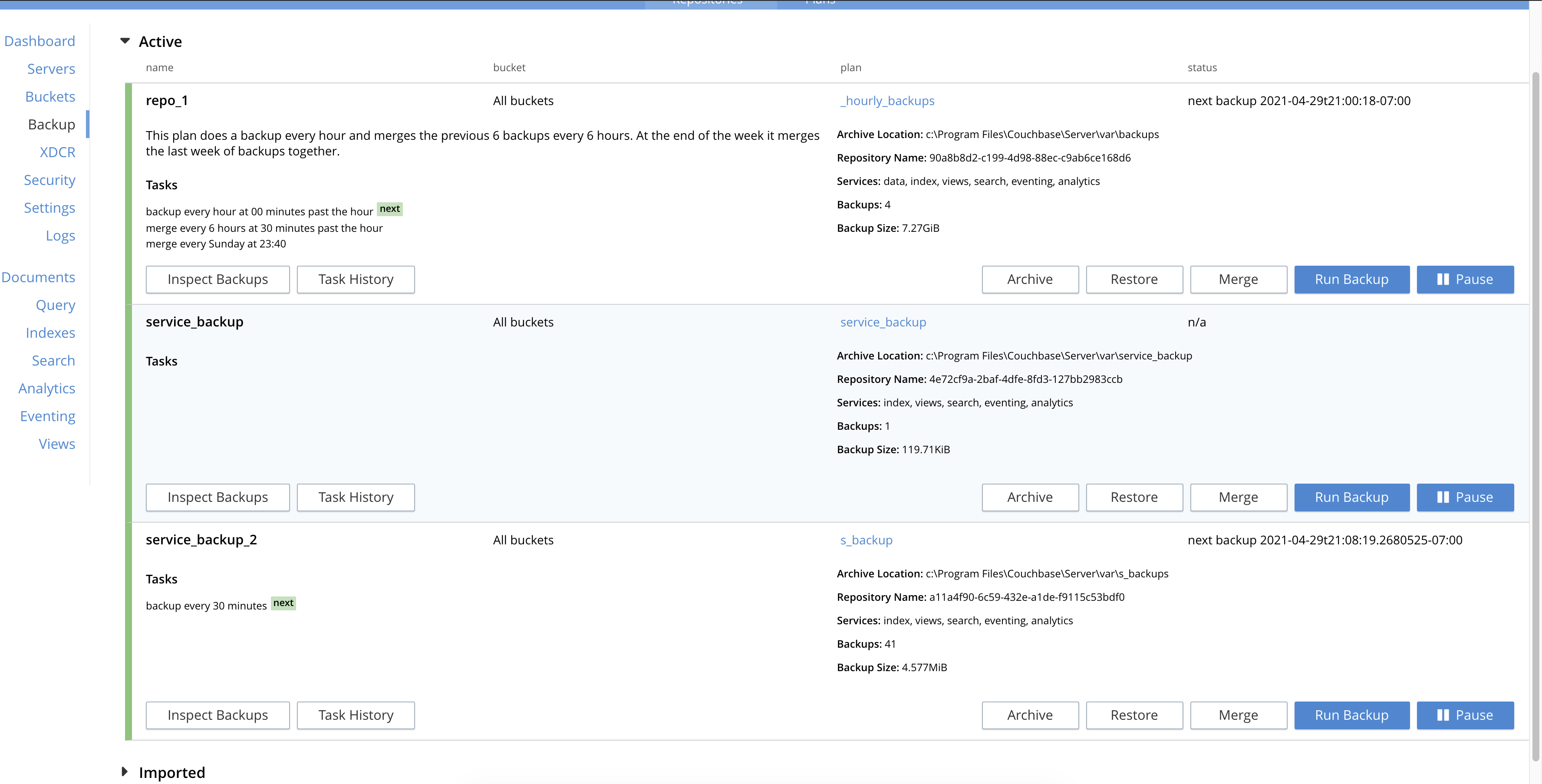
- Cluster with index, cbas, fts and eventing services actively working on bucket data
- Constantly running rebalances (in/out/swap) of kv / n1ql:index / cbas nodes
- Scheduled backup on full cluster and only_services as two tasks.
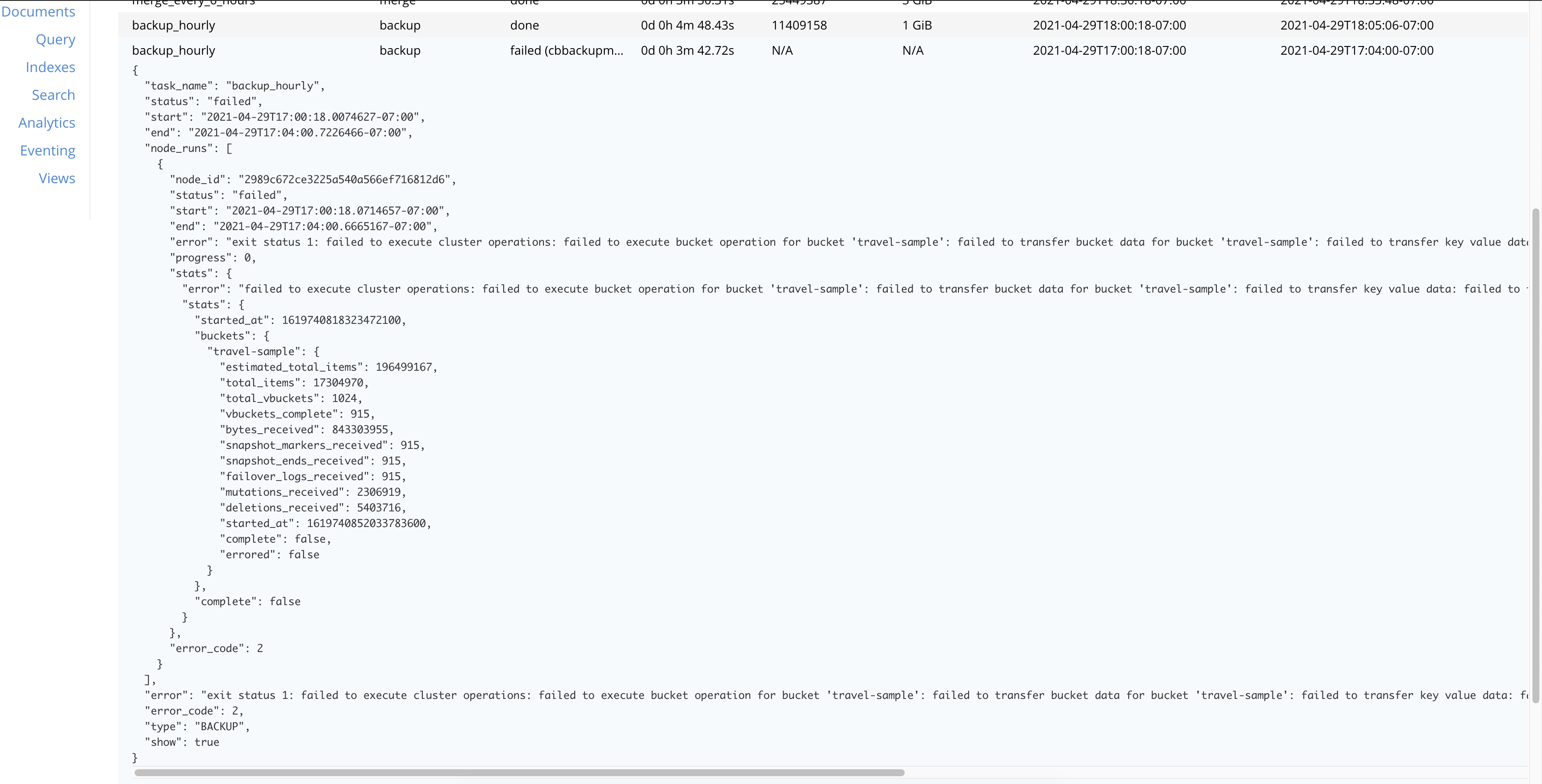
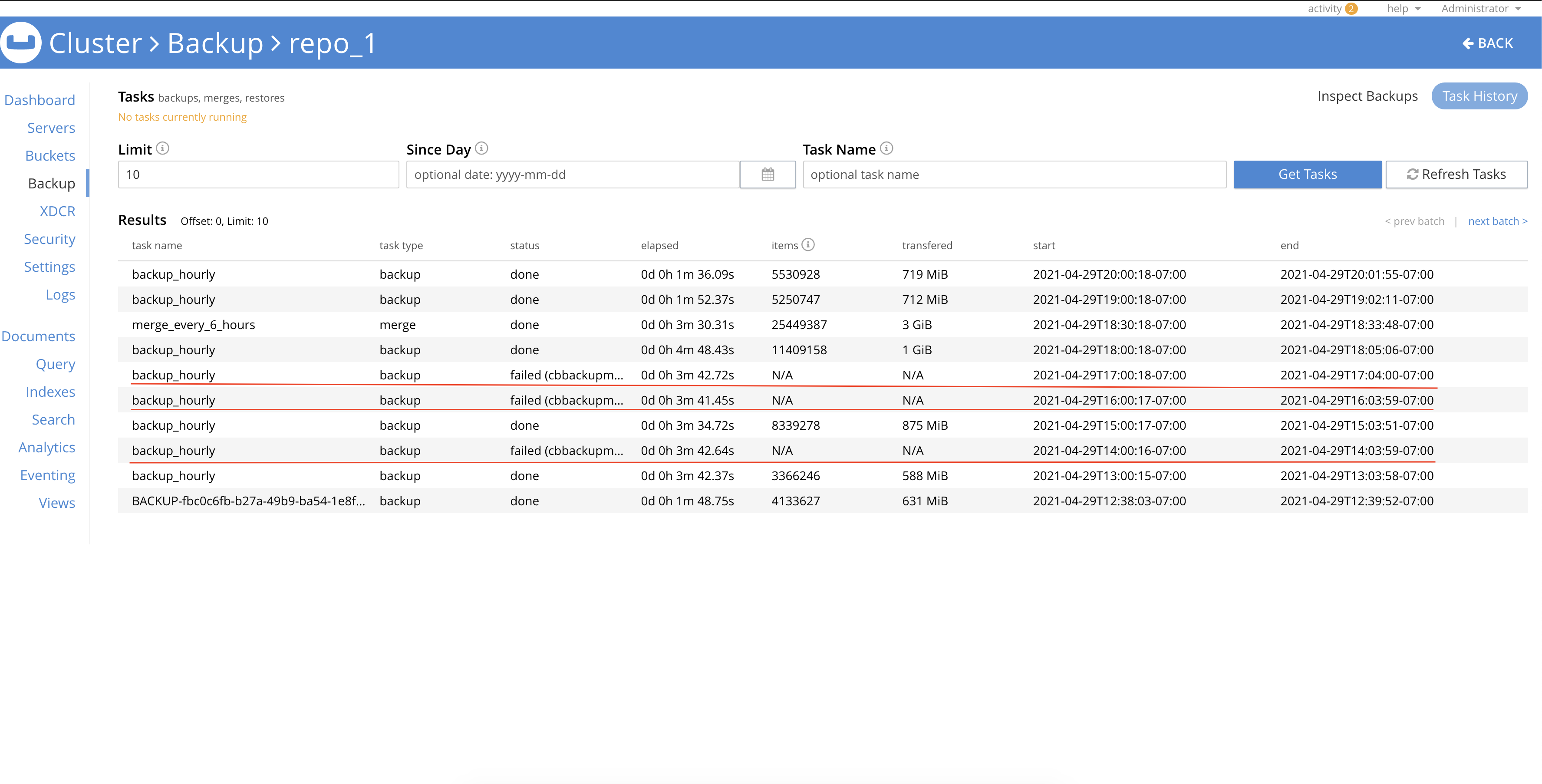
Observing few cluster backup tasks failed due to reason "Stream request for vBucket 365 timed out after 3m0s"
"node_runs": [
|
{
|
"node_id": "2989c672ce3225a540a566ef716812d6",
|
"status": "failed",
|
"start": "2021-04-29T17:00:18.0714657-07:00",
|
"end": "2021-04-29T17:04:00.6665167-07:00",
|
"error": "exit status 1: failed to execute cluster operations: failed to execute bucket operation for bucket 'travel-sample': failed to transfer bucket data for bucket 'travel-sample': failed to transfer key value data: failed to transfer key value data: failed to open stream: failed to stream vBucket 365: client received unexpected error 'Stream request for vBucket 365 timed out after 3m0s'",
|
"progress": 0,
|
"stats": {
|
"error": "failed to execute cluster operations: failed to execute bucket operation for bucket 'travel-sample': failed to transfer bucket data for bucket 'travel-sample': failed to transfer key value data: failed to transfer key value data: failed to open stream: failed to stream vBucket 365: client received unexpected error 'Stream request for vBucket 365 timed out after 3m0s'",
|
"stats": {
|
"started_at": 1619740818323472100,
|
"buckets": {
|
"travel-sample": {
|
"estimated_total_items": 196499167,
|
"total_items": 17304970,
|
"total_vbuckets": 1024,
|
"vbuckets_complete": 915,
|
"bytes_received": 843303955,
|
"snapshot_markers_received": 915,
|
"snapshot_ends_received": 915,
|
"failover_logs_received": 915,
|
"mutations_received": 2306919,
|
"deletions_received": 5403716,
|
"started_at": 1619740852033783600,
|
"complete": false,
|
"errored": false
|
}
|
},
|
"complete": false
|
}
|
},
|
"error_code": 2
|
}
|
],
|
|
Note: Cluster has only one backup node (172.23.136.115)
Logs from backup folder: https://cb-engineering.s3.amazonaws.com/cbbackup_failure/backup_logs.tar.gz
Attachments
{kind=link}
{kind=link}
{kind=link}
Issue Links
- relates to
-
-
- Closed
-