Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
6.6.2-9588 -> 7.0.0-5275
-
Untriaged
-
Centos 64-bit
-
1
-
Yes
Description
Script to Repro
1. Run the following 6.6.2 longevity test for 3-4 days. We will have 27 node cluster at the end of it.
./sequoia -client 172.23.96.162:2375 -provider file:centos_third_cluster.yml -test tests/integration/test_allFeatures_madhatter_durability.yml -scope tests/integration/scope_Xattrs_Madhatter.yml -scale 3 -repeat 0 -log_level 0 -version 6.6.2-9588 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
2. Run the script create_drop.sh![]() on 6.6.2 nodes on the cluster. And this was run on the 7.0.0 nodes as well that will be brought into the cluster using swap rebalance for upgrade
on 6.6.2 nodes on the cluster. And this was run on the 7.0.0 nodes as well that will be brought into the cluster using swap rebalance for upgrade
3. Swap rebalance 6(1 of each service) 6.6.2 nodes with 7.0.0 nodes.
4. Graceful failover 6 node (1 of each service), upgrade, do a recovery and start rebalance.
5. Graceful failover 6 node (1 of each service), upgrade, do a recovery and start rebalance.
Rebalance at step 5 failed.
ns_1@172.23.110.76 8:55:11 AM 7 Jun, 2021
Starting rebalance, KeepNodes = ['ns_1@172.23.104.15','ns_1@172.23.104.214',
|
'ns_1@172.23.104.232','ns_1@172.23.104.244',
|
'ns_1@172.23.104.245','ns_1@172.23.105.102',
|
'ns_1@172.23.105.109','ns_1@172.23.105.112',
|
'ns_1@172.23.105.118','ns_1@172.23.105.164',
|
'ns_1@172.23.105.206','ns_1@172.23.105.210',
|
'ns_1@172.23.105.25','ns_1@172.23.105.61',
|
'ns_1@172.23.105.62','ns_1@172.23.105.90',
|
'ns_1@172.23.105.93','ns_1@172.23.106.117',
|
'ns_1@172.23.106.191','ns_1@172.23.106.207',
|
'ns_1@172.23.106.225','ns_1@172.23.106.232',
|
'ns_1@172.23.106.239','ns_1@172.23.106.246',
|
'ns_1@172.23.106.37','ns_1@172.23.106.54',
|
'ns_1@172.23.110.76'], EjectNodes = [], Failed over and being ejected nodes = [], Delta recovery nodes = ['ns_1@172.23.105.61'], Delta recovery buckets = all; Operation Id = aa7bf1ba9bd044e1f30ef2d87c58af56
|
ns_1@172.23.110.76 9:10:51 AM 7 Jun, 2021
Rebalance exited with reason {mover_crashed,
|
{unexpected_exit,
|
{'EXIT',<0.31594.230>,
|
{failed_to_update_vbucket_map,"default",654,
|
{error,
|
[{'ns_1@172.23.106.239',
|
{exit,
|
{{nodedown,'ns_1@172.23.106.239'},
|
{gen_server,call,
|
[{ns_config_rep,'ns_1@172.23.106.239'},
|
synchronize_everything,
|
infinity]}}}}]}}}}}.
|
Rebalance Operation Id = aa7bf1ba9bd044e1f30ef2d87c58af56
|
ns_1@172.23.106.239 9:10:57 AM 7 Jun, 2021
Service 'ns_server' exited with status 1. Restarting. Messages:
|
working as port
|
99626: Booted. Waiting for shutdown request
|
working as port
|
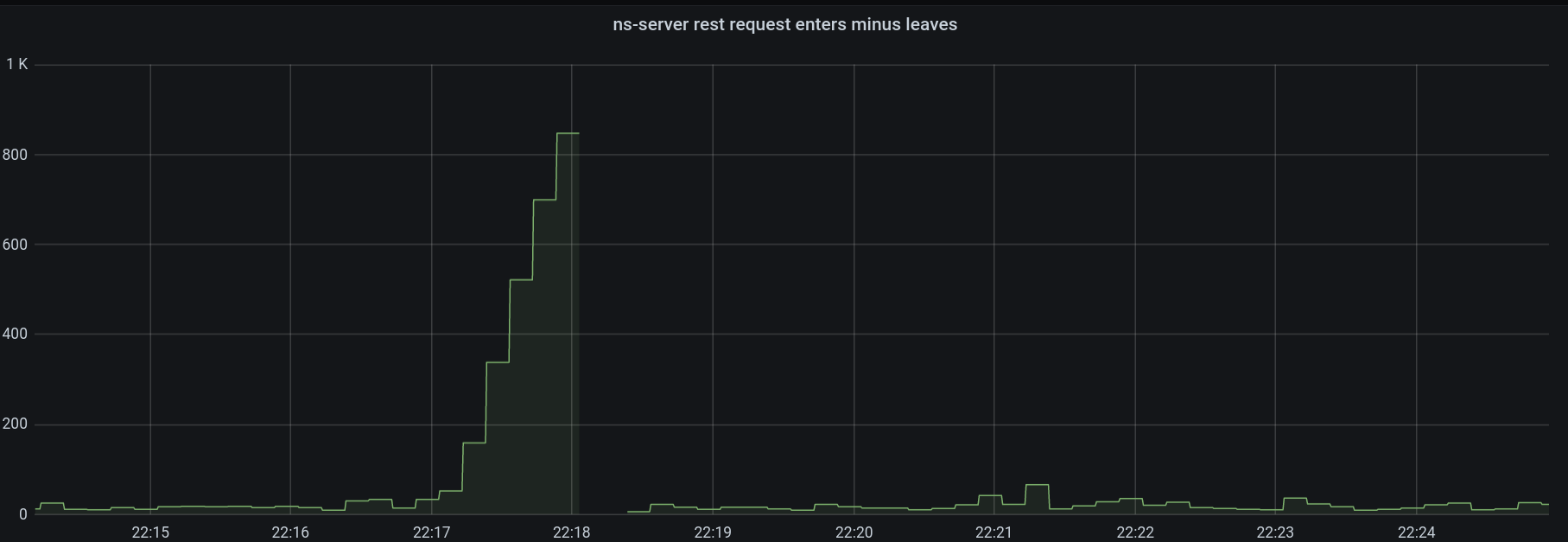
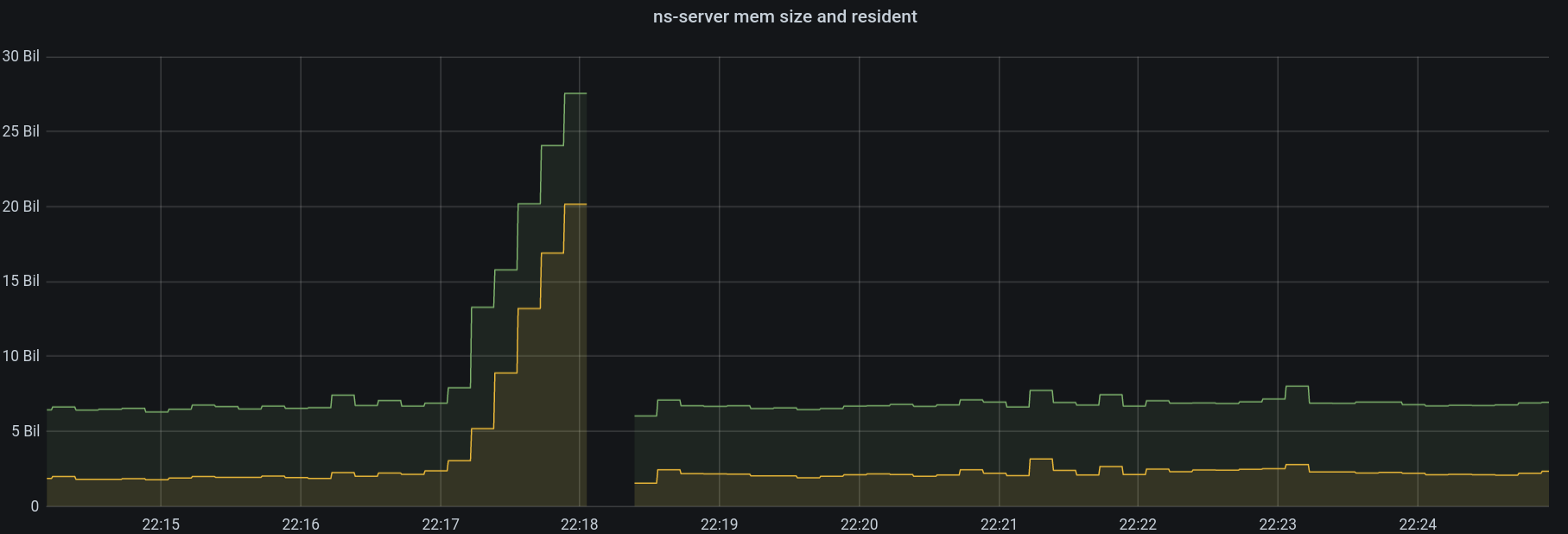
eheap_alloc: Cannot allocate 11753808384 bytes of memory (of type "old_heap").
|
|
|
Crash dump is being written to: erl_crash.dump.1623048781.99514.ns_server...done
|
[os_mon] cpu supervisor port (cpu_sup): Erlang has closed
|
[os_mon] memory supervisor port (memsup): Erlang has closed
|
Looking at the time of crash which is almost at the same time as the rebalance failure, looks like ns-serv crash is the reason for the rebalance failure. Assigning it to the ns_server team.
Also , much later we notice one more ns_serv crash.
ns_1@172.23.106.239 11:22:09 AM 7 Jun, 2021
Service 'ns_server' exited with status 137. Restarting. Messages:
|
working as port
|
88751: Booted. Waiting for shutdown request
|
[os_mon] memory supervisor port (memsup): Erlang has closed
|
[os_mon] cpu supervisor port (cpu_sup): Erlang has closed
|
cbcollect_info attached. This was not seen on last system test upgrade we had from 6.6.2-9588 -> 7.0.0-5226
Attachments
Issue Links
- is duplicated by
-
-

- Closed
-