Description
The timeout for running p2p protocol before each pipeline start is 60 seconds. That may not be enough for a large running system with pegged CPUs:
Looking at the first instance of P2P timeout:
|
172.23.108.103_20210927-000521/ns_server.goxdcr.log |
2021-09-26T13:04:55.079-07:00 INFO GOXDCR.GenericPipeline: Executing Action timed out
|
2021-09-26T13:04:55.079-07:00 INFO GOXDCR.GenericPipeline: ****************************
|
2021-09-26T13:04:55.079-07:00 ERRO GOXDCR.GenericPipeline: 0d53a5e6437fbb31d3ffddd9e55c21c6/bucket9/bucket9-955799311 failed to start, err=map[genericPipeline.RunP2PProtocol:Execution timed out]
|
2021-09-26T13:04:55.079-07:00 ERRO GOXDCR.PipelineMgr: Failed to start the pipeline 0d53a5e6437fbb31d3ffddd9e55c21c6/bucket9/bucket9-955799311
|
At the time, CPU starts getting busy:
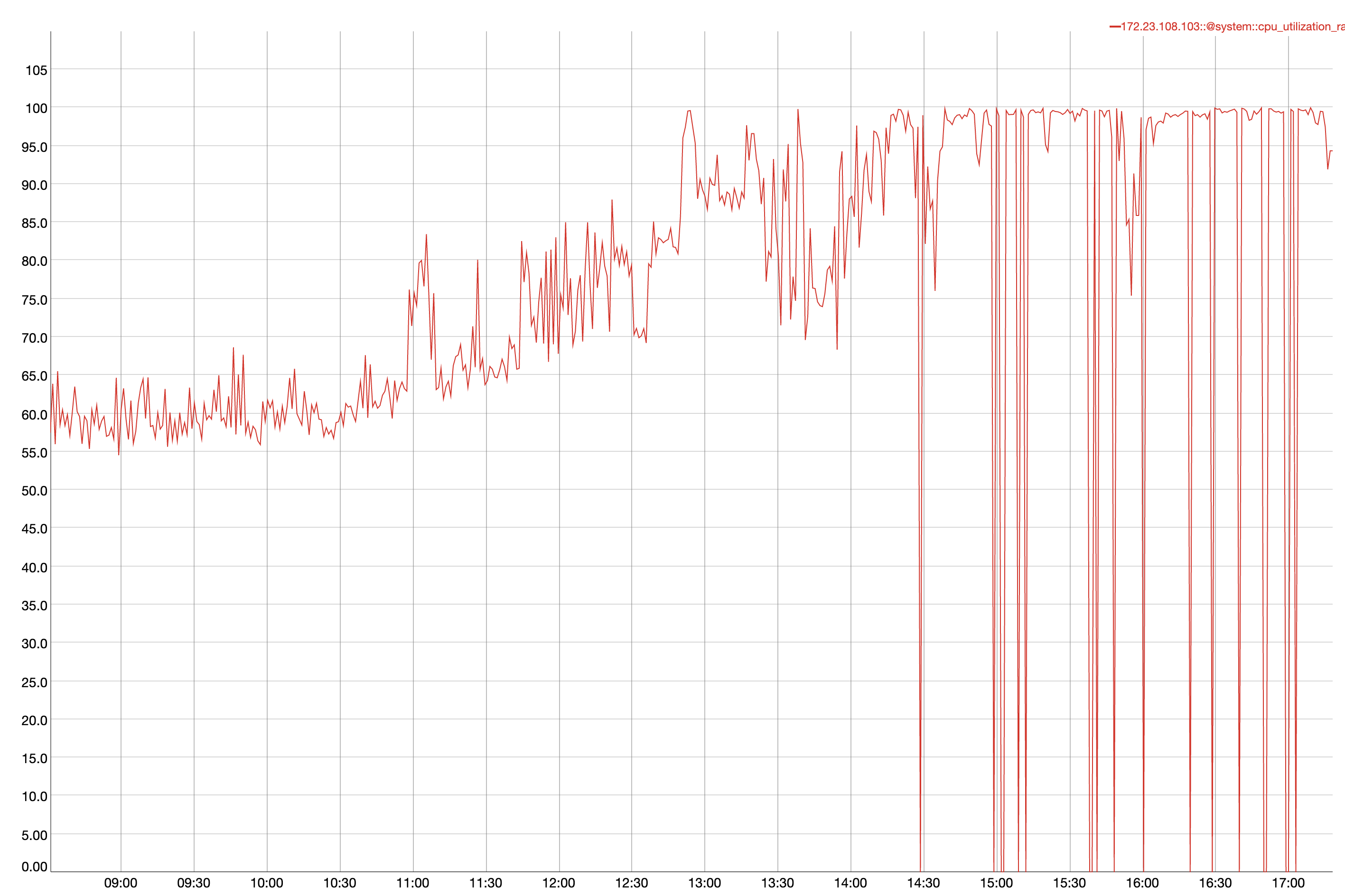
It's a correlation that as the CPU gets pegged, XDCR will need more time to perform P2P.
It is also such that the first instance of a timeout failure is when CPU starts getting pegged, but no such timeout occurred beforehand.
Moreover, looking at peer nodes, if a single node is slow to respond to a request, then it eats into the whole 1 minute process.
One peer node was particular busy and slow to respond to general requests, at times taking up to 1 minute:
|
FILE collectinfo-2021-09-27T000520-ns_1@172.23.97.121.zip ----------------------- |
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:06:52.592-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.96.148:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 12.963134659s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:07:20.477-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.97.119:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/bucket9/bucket9) took 27.881782721s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:07:47.493-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.25:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 12.462504646s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:08:14.514-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.21:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 26.808784537s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:09:08.824-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.20:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 29.423710138s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:10:02.887-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.106.100:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/bucket9/bucket9) took 20.611870969s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:10:29.897-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.25:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 26.946682172s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:10:56.966-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.25:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/default/remote) took 16.934218116s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:11:52.042-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.98.135:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/bucket8/bucket8) took 9.276670459s
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:12:19.056-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.99.25:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/bucket9/bucket9) took 26.786388958s
|
...
|
cbcollect_info_ns_1@172.23.97.121_20210927-000520/ns_server.goxdcr.log:2021-09-26T13:36:48.986-07:00 WARN GOXDCR.Utils: VBMasterCheckHandler(172.23.97.119:8091,0d53a5e6437fbb31d3ffddd9e55c21c6/bucket4/bucket4) took 1m13.958987404s
|
Once the pull is done, it'll take time to merge all the ckpts and backfill replication in sequence... as it'll take time to do a RMW on all checkpoints.
It makes sense to give the p2p protocol a bigger and longer breathing room as XDCR gets taxed more heavily per each pipeline start now given the P2P in place.
We may also need to think about a more dynamic way to determine how long a P2P should run based on the number of replications in place. We have seen customer situations where they are running 60+ replications... we'll need to account for that scenario as well in a busy system so that pipeline has enough time to run P2P protocol before starting.
Attachments
Issue Links
- relates to
-
MB-48603 [System Test] XDCR logs are filled with "execution timed out" error messages
-

- Closed
-