Details
-
Bug
-
Resolution: Not a Bug
-
 Major
Major
-
None
-
7.1.0
-
Untriaged
-
Centos 64-bit
-
1
-
No
-
KV 2021-Nov
Description
Script to Repro
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/win10-bucket-ops-temp_rebalance_magma.ini rerun=False,disk_optimized_thread_settings=True,get-cbcollect-info=True -t bucket_collections.collections_rebalance.CollectionsRebalance.test_data_load_collections_with_hard_failover_rebalance_out,nodes_init=5,nodes_failover=1,bucket_spec=magma_dgm.10_percent_dgm.5_node_2_replica_magma_ttl_512,doc_size=512,randomize_value=True,data_load_spec=ttl_load,data_load_stage=during,skip_validations=False,sleep_before_validation_of_ttl=1300'
|
Steps to Repro
1. Create a 5 node cluster.
2021-10-20 01:24:40,773 | test | INFO | MainThread | [table_view:display:72] Cluster statistics
|
+----------------+----------+-----------------+-----------+-----------+----------------------+-------------------+-----------------------+
|
| Node | Services | CPU_utilization | Mem_total | Mem_free | Swap_mem_used | Active / Replica | Version |
|
+----------------+----------+-----------------+-----------+-----------+----------------------+-------------------+-----------------------+
|
| 172.23.105.36 | kv | 0.32610058949 | 11.45 GiB | 10.62 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.0-1533-enterprise |
|
| 172.23.105.33 | kv | 1.04153595181 | 11.45 GiB | 10.60 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.0-1533-enterprise |
|
| 172.23.105.206 | kv | 1.09118274175 | 11.45 GiB | 10.69 GiB | 32.14 MiB / 3.50 GiB | 0 / 0 | 7.1.0-1533-enterprise |
|
| 172.23.106.177 | kv | 0.500876533934 | 11.45 GiB | 10.67 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.0-1533-enterprise |
|
| 172.23.105.164 | kv | 1.15389439358 | 11.45 GiB | 10.55 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.0-1533-enterprise |
|
+----------------+----------+-----------------+-----------+-----------+----------------------+-------------------+-----------------------+
|
2. Create buckets/scopes/collections/data with bucket ttl set on all the buckets.
2021-10-20 01:41:54,081 | test | INFO | MainThread | [table_view:display:72] Bucket statistics
|
+---------+-----------+-----------------+----------+------------+------+----------+-----------+------------+------------+---------------+
|
| Bucket | Type | Storage Backend | Replicas | Durability | TTL | Items | RAM Quota | RAM Used | Disk Used | ARR |
|
+---------+-----------+-----------------+----------+------------+------+----------+-----------+------------+------------+---------------+
|
| bucket1 | couchbase | couchstore | 2 | none | 1100 | 100000 | 9.77 GiB | 321.40 MiB | 385.67 MiB | 100 |
|
| bucket2 | couchbase | magma | 2 | none | 1100 | 50000 | 4.88 GiB | 555.46 MiB | 592.85 MiB | 100 |
|
| default | couchbase | magma | 2 | none | 1100 | 16263515 | 2.50 GiB | 1.86 GiB | 23.27 GiB | 9.74566999233 |
|
+---------+-----------+-----------------+----------+------------+------+----------+-----------+------------+------------+---------------+
|
3. Hard failover a node.
2021-10-20 01:41:58,818 | test | INFO | MainThread | [collections_rebalance:rebalance_operation:620] failing over nodes [ip:172.23.106.177 port:8091 ssh_username:root]
|
2021-10-20 01:42:07,961 | test | INFO | pool-3-thread-30 | [rest_client:monitorRebalance:1574] Rebalance done. Taken 8.08499979973 seconds to complete
|
2021-10-20 01:42:07,966 | test | INFO | pool-3-thread-30 | [common_lib:sleep:22] Sleep 8.08499979973 seconds. Reason: Wait after rebalance complete
|
4. Start data load
5. Rebalance out the failed over node.
2021-10-20 01:56:57,344 | test | INFO | pool-3-thread-26 | [table_view:display:72] Rebalance Overview
|
+----------------+----------+-----------------------+----------------+--------------+
|
| Nodes | Services | Version | CPU | Status |
|
+----------------+----------+-----------------------+----------------+--------------+
|
| 172.23.105.36 | kv | 7.1.0-1533-enterprise | 29.85836417 | Cluster node |
|
| 172.23.105.33 | kv | 7.1.0-1533-enterprise | 21.9855458349 | Cluster node |
|
| 172.23.105.206 | kv | 7.1.0-1533-enterprise | 16.9491525424 | Cluster node |
|
| 172.23.106.177 | kv | 7.1.0-1533-enterprise | 0.600750938673 | --- OUT ---> |
|
| 172.23.105.164 | kv | 7.1.0-1533-enterprise | 23.8052985169 | Cluster node |
|
+----------------+----------+-----------------------+----------------+--------------+
|
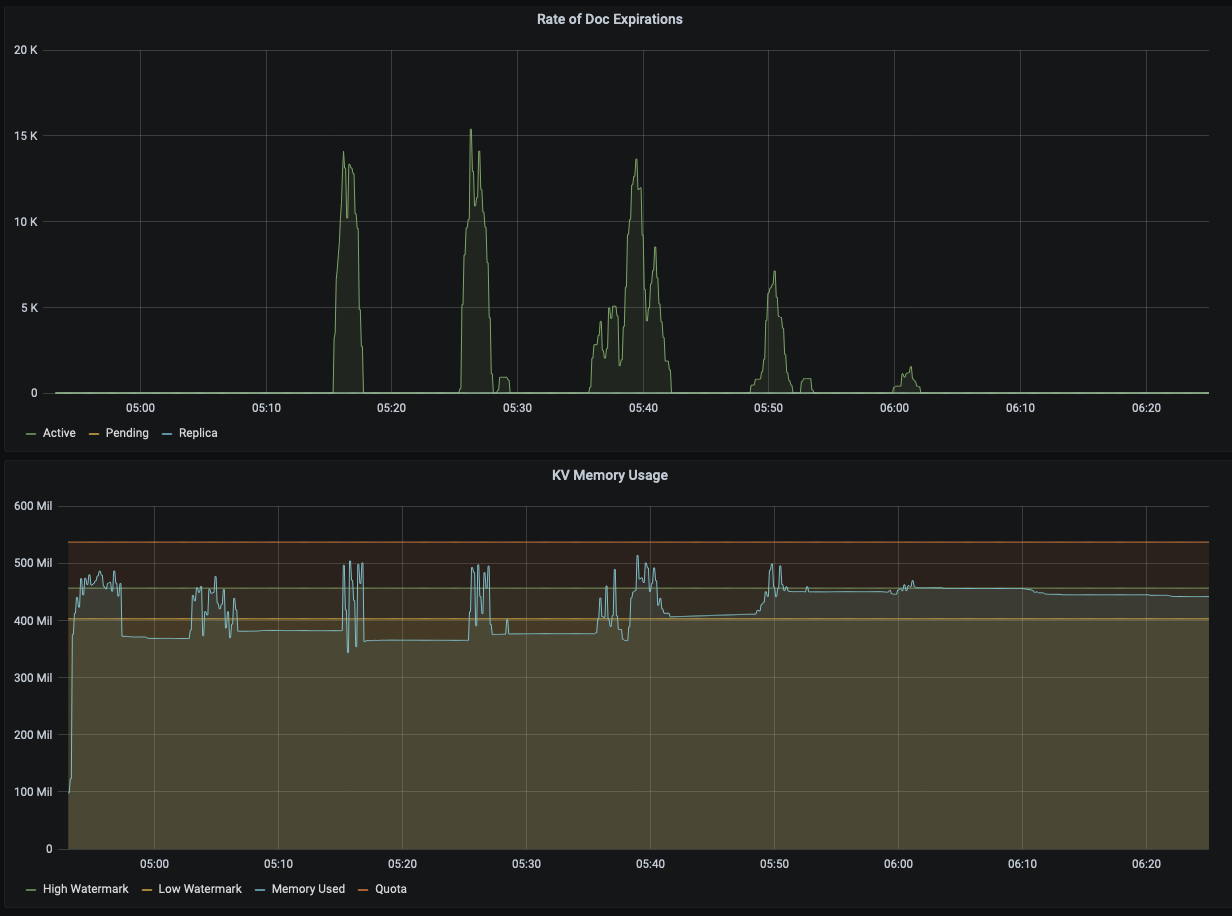
Rebalance completes successfully. Even though bucket ttl was set to 1100 the items on the bucket was not expired post 2 hours. We did 3 full compactions on the bucket to expire on disk items. Every time we did compaction we did notice some documents reducing in the bucket, but never went 0.
cbcollect_info attached.
Attachments
Issue Links
- relates to
-
-
- Closed
-