Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
6.6.2
-
Triaged
-
Yes
Description
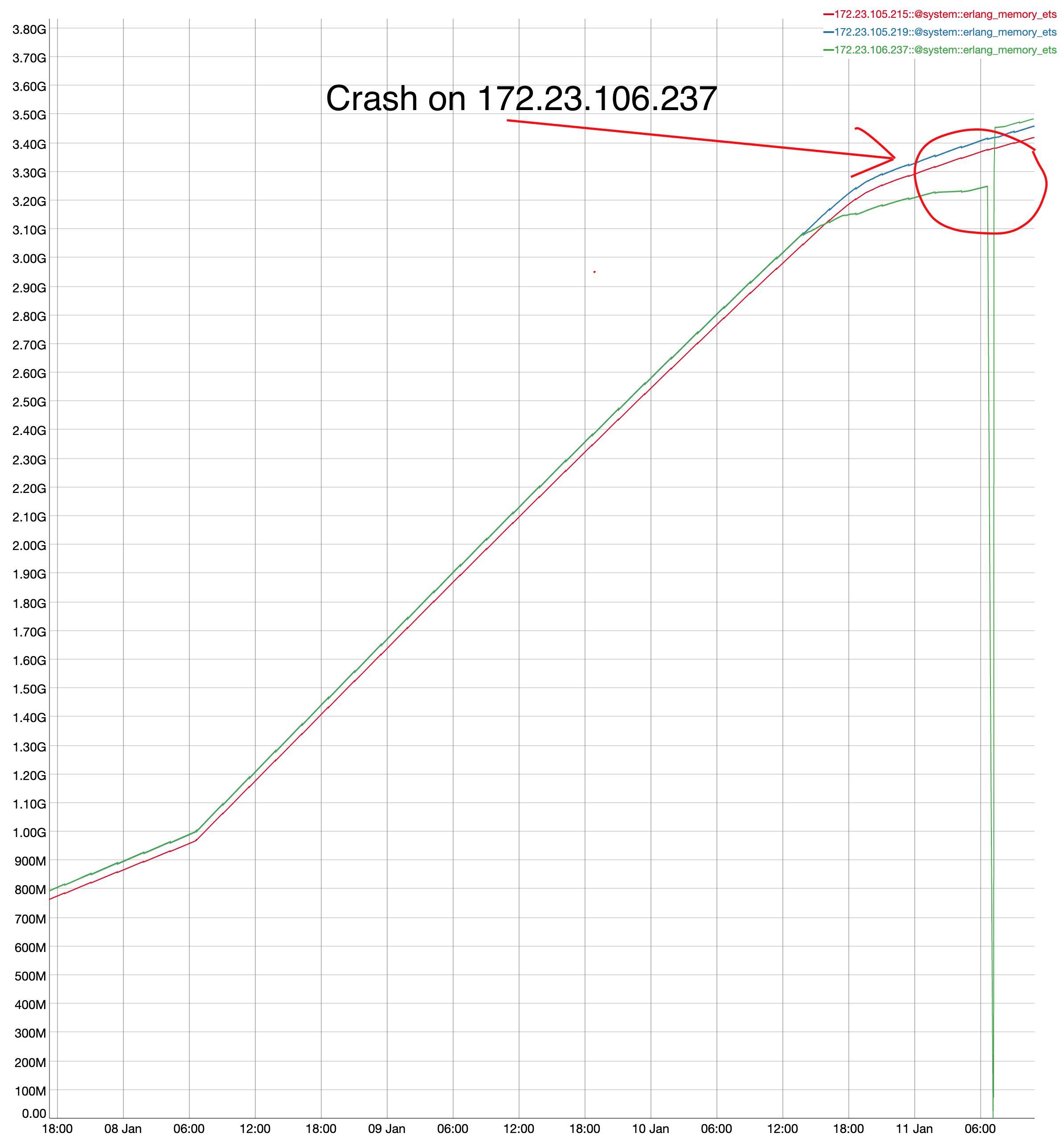
As seen in a case in the field, customer need to create/delete large number of users in short succession. The customer is using secrete management solution (such as HashiCorp) in Kubernetes, where containers are created and destroyed in quick succession, and for each container, an ephemeral user is created and destroyed as well.
Current user CRUD API latency increases as number of users increases, due to the implementation nature of replication (replicated_dets).
Attachments
Issue Links
- is a backport of
-
-
- Closed
-