Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.1.0
-
7.1.0-1817
-
Untriaged
-
-
1
-
Unknown
Description
- Step 1: Create a 4 node cluster
- Step 2: Create required buckets and collections.
- Step 3: Create 625000 items sequentially
- Step 4: Update 625000 RandonKey keys to create 50 percent fragmentation
- Step 5: Create 625000 items sequentially
- Step 6: Update 625000 RandonKey keys to create 50 percent fragmentation
- Step 7: Rebalance in with Loading of docs. Abort and resume rebl at 20%, 40%, 60%, 80%
- Step 8: Crash Magma/memc with Loading of docs
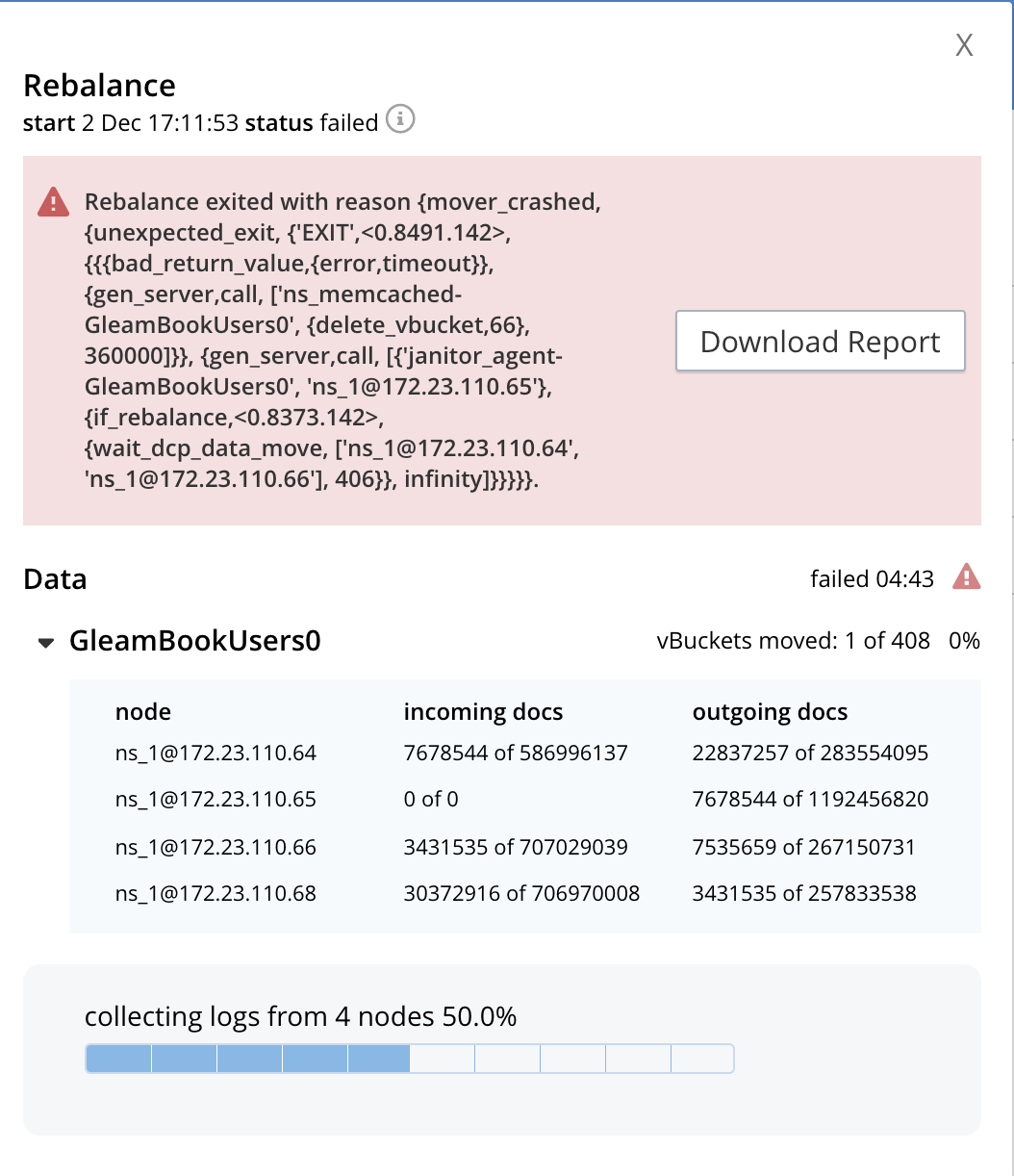
- Step 9: Rebalance Out with Loading of docs. Abort and resume rebl at 20%. Rebalance failed on resumption.
Rebalance exited with reason {mover_crashed,
|
{unexpected_exit,
|
{'EXIT',<0.8491.142>,
|
{{{bad_return_value,{error,timeout}},
|
{gen_server,call,
|
['ns_memcached-GleamBookUsers0',
|
{delete_vbucket,66},
|
360000]}},
|
{gen_server,call,
|
[{'janitor_agent-GleamBookUsers0',
|
'ns_1@172.23.110.65'},
|
{if_rebalance,<0.8373.142>,
|
{wait_dcp_data_move,
|
['ns_1@172.23.110.64',
|
'ns_1@172.23.110.66'],
|
406}},
|
infinity]}}}}}.
|
Rebalance Operation Id = ab0fe02c379c617b89c2ca96499125e2
|
|
QE Test |
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/magma_temp_job3.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.Hospital.Murphy.SystemTestMagma,nodes_init=3,graceful=True,skip_cleanup=True,num_items=40000000,num_buckets=1,bucket_names=GleamBook,doc_size=1536,bucket_type=membase,eviction_policy=fullEviction,iterations=5,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,assert_crashes_on_load=True,num_collections=50,maxttl=10,num_indexes=100,pc=10,index_nodes=0,cbas_nodes=0,fts_nodes=0,ops_rate=200000,ramQuota=102400,doc_ops=create:update:delete:read,mutation_perc=100,rebl_ops_rate=50000,key_type=RandomKey -m rest'
|