Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.1.0
-
6.6.5-10076 —> 7.1.0-2117
-
Untriaged
-
Centos 64-bit
-
1
-
No
-
KV 2022-Jan, KV 2022-Feb
Description
This patch added an UMPMCQueue which is modified while tracking allocations/deallocations against a bucket. There are other existing uses of the queue type in "no-bucket" situations (e.g., inside the executorpool).
folly::UMPMCQueue uses folly hazard_pointers internally to protect Segments - an internal object used to store the queued items. Hazptr-protected objects which are no longer needed but may still be being accessed by other threads may be retire -ed, but destruction will be delayed until some later time when no hazard pointer references them.
retire transfers ownership of the object to a hazptr_domain; by default a single global domain will be used. Once the number of retired objects in a domain exceeds a certain threshold, the thread which pushed the count over the threshold will check all retired items and will reclaim any which are no longer referenced. They will be, by default, destroyed inline by that thread.
Removing items from a UMPMCQueue may allow Segments to be retired. This may trigger destruction of objects which have been retired into the same domain by any hazard pointer user, including other UMPMCQueues. Thus, memory which was allocated under "non-bucket" by one queue may be freed and accounted against a bucket while manipulating a different queue, leading to mem_used becoming lower than the true value.
UMPMCQueue does not currently support providing a custom domain (and internally uses a cohort, which also doesn't support this). If this is supported in the future, a hazptr_domain per bucket would be an ideal solution. This could be worked around now without folly changes as noted in this comment, but would not be a robust solution, and would likely break with future folly releases.
Making changes to avoid use of UMPMCQueue while tracking memory usage against a bucket would be an expedient solution.
Original description
Steps to Repro
1. Run 6.6.5 longevity test for 5-6 days.
./sequoia -client 172.23.104.254:2375 -provider file:centos_second_cluster.yml -test tests/integration/test_allFeatures_madhatter_durability.yml -scope tests/integration/scope_Xattrs_Madhatter.yml -scale 3 -repeat 0 -log_level 0 -version 6.6.5-10076 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
2. Online upgrade to 7.1 using swap rebalance and graceful failover/recovery strategies.
3. Did bunch of rebalances post upgrade.
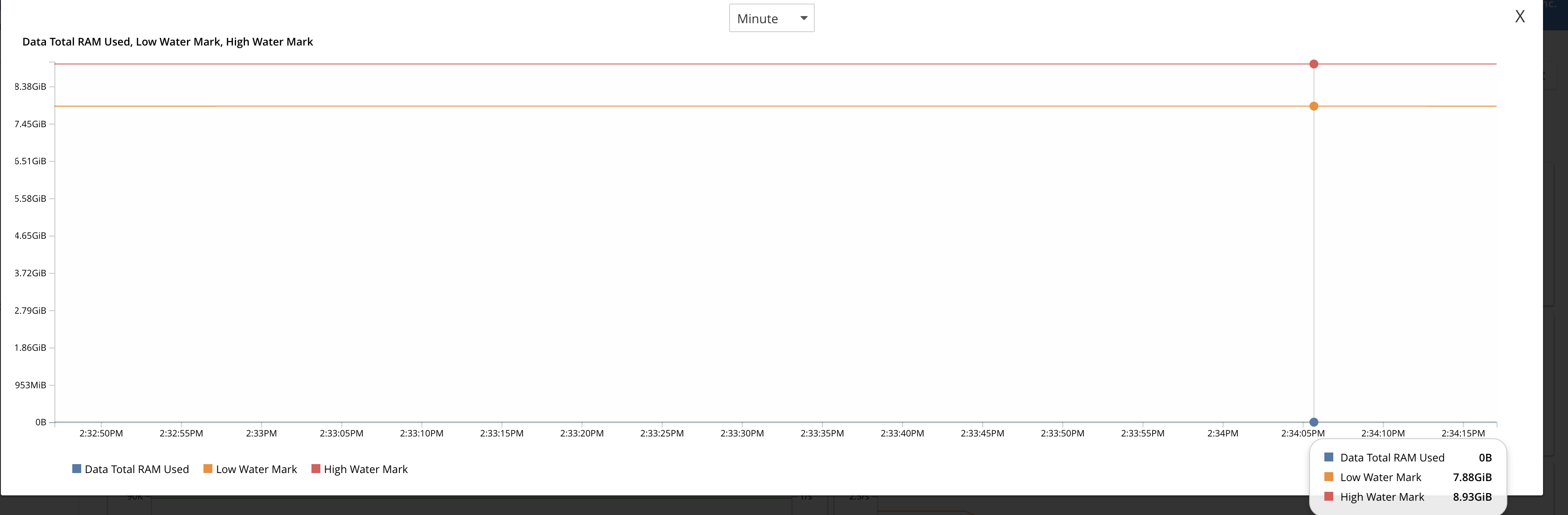
UI : http://172.23.106.134:8091/ui/index.html#/buckets?commonBucket=ORDERS&scenarioZoom=minute&scenario=d26rq56l9
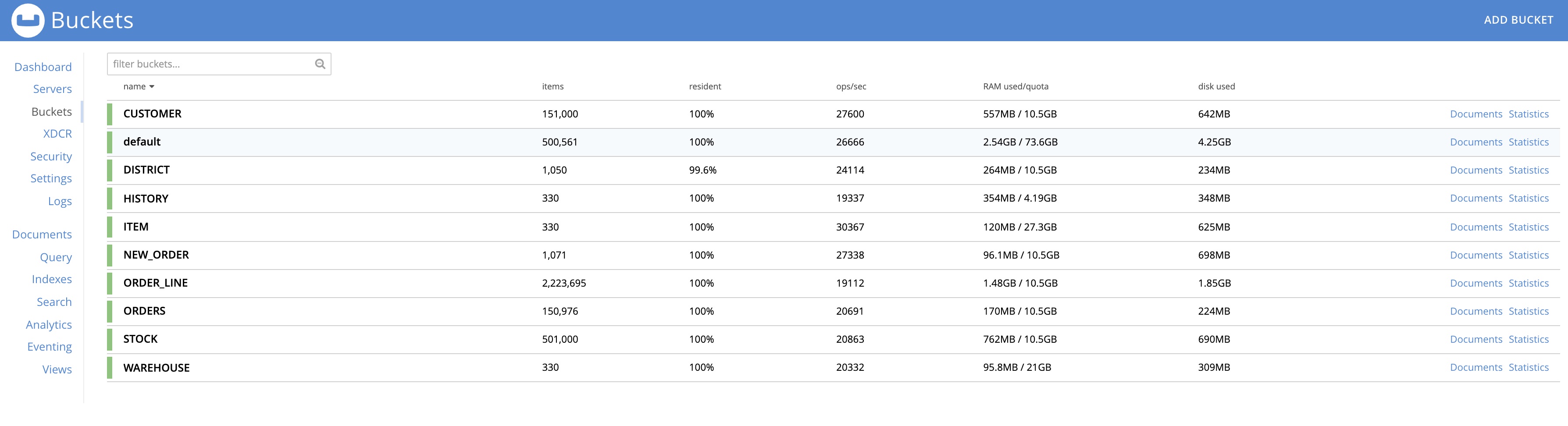
Buckets Before upgrade :- 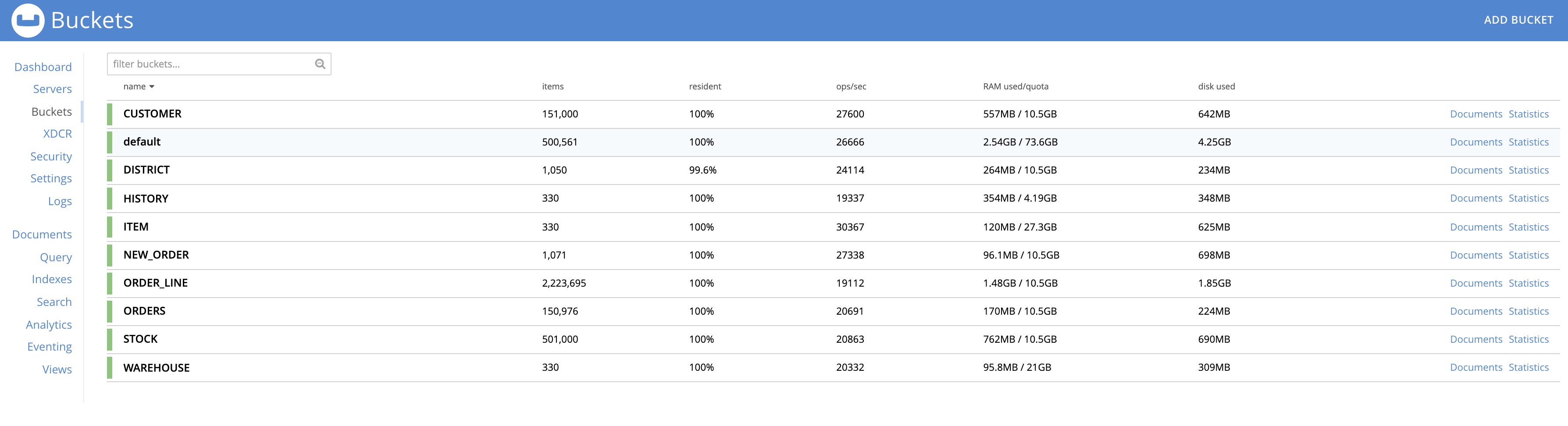
Buckets After upgrade :- 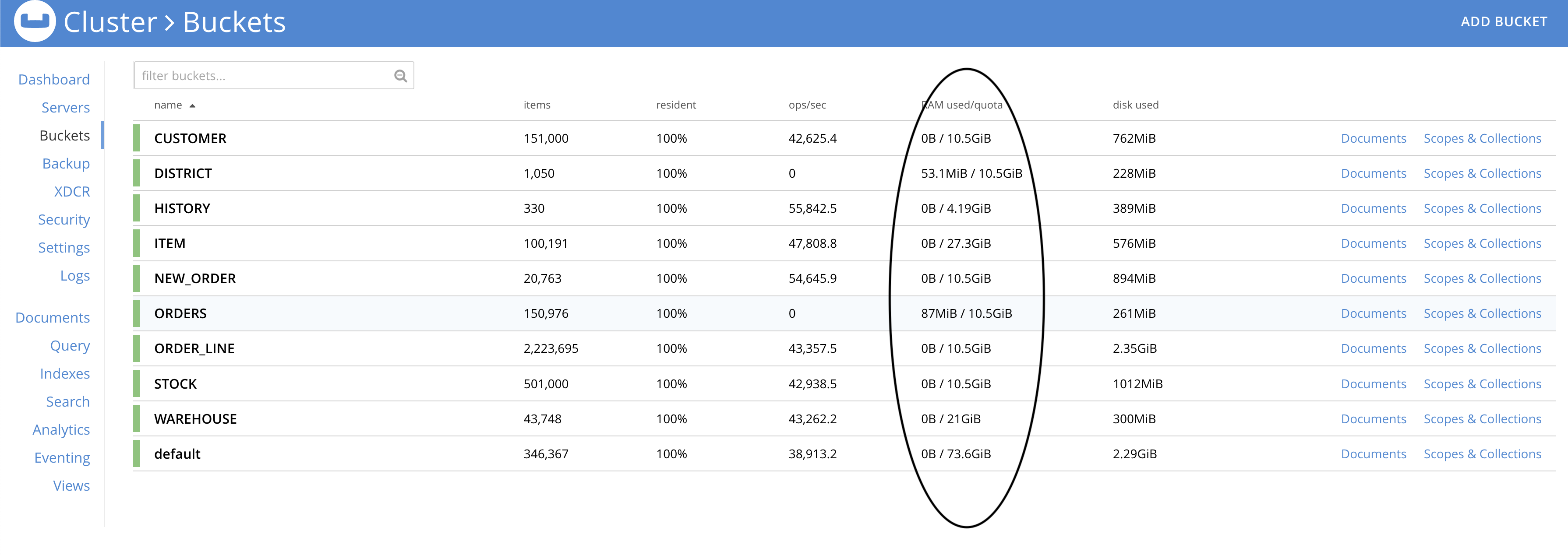
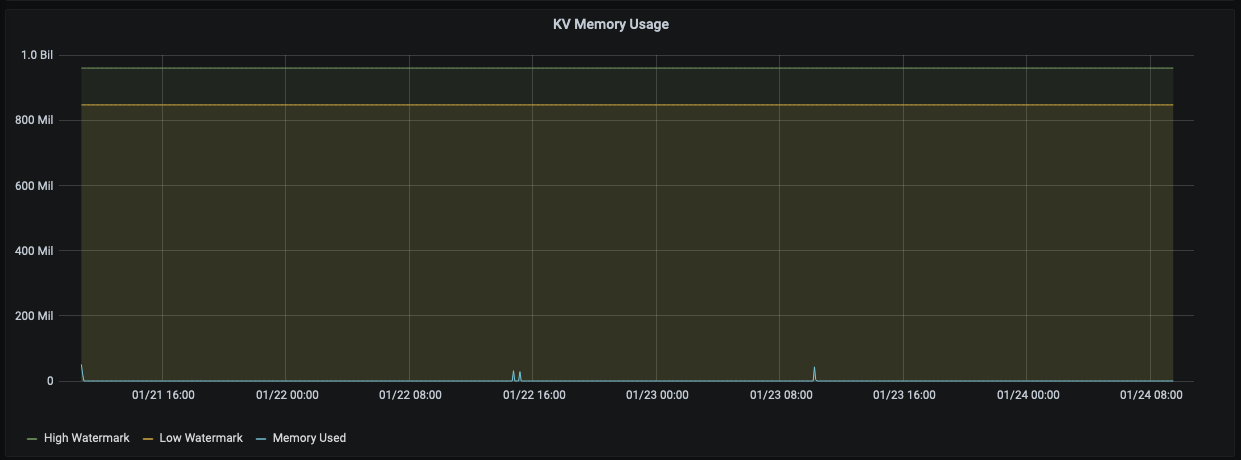
Stats from the ORDER_LINE bucket with highest amount of data : 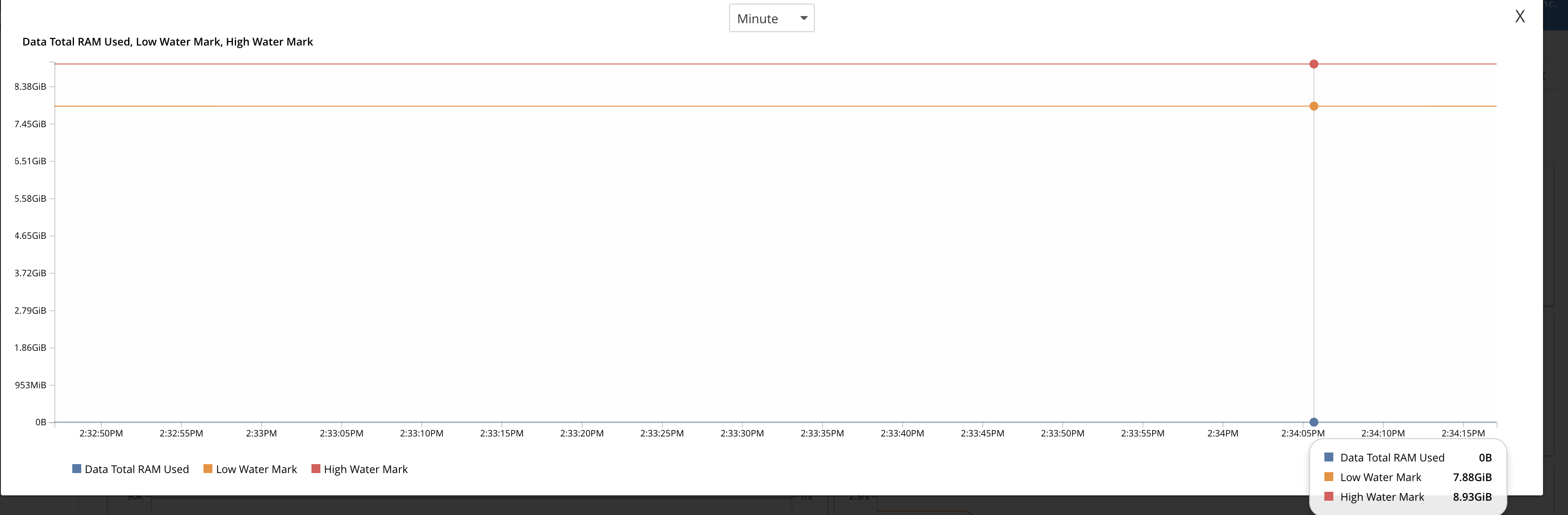
Wonder if this would affect our ejection criteria or if it's just an UI issue.
cbcollect_info attached. This is the first time we are running system test upgrade to 7.1.
Attachments
Issue Links
- causes
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- is duplicated by
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
MB-36996 Eliminate unbounded uses of pthread_key create
-

- Closed
-