Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
7.1.0
-
7.0.3-7031 --> 7.1.0-2434
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
Script to Repro
1. Run CC longevity on 7.0.3 for 2-3 days on 27 node cluster.
./sequoia -client 172.23.104.254:2375 -provider file:centos_second_cluster.yml -test tests/integration/cheshirecat/test_cheshirecat_kv_gsi_coll_xdcr_backup_sgw_fts_itemct_txns_eventing_cbas_scale3.yml -scope tests/integration/cheshirecat/scope_cheshirecat_with_backup.yml -scale 3 -repeat 0 -log_level 0 -version 7.0.3-7031 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
2. Change the encryption level to strict.
3. Upgrade all the 27 nodes in the cluster using online upgrade which uses a combination of swap rebalance and failover/recovery strategies.
4. Do a swap rebalance of the 3 indexer nodes post upgrade.
While step 4 was running I noticed following messages.
172.23.106.136 : index
/opt/couchbase/var/lib/couchbase/logs/indexer.log.1.gz:2022-03-05T20:33:56.426-08:00 [Info] StorageMgr::handleRollback Rollback Index: 15934035682236902171 PartitionId: 0 SliceId: 0 To Zero
|
/opt/couchbase/var/lib/couchbase/logs/indexer.log.1.gz:2022-03-05T20:33:56.426-08:00 [Info] StorageMgr::rollbackAllToZero INIT_STREAM bucket7:scope_0:coll_4
|
/opt/couchbase/var/lib/couchbase/logs/indexer.log.1.gz:2022-03-05T20:33:56.432-08:00 [Info] StorageMgr::handleRollback Rollback Index: 15934035682236902171 PartitionId: 0 SliceId: 0 To Zero
|
/opt/couchbase/var/lib/couchbase/logs/indexer.log.1.gz:2022-03-05T20:33:56.437-08:00 [Info] StorageMgr::handleRollback Rollback Index: 14689098629809955468 PartitionId: 2 SliceId: 0 To Zero
|
Post the completion of rebalance when I went to the indexes page of the above collection I noticed 0 dgm. See 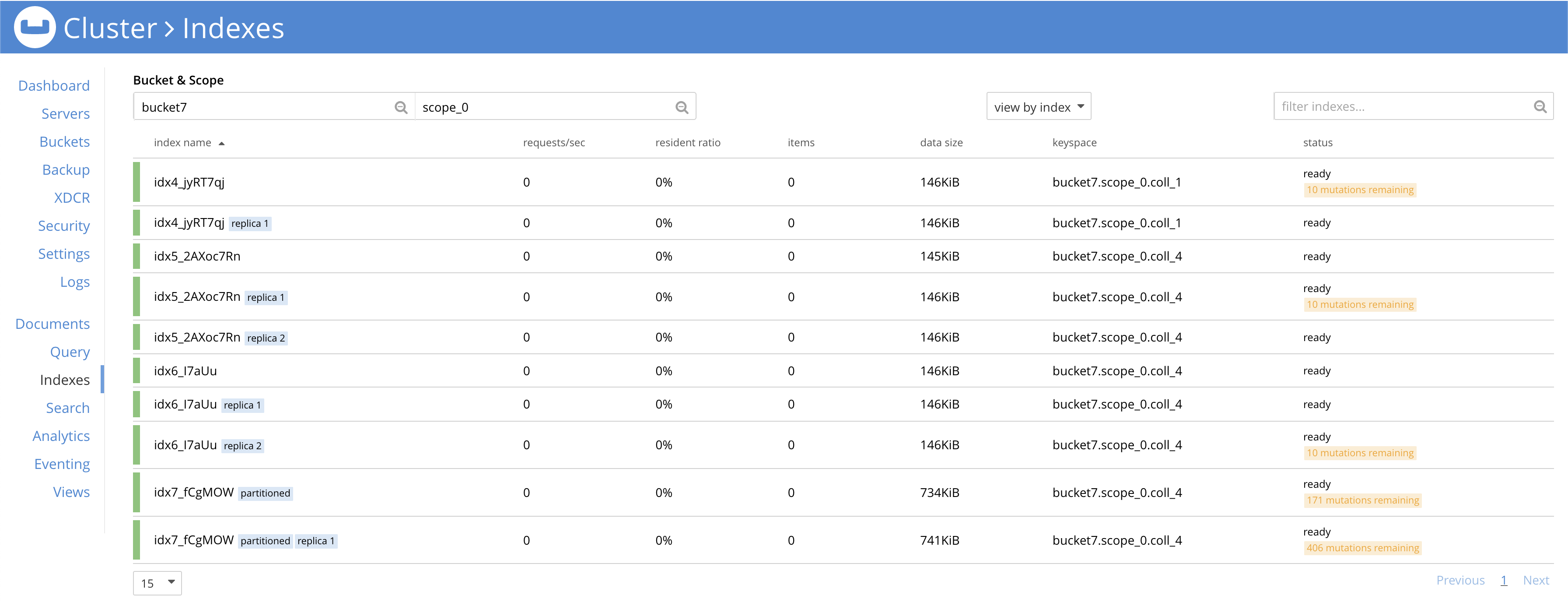
cbcollect_info attached.