Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
7.1.1
-
Enterprise Edition 7.1.1 build 3025
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
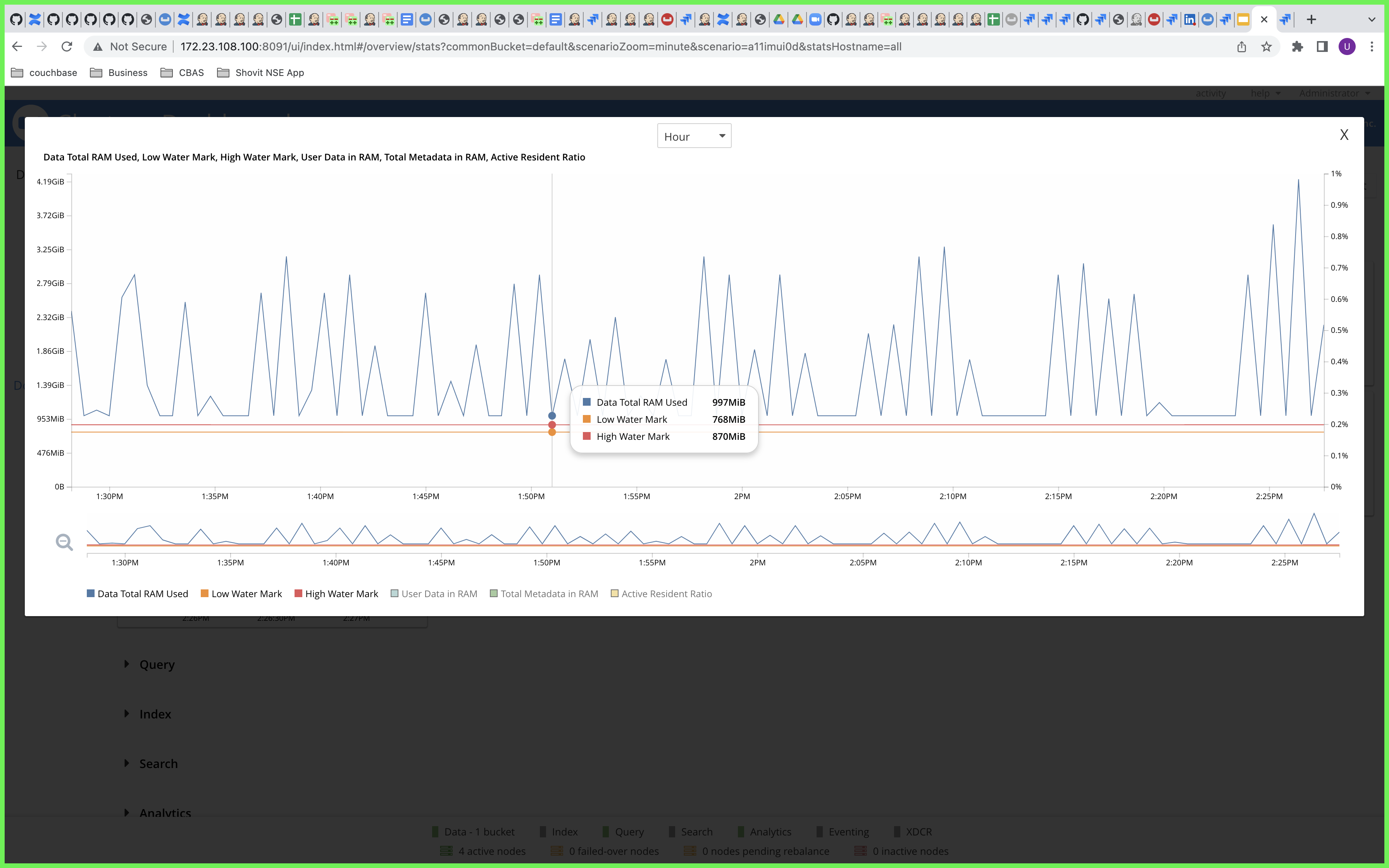
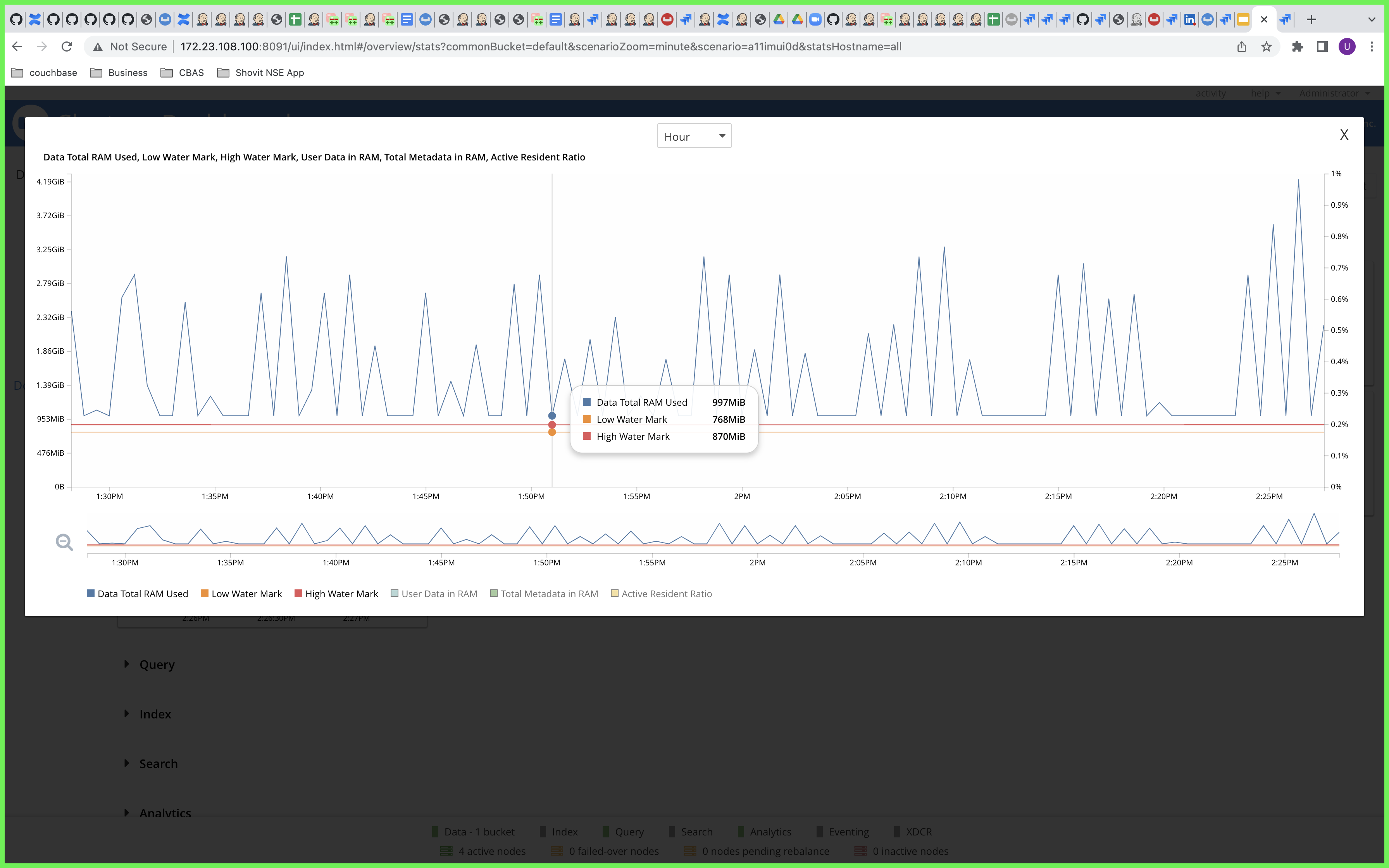
Observation -
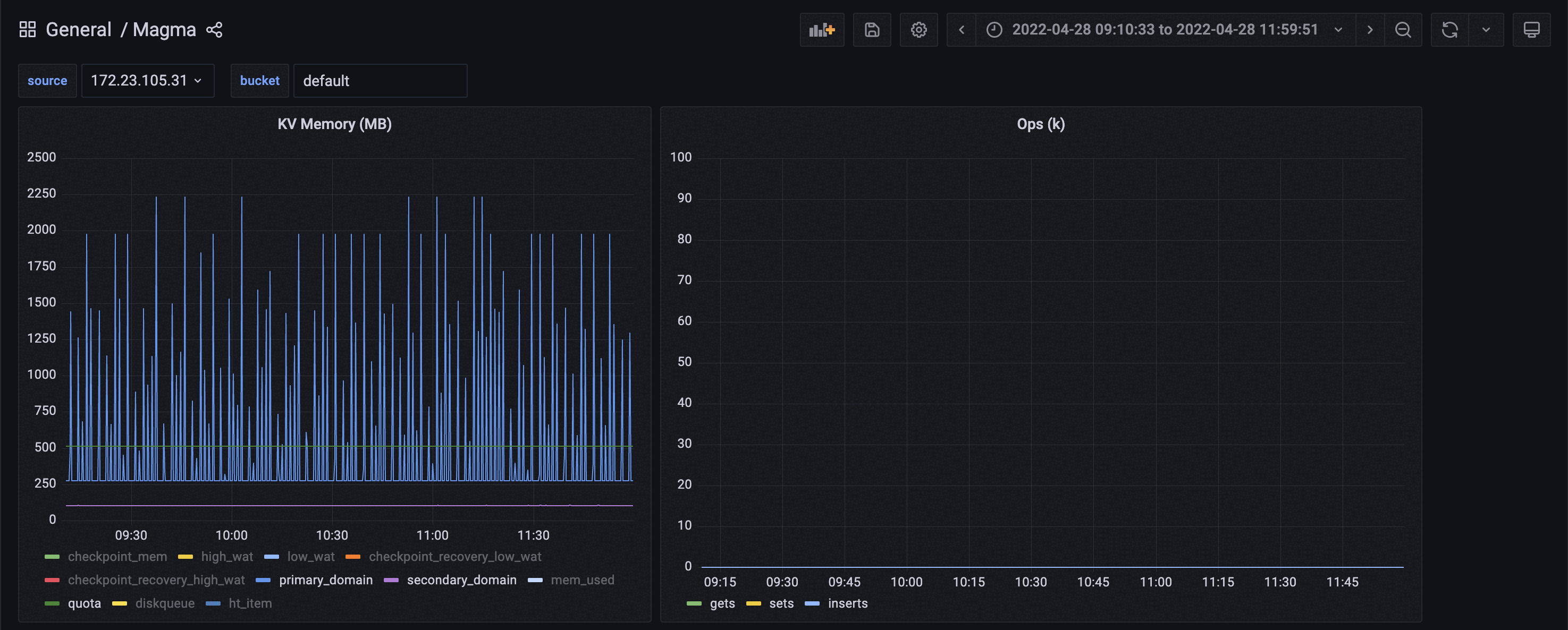
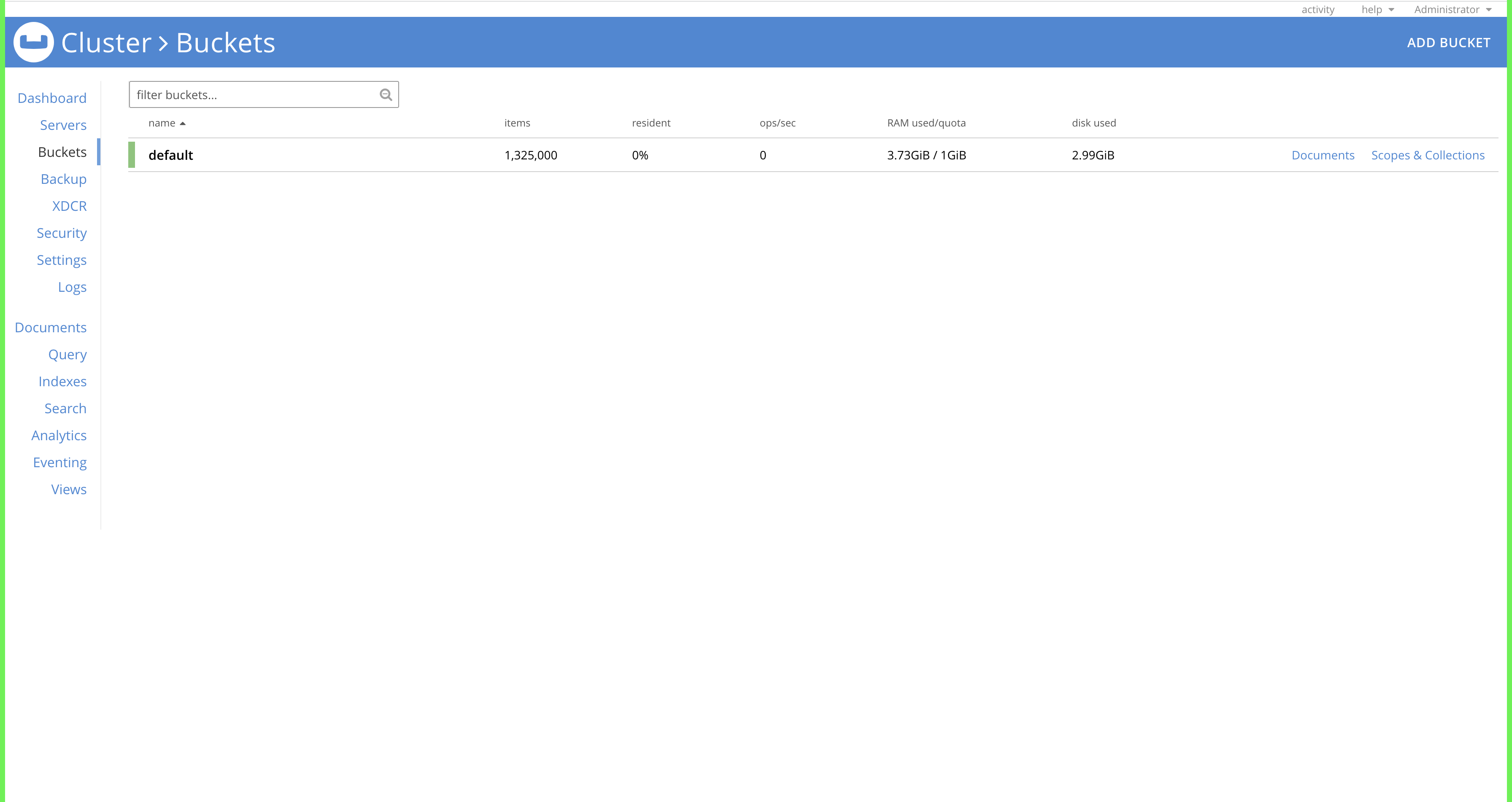
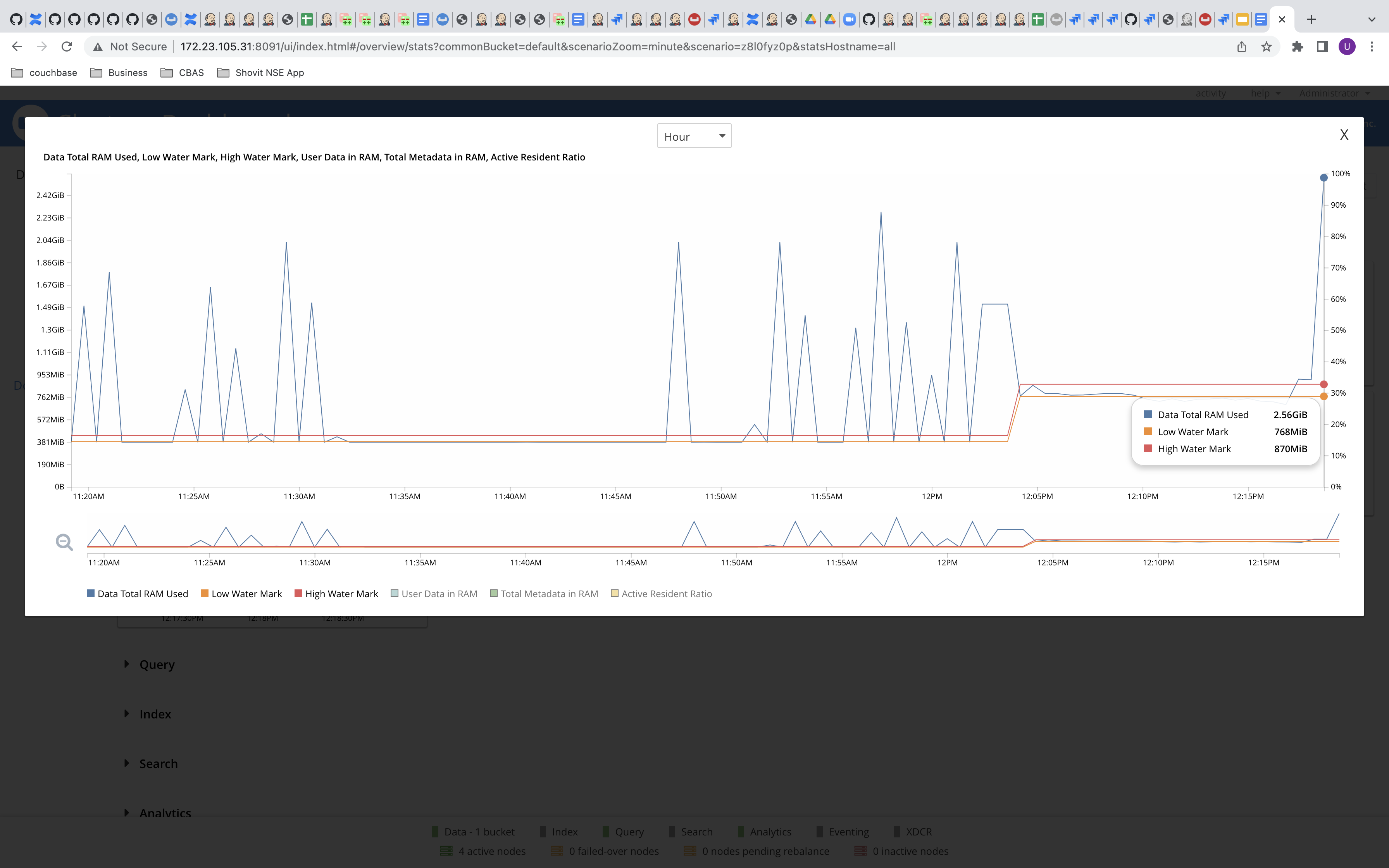
Although only 1 GB RAM is allocated to the magma bucket, the RAM usage is reaching around 3.9 GB. This is observed when analytics is trying to ingest data into it's datasets.
Cluster Info -
| Node | Services | CPU_utilization | Mem_total | Mem_free | Swap_mem_used | Active / Replica | Version |
| 172.23.108.0 | cbas | 2.46478873239 | 3.67 GiB | 2.50 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.1-3025-enterprise |
| 172.23.108.1 | cbas | 2.19143576826 | 3.67 GiB | 2.67 GiB | 0.0 Byte / 3.50 GiB | 0 / 0 | 7.1.1-3025-enterprise |
| 172.23.108.102 | kv | 1.91194968553 | 3.67 GiB | 3.05 GiB | 72.00 MiB / 3.50 GiB | 0 / 0 | 7.1.1-3025-enterprise |
| 172.23.108.100 | kv, n1ql | 2.16243399547 | 3.67 GiB | 2.94 GiB | 3.75 MiB / 3.50 GiB | 0 / 0 | 7.1.1-3025-enterprise |
Steps to reproduce -
1. Create cluster as mentioned above.
2. Create a magma bucket with 512 MB RAM (since there are 2 KV nodes, total RAM for bucket becomes 1 GB) allocated to it and replica set as 1.
3. Create 10 scopes (including the default) and each scope should have 25 collections.
4. Load 5300 docs in each collection. Each doc size is 1 KB.
5. Create dataset on each of the collection of the KV bucket created above.
6. It is observed that the RAM usage of the bucket is exceeding the RAM allocation.
RAM Quota :