Details
-
Bug
-
Resolution: Unresolved
-
 Critical
Critical
-
7.1.1
-
Enterprise Edition 7.1.1 build 3067
-
Untriaged
-
-
1
-
Unknown
-
KV June 2022, KV July 2022, KV Aug 2022
Description
- Create a 3 node KV cluster
- Create a magma bucket with 1 replica with RAM=200GB
- Load 10B 1024 bytes documents. This is 20TB of Active + replica and puts the bucket in 1% DGM.
- Upsert the whole data to create 50% fragmentation.
- Create 25 datasets on cbas ingesting data from different collections. Let the ingestion start. Start SQL++ load with 10QPS asynchronously.
- Start an asnyc CRUD data load:
Read Start: 0Read End: 100000000Update Start: 0Update End: 100000000Expiry Start: 0Expiry End: 0Delete Start: 100000000Delete End: 200000000Create Start: 200000000Create End: 300000000Final Start: 200000000Final End: 300000000 - Rebalance in 1 KV node. Rebalance seem to be stuck since hours...
|
QE Test |
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/magma_temp_job3.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.Hospital.Murphy.ClusterOpsVolume,nodes_init=3,graceful=True,skip_cleanup=True,num_items=100000000,num_buckets=1,bucket_names=GleamBook,doc_size=1300,bucket_type=membase,eviction_policy=fullEviction,iterations=2,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,assert_crashes_on_load=True,num_collections=50,maxttl=10,num_indexes=25,pc=10,index_nodes=0,cbas_nodes=1,fts_nodes=0,ops_rate=200000,ramQuota=68267,doc_ops=create:update:delete:read,mutation_perc=100,rebl_ops_rate=50000,key_type=RandomKey -m rest'
|
Attachments
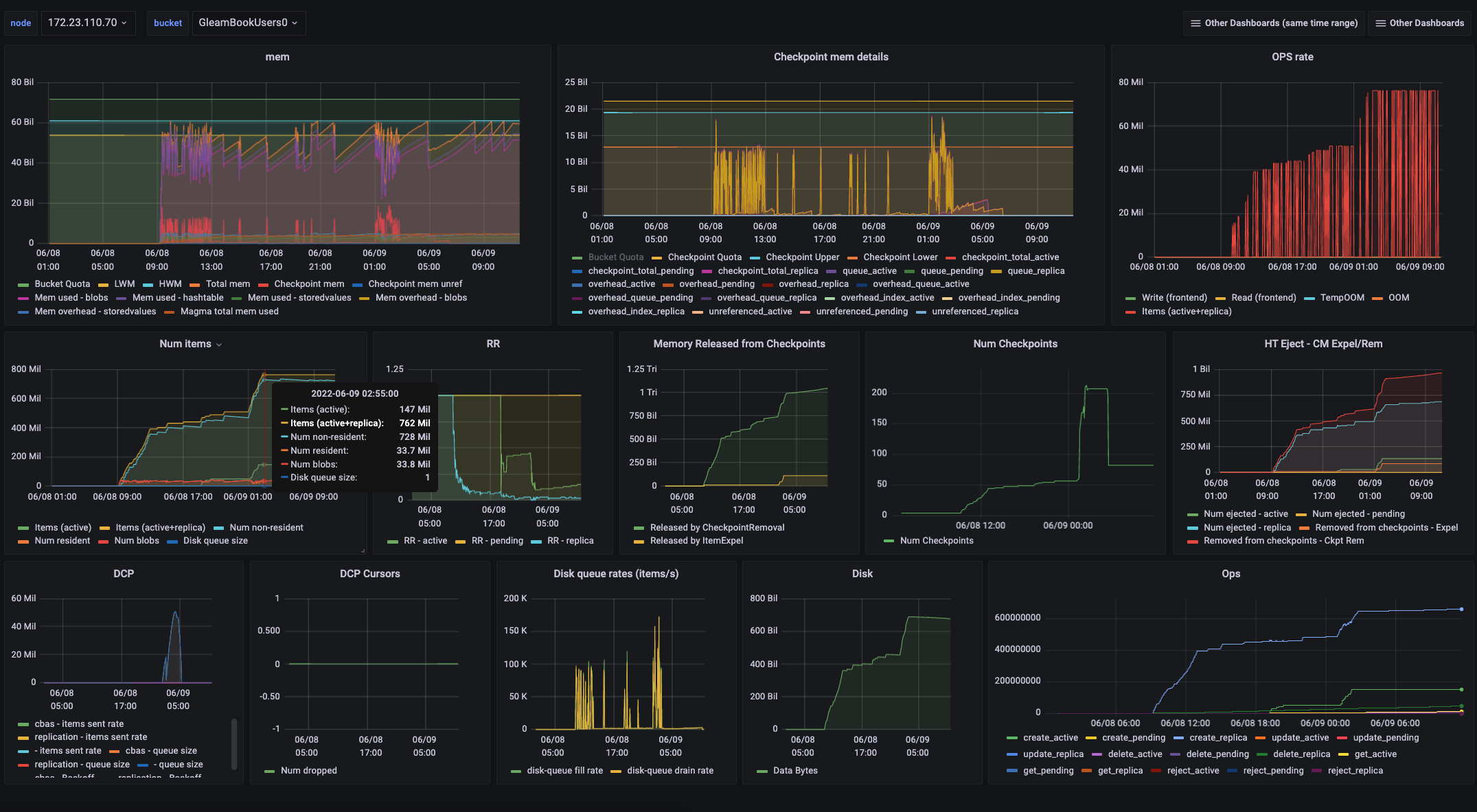
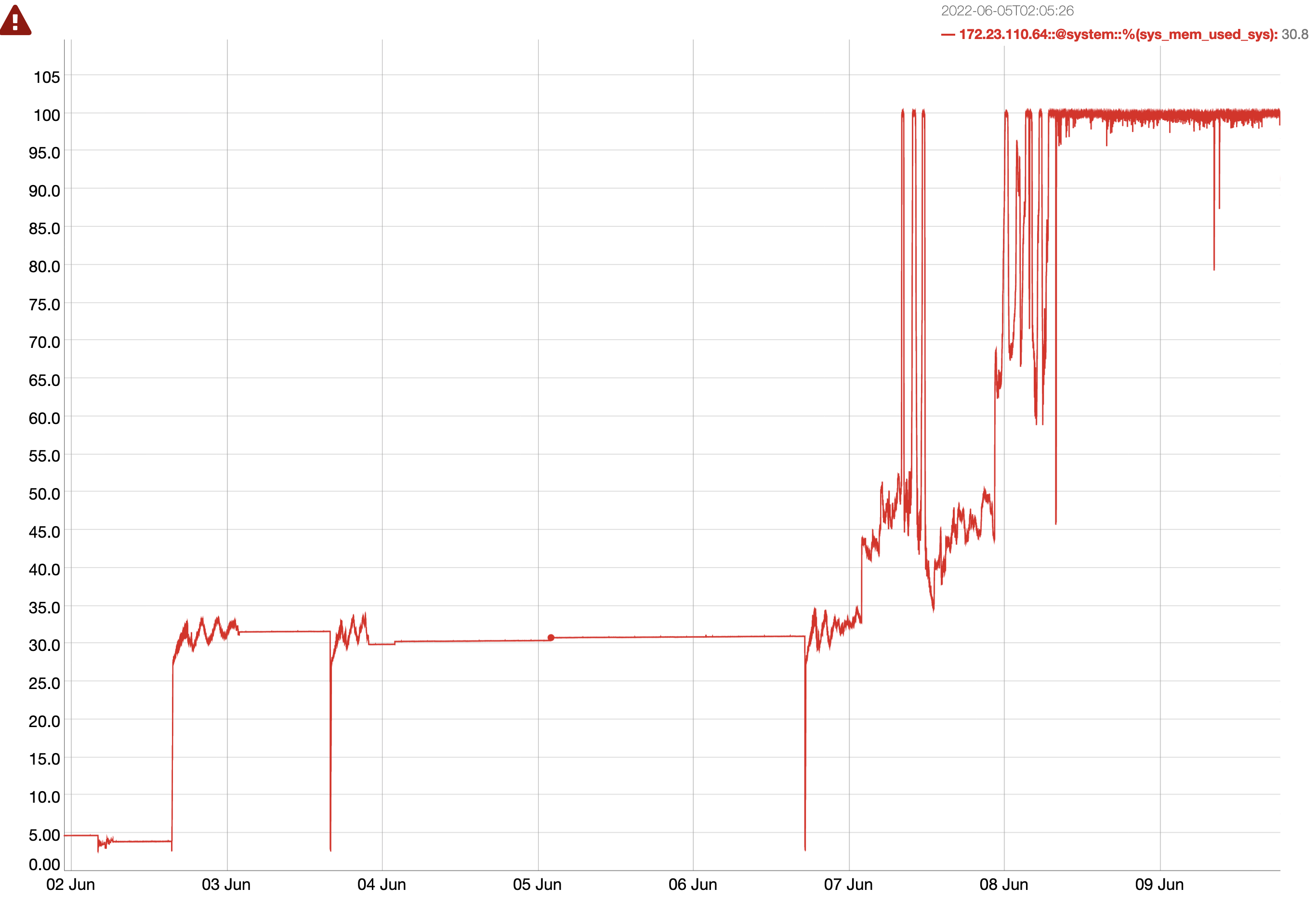
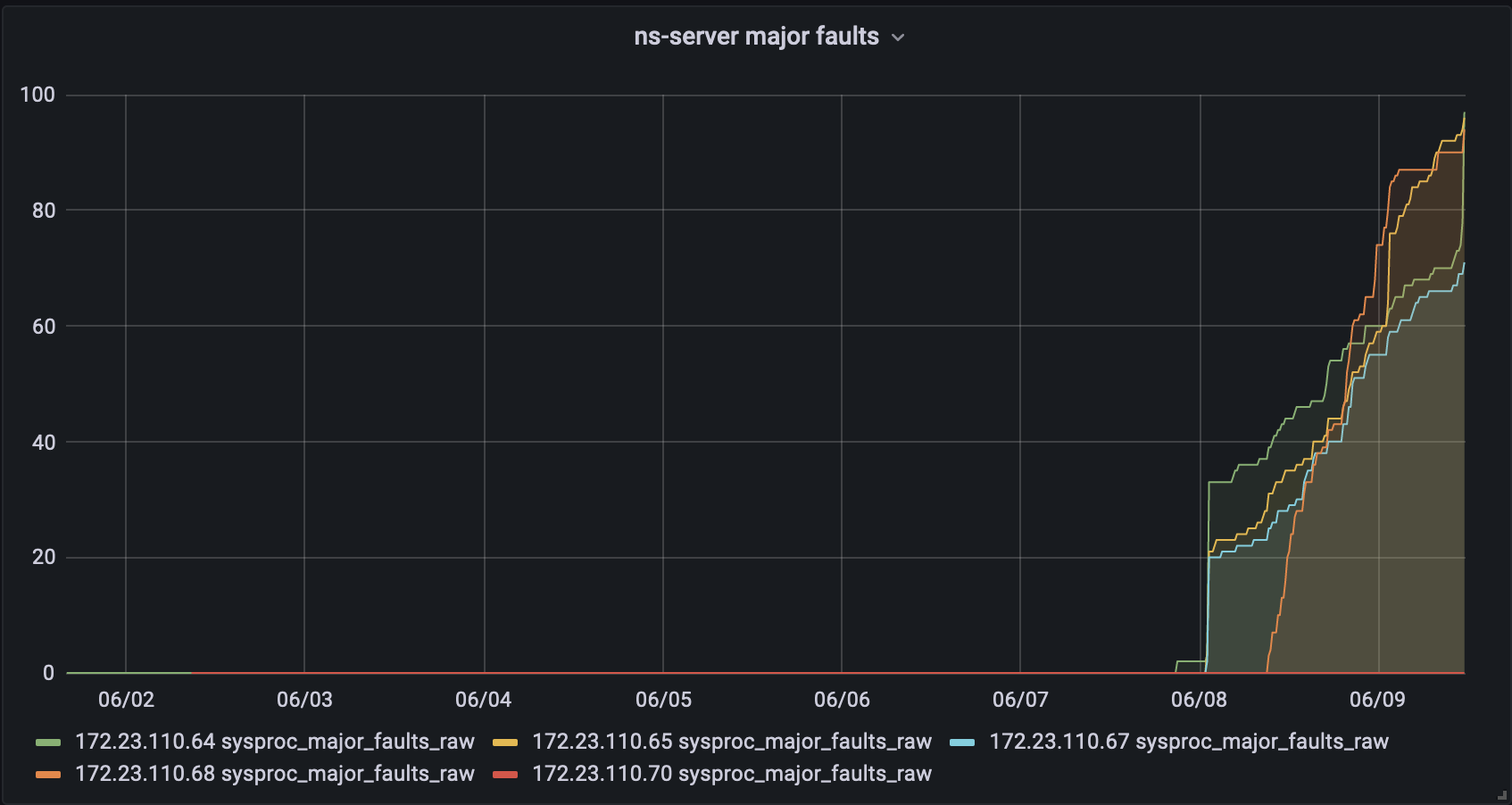

Issue Links
Gerrit Reviews
| For Gerrit Dashboard: MB-52490 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 176234,1 | MB-52490: Add BackfillManager::producer member | neo | kv_engine | Status: NEW | -1 | +1 |
| 176236,5 | MB-52490: Avoid that a Producer consumes all backfills.maxRunning slots | neo | kv_engine | Status: NEW | -1 | -1 |
| 176424,6 | MB-52490: Move Backfill Task to its own source files | neo | kv_engine | Status: NEW | 0 | +1 |
| 176712,8 | MB-52490: Pass Producer to BackfillManagerTask | neo | kv_engine | Status: NEW | -1 | -1 |
| 176802,5 | MB-52490: Prevent that backfill-busy Producers block others | neo | kv_engine | Status: NEW | -1 | -1 |