Description
Most database professionals coming from a SQL Server background will be expecting a deeper dive into execution plans than we currently provide inside our UI's. Having worked for two ISV's as a SQL Server specialist I spent a long time working with customer execution plans and would be happy to share my experiences with how customers use these to identify bottlenecks.
The scope of this section is very large and so will need to be broken down into sections.
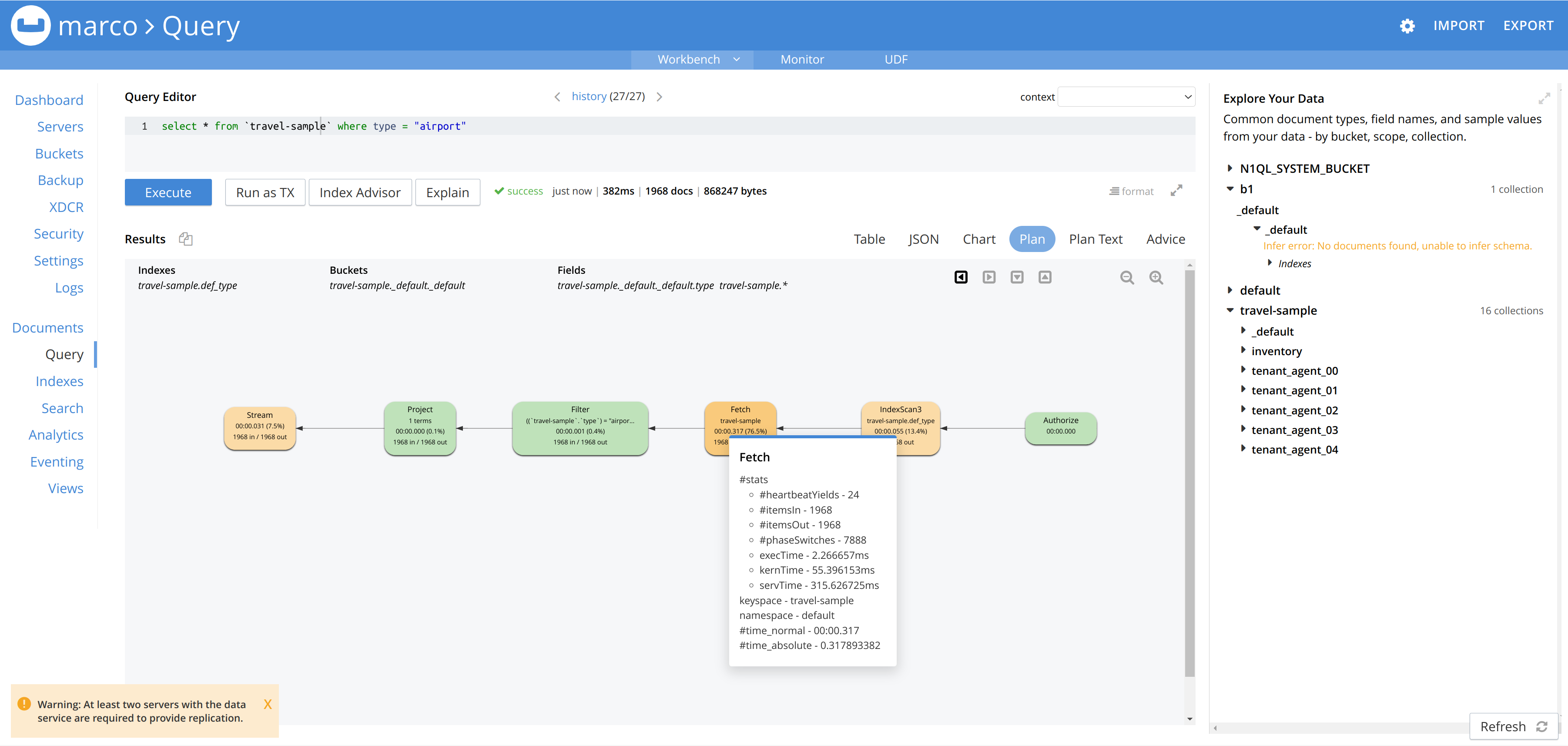
Visually it is very hard to distinguish steps at a glance because they are all coloured rounded rectangles. It would be easier to scan through a plan if there were different graphics for different operators.
The properties available for each operator is very limited in it's scope. There is a lot more information that we could and should be sharing here to allow customers to tune their own queries more easily without going to support. Obviously the properties are relevant to each operator and so should not be listed here.
The boxes can change colour depending on the percentage of cost, but it is not clear how this percentage is calculated and if this is indeed the calculation that the user wants to utilise. It may be that they would like the percentage to be calculated a different way, by amount of IO for example.
SentryOne (now part of Solarwinds) created a standalone free product called [Plan Explorerwhich allowed SQL Server professionals to examine their query plans in a lot more detail than could be performed in Microsoft's own native SQL Server Management Studio. It was so popular that most of Microsoft's Premier Field Engineers used to have it on their laptops and asked their clients to install it.
There are many features that can be assessed and used from this solution to improve how Couchbase users can interrogate their own plans without Couchbase incurring costs from utilising field engineering. A further example would be where large amounts of data are being passed from operator to operator. There is no clear indication that this is the case in the diagram because the connectors between each box is uniform in size. If the width of the connector could be switchable between size of data and number of records it would be much easier to spot where large amounts of data were being processed. Leading to easier resolution.