Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.1.4, 7.1.0, 7.1.1, 7.1.2, 7.2.0, 7.1.3
-
Untriaged
-
1
-
Unknown
-
KV Oct 2022, KV 2023-2
Description
The Problem
In the compaction code we have a callback while compacting that checks if we need to expire a document if its TTL is up. This callback called VBucket::processExpiredItem, which will try and see if the key's item is in the hash table to work out if we can expire it. However, its not resident in memory then we have to perform a background fetch (bg_fetch) for full eviction (though we only need to do this for documents that have expired TTLs on them), as we need to find out if we've got the latest version of the document. Thus, if we have a lot of documents that are now all have TTLs that have expired and are not resident then we will generate loads of read request very quickly. This is problematic for front end ops, as any read requests that come in at the same time that are not resident in memory will have to perform a bg_fetch too. This bg_fetch will be appended to the queue and will be stuck behind potentially 100K bg_fetches before we perform the read for the front end. Hence the OP times out.
Example
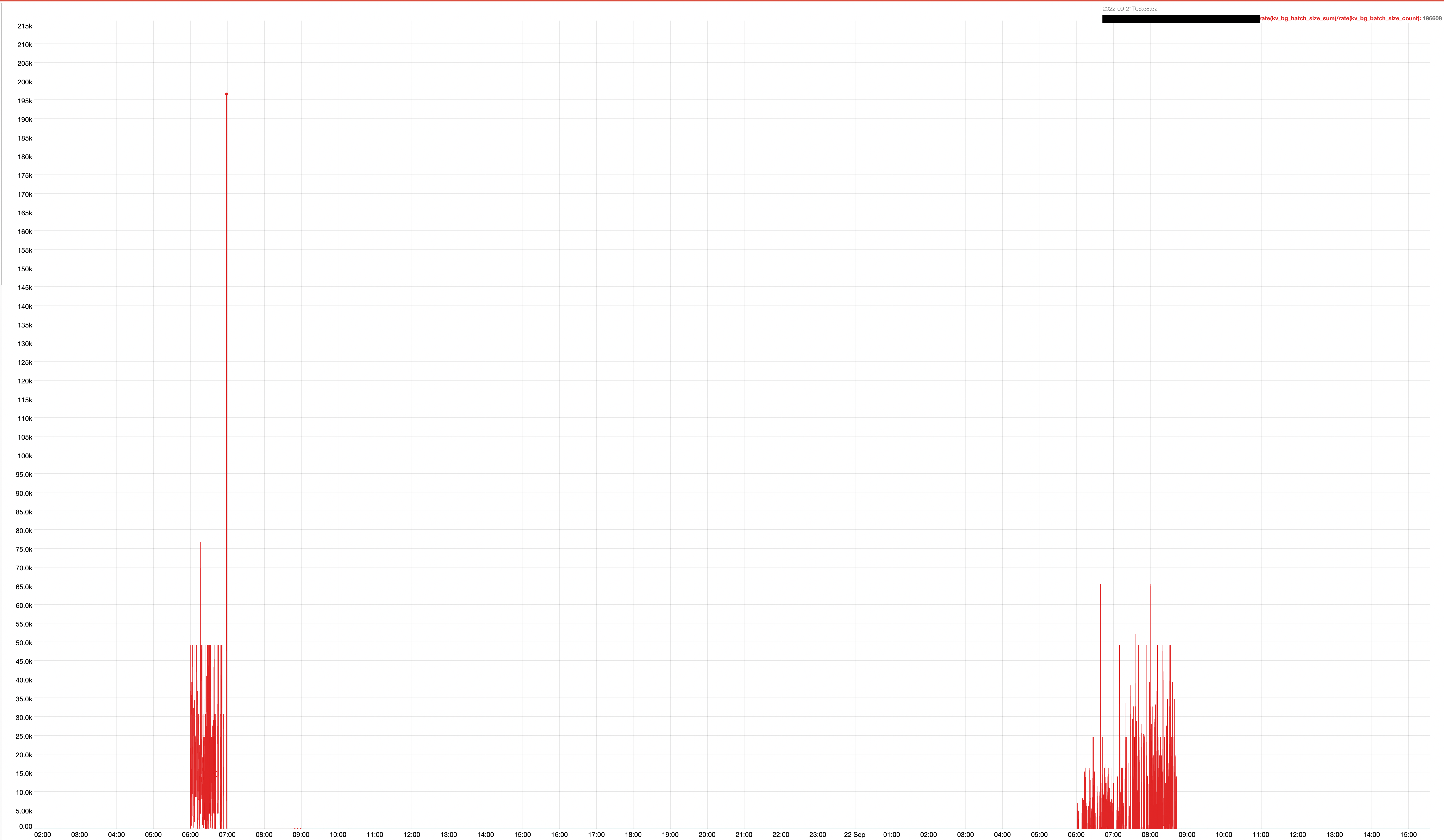
As we can see bellow the long tails show how big our bg_fetch multi requests are getting.
rw_0:getMultiFsReadCount (396001 total)
|
0 - 3 : ( 0.0111%) 44
|
3 - 7 : ( 21.4785%) 85011 #######
|
7 - 7 : ( 21.4785%) 0
|
7 - 8 : ( 47.8577%) 104462 #########
|
8 - 8 : ( 47.8577%) 0
|
8 - 9 : ( 76.2521%) 112442 ##########
|
9 - 9 : ( 76.2521%) 0
|
9 - 10 : ( 92.6255%) 64839 ######
|
10 - 10 : ( 92.6255%) 0
|
10 - 11 : ( 98.1530%) 21889 ##
|
11 - 11 : ( 98.1530%) 0
|
11 - 12 : ( 99.3568%) 4767
|
12 - 12 : ( 99.3568%) 0
|
12 - 13 : ( 99.5657%) 827
|
13 - 13 : ( 99.5657%) 0
|
13 - 14 : ( 99.6338%) 270
|
14 - 15 : ( 99.6843%) 200
|
15 - 16 : ( 99.7200%) 141
|
16 - 17 : ( 99.7457%) 102
|
17 - 20 : ( 99.7697%) 95
|
20 - 159 : ( 99.8053%) 141
|
159 - 271 : ( 99.8255%) 80
|
271 - 447 : ( 99.8442%) 74
|
447 - 2559 : ( 99.8639%) 78
|
2559 - 8703 : ( 99.8833%) 77
|
8703 - 13823 : ( 99.9040%) 82
|
13823 - 16383 : ( 99.9131%) 36
|
16383 - 20479 : ( 99.9237%) 42
|
20479 - 26623 : ( 99.9328%) 36
|
26623 - 61439 : ( 99.9419%) 36
|
61439 - 69631 : ( 99.9558%) 55
|
69631 - 73727 : ( 99.9722%) 65
|
73727 - 73727 : ( 99.9722%) 0
|
73727 - 77823 : ( 99.9896%) 69
|
77823 - 77823 : ( 99.9896%) 0
|
77823 - 81919 : ( 99.9975%) 31
|
81919 - 81919 : ( 99.9975%) 0
|
81919 - 86015 : ( 99.9980%) 2
|
86015 - 86015 : ( 99.9980%) 0
|
86015 - 90111 : ( 99.9982%) 1
|
90111 - 106495 : ( 99.9985%) 1
|
106495 - 122879 : ( 99.9992%) 3
|
122879 - 122879 : ( 99.9992%) 0
|
122879 - 126975 : (100.0000%) 3
|
Avg : ( 65.0)
|
rw_0:getMultiFsReadPerDocCount (396001 total)
|
0 - 1 : ( 0.0626%) 248
|
1 - 7 : ( 21.8517%) 86285 ########
|
7 - 7 : ( 21.8517%) 0
|
7 - 8 : ( 48.2870%) 104684 ##########
|
8 - 8 : ( 48.2870%) 0
|
8 - 9 : ( 76.6915%) 112482 ###########
|
9 - 9 : ( 76.6915%) 0
|
9 - 10 : ( 93.0642%) 64836 ######
|
10 - 10 : ( 93.0642%) 0
|
10 - 11 : ( 98.5846%) 21861 ##
|
11 - 11 : ( 98.5846%) 0
|
11 - 12 : ( 99.7722%) 4703
|
12 - 12 : ( 99.7722%) 0
|
12 - 13 : ( 99.9497%) 703
|
13 - 13 : ( 99.9497%) 0
|
13 - 14 : ( 99.9702%) 81
|
14 - 14 : ( 99.9702%) 0
|
14 - 15 : ( 99.9740%) 15
|
15 - 16 : ( 99.9758%) 7
|
16 - 21 : ( 99.9783%) 10
|
21 - 107 : ( 99.9806%) 9
|
107 - 639 : ( 99.9836%) 12
|
639 - 1023 : ( 99.9854%) 7
|
1023 - 1855 : ( 99.9879%) 10
|
1855 - 2559 : ( 99.9891%) 5
|
2559 - 3199 : ( 99.9904%) 5
|
3199 - 3711 : ( 99.9917%) 5
|
3711 - 4095 : ( 99.9927%) 4
|
4095 - 5119 : ( 99.9939%) 5
|
5119 - 6399 : ( 99.9947%) 3
|
6399 - 7423 : ( 99.9952%) 2
|
7423 - 8703 : ( 99.9962%) 4
|
8703 - 9215 : ( 99.9975%) 5
|
9215 - 9215 : ( 99.9975%) 0
|
9215 - 9727 : ( 99.9980%) 2
|
9727 - 9727 : ( 99.9980%) 0
|
9727 - 10239 : ( 99.9982%) 1
|
10239 - 10751 : ( 99.9990%) 3
|
10751 - 10751 : ( 99.9990%) 0
|
10751 - 11263 : ( 99.9995%) 2
|
11263 - 11263 : ( 99.9995%) 0
|
11263 - 11775 : (100.0000%) 2
|
Avg : ( 9.0)
|
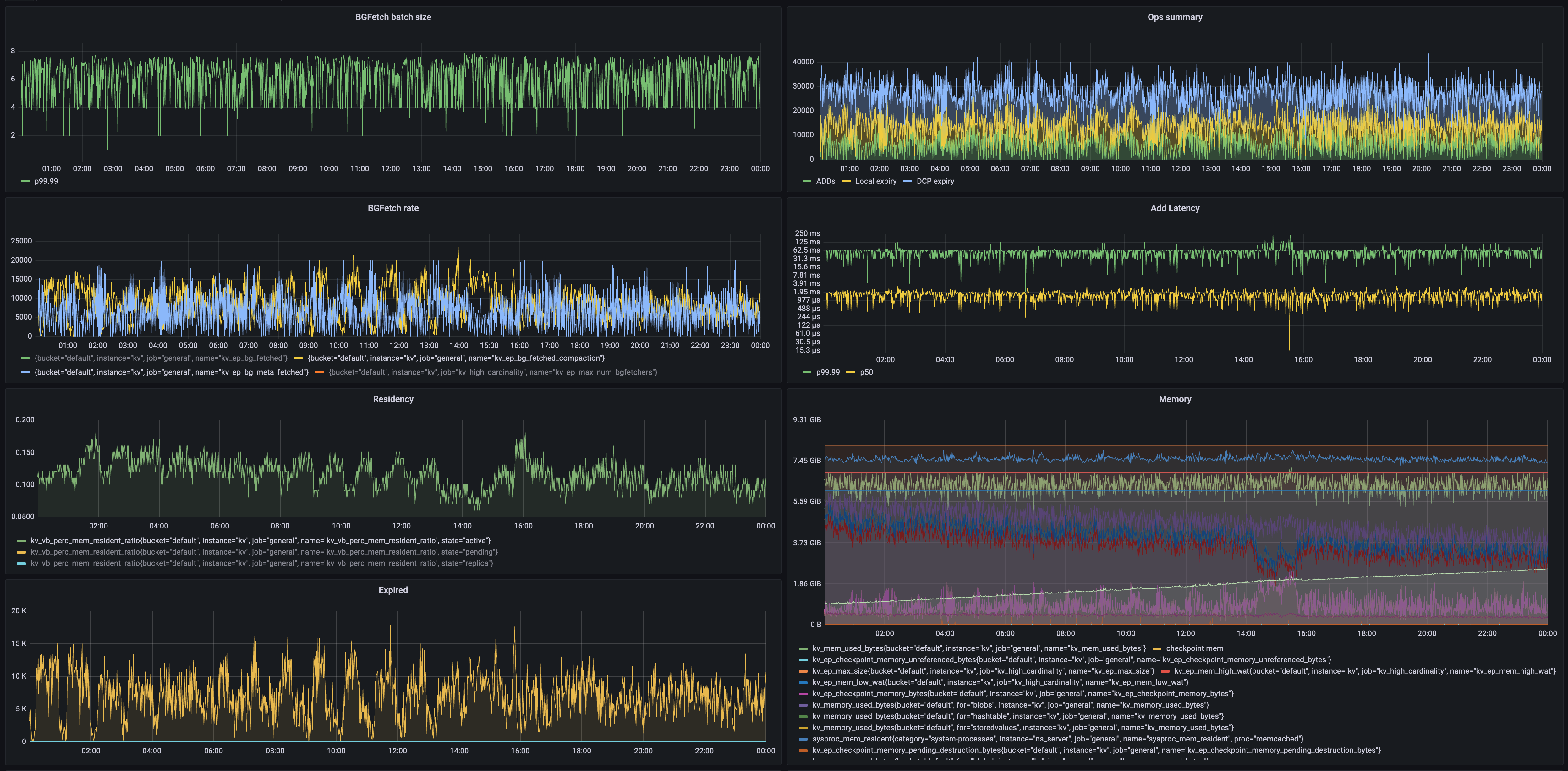
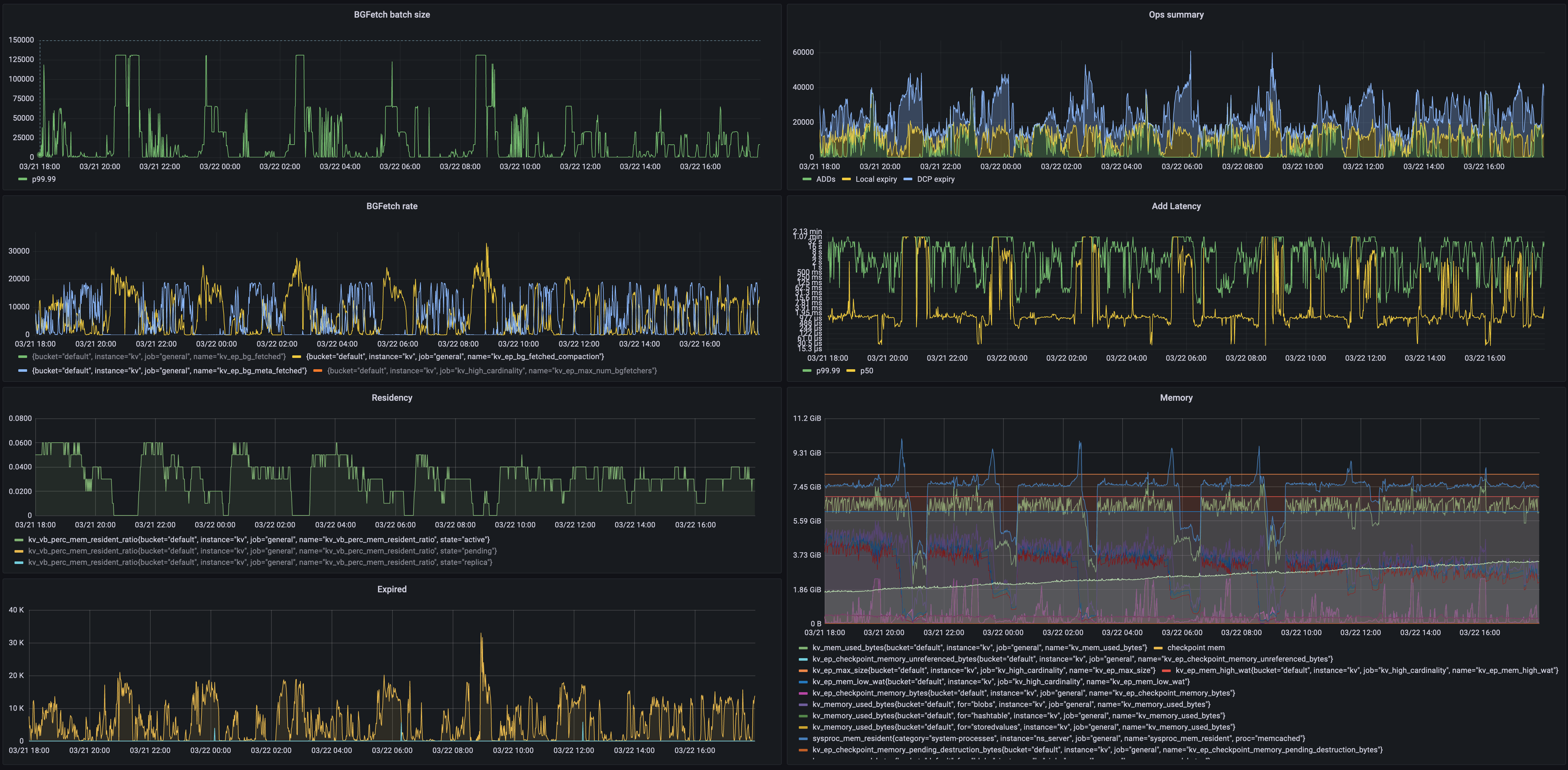
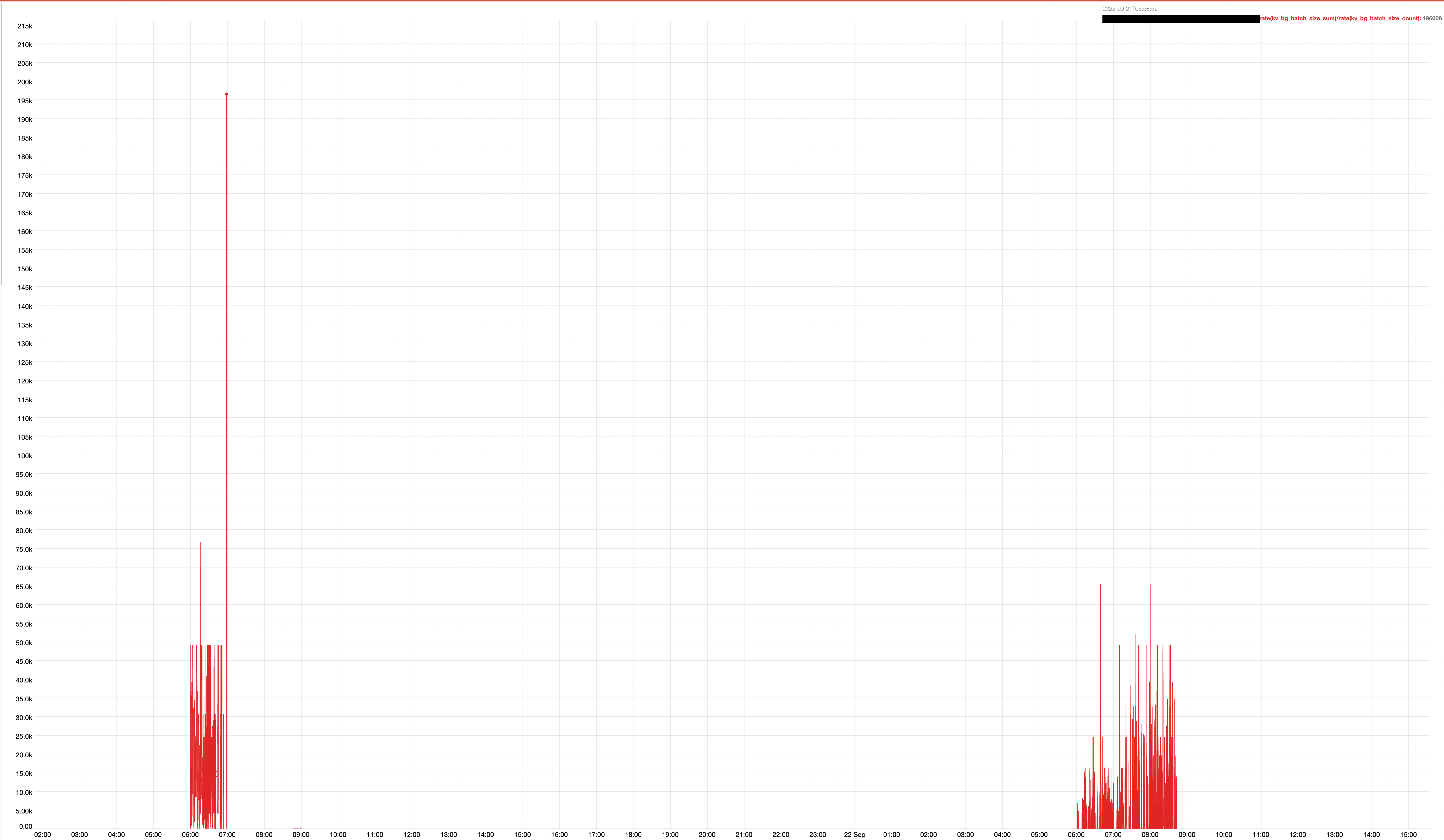
Bellow we can see the large size of the bg_fetch queues being generated for expiry during two compaction windows.
| Issue | Resolution |
| When expired documents were identified during compaction, the Data Service queued a read of the documents' metadata as part of expiry processing. No upper bound was imposed on the size of this queue. This could result in exceeding the Bucket quota for workloads when large amounts of documents expired in a short time. | Metadata reads for TTL processing are not now queued. Instead, they are processed inline. Consequently, Bucket quota is no longer exceeded. |
Attachments
Issue Links
- is triggering
-
-
- Closed
-