Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.2.0
-
Enterprise Edition 7.2.0 build 5263
-
Untriaged
-
Centos 64-bit
-
-
0
-
Unknown
-
KV 2023-4
Description
QE TEST
We are basically running Neo Magma longevity test with history enabled for all buckets.
-test tests/integration/7.2/test_7.2.yml -scope tests/integration/7.2/scope_7.2_magma.yml |
Day - 1
Cycle - 1
Scale - 3
TEST STEP
Perform failover and recovery of Indexer node 172.23.96.253.
[2023-03-22T13:44:33-07:00, sequoiatools/couchbase-cli:7.1:6ea657] failover -c 172.23.108.103:8091 --server-failover 172.23.96.253:8091 -u Administrator -p password --hard |
[2023-03-22T13:44:41-07:00, sequoiatools/couchbase-cli:7.1:8b1463] recovery -c 172.23.108.103:8091 --server-recovery 172.23.96.253:8091 --recovery-type full -u Administrator -p password |
[2023-03-22T13:44:47-07:00, sequoiatools/couchbase-cli:7.1:c40dfc] rebalance -c 172.23.108.103:8091 -u Administrator -p password |
OBSERVATION
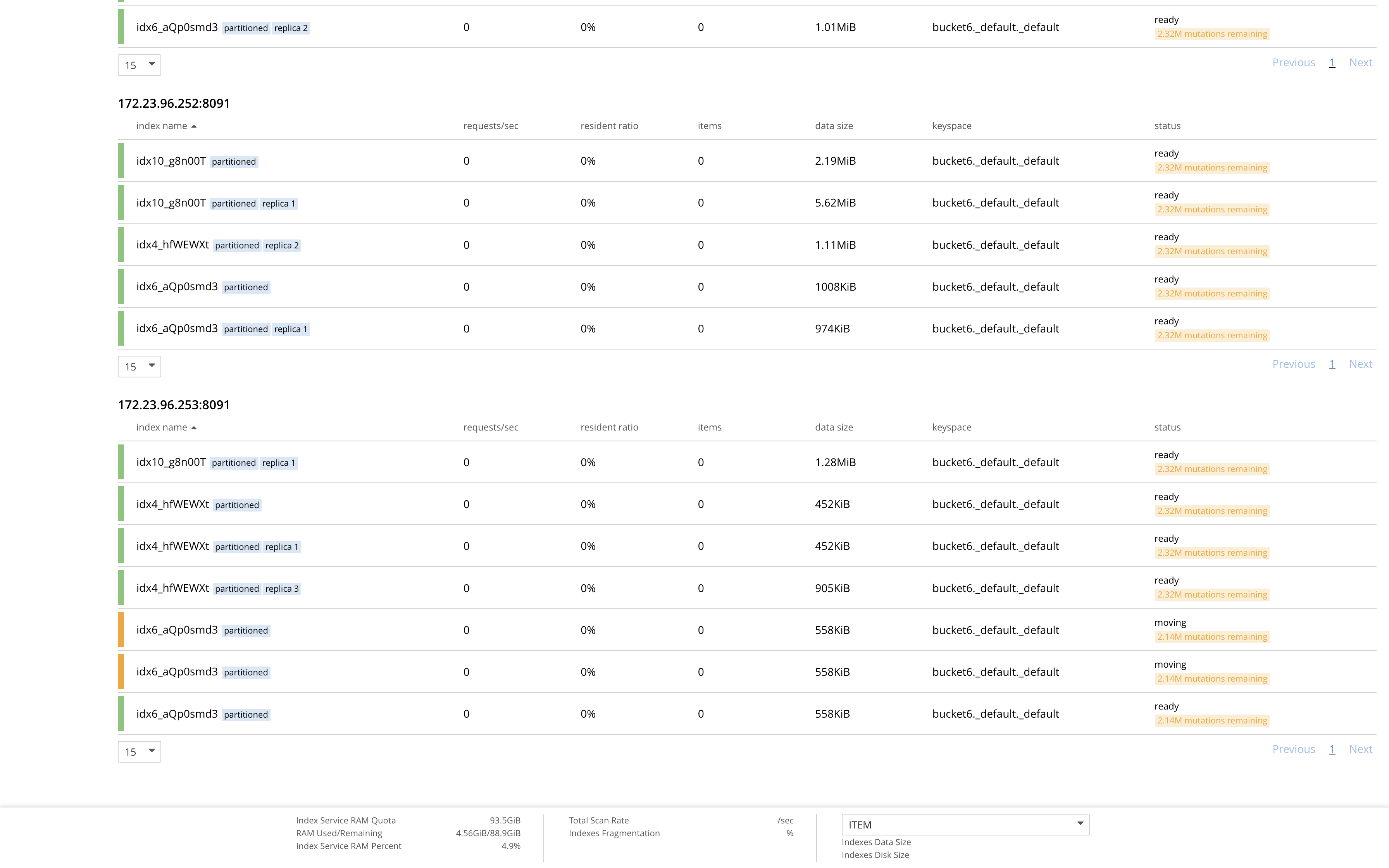
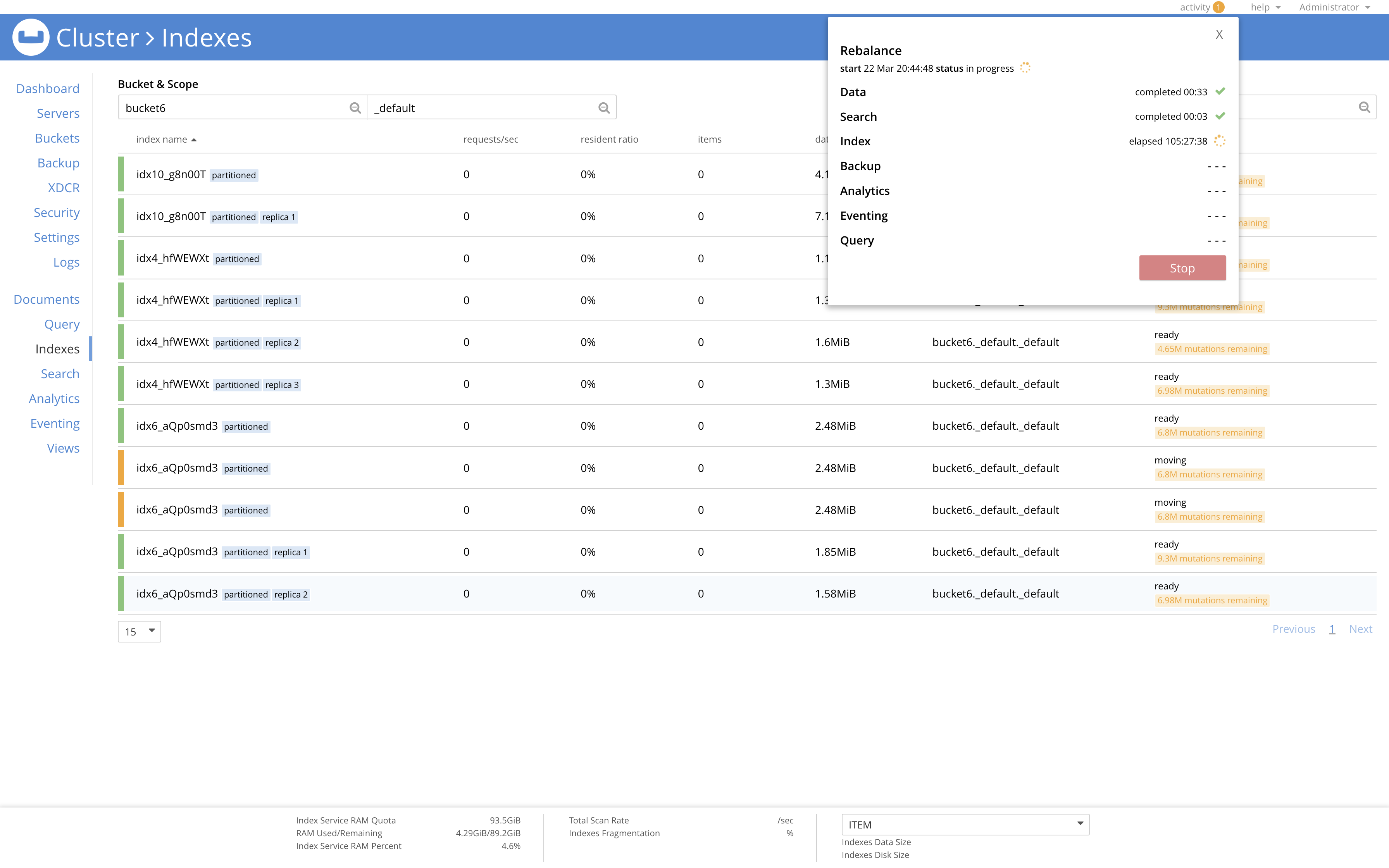
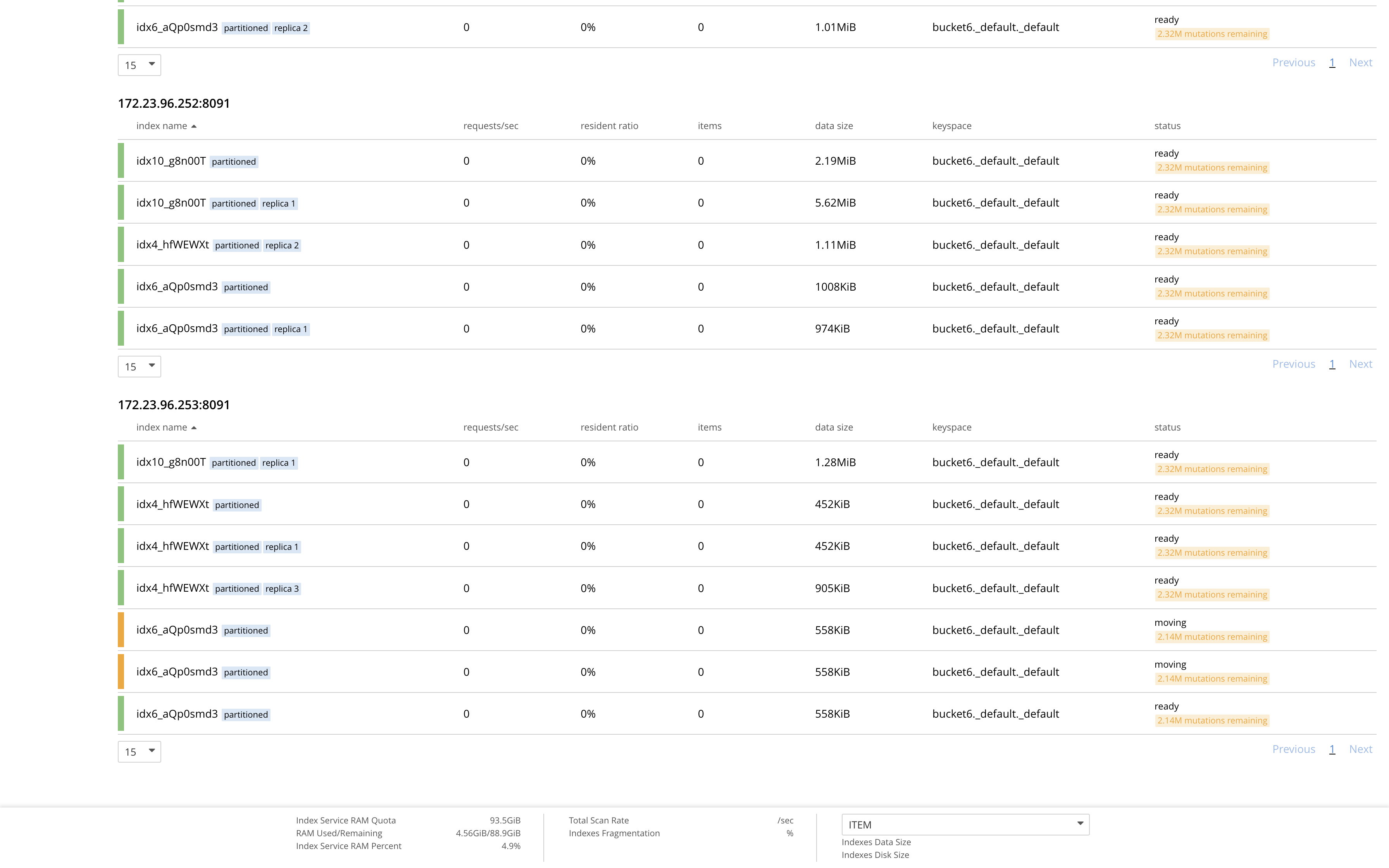
GSI rebalance is ongoing for more than 100 hours now as idx6_aQp0smd3 Index and 1 of its of replica created on bucket6._default._default keyspace seems to be stuck in moving state.
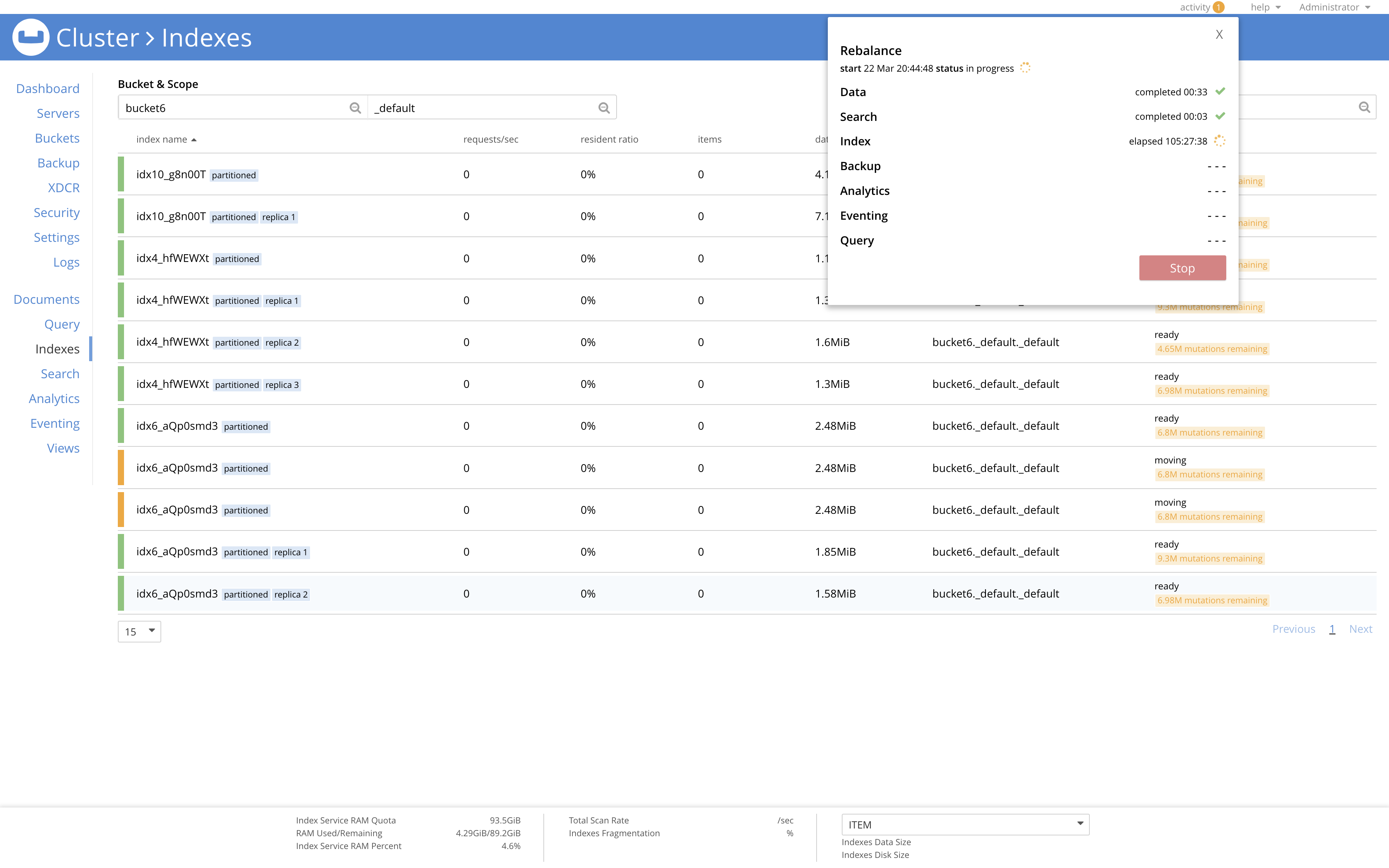
Output of getIndexStatus endpoint -
{
|
"defnId": 8475177595633816000, |
"instId": 16023641909358130000, |
"name": "idx6_aQp0smd3 (replica 2)", |
"bucket": "bucket6", |
"scope": "_default", |
"collection": "_default", |
"secExprs": [ |
"`city`" |
],
|
"indexType": "plasma", |
"status": "Ready", |
"definition": "CREATE INDEX `idx6_aQp0smd3` ON `bucket6`(`city`) PARTITION BY hash((meta().`id`)) WITH { \"defer_build\":true, \"nodes\":[ \"172.23.104.137:8091\",\"172.23.120.245:8091\",\"172.23.121.117:8091\",\"172.23.96.252:8091\",\"172.23.96.253:8091\" ], \"num_replica\":2, \"num_partition\":5 }", |
"hosts": [ |
"172.23.104.137:8091", |
"172.23.120.245:8091", |
"172.23.121.117:8091" |
],
|
"completion": 100, |
"progress": 100, |
"scheduled": false, |
"partitioned": true, |
"numPartition": 5, |
"partitionMap": { |
"172.23.104.137:8091": [ |
4 |
],
|
"172.23.120.245:8091": [ |
2, |
1 |
],
|
"172.23.121.117:8091": [ |
3, |
5 |
]
|
},
|
"numReplica": 2, |
"indexName": "idx6_aQp0smd3", |
"replicaId": 2, |
"stale": false, |
"lastScanTime": "NA" |
},
|
{
|
"defnId": 2145631136244863500, |
"instId": 14067760530236017000, |
"name": "idx6_jbjp4g5U", |
"bucket": "bucket7", |
"scope": "scope_0", |
"collection": "coll_4", |
"secExprs": [ |
"`city`" |
],
|
"indexType": "plasma", |
"status": "Ready", |
"definition": "CREATE INDEX `idx6_jbjp4g5U` ON `bucket7`.`scope_0`.`coll_4`(`city`) PARTITION BY hash((meta().`id`)) WITH { \"nodes\":[ \"172.23.104.137:8091\",\"172.23.120.245:8091\",\"172.23.121.117:8091\",\"172.23.96.253:8091\" ], \"num_replica\":2, \"num_partition\":2 }", |
"hosts": [ |
"172.23.104.137:8091", |
"172.23.121.117:8091" |
],
|
"completion": 100, |
"progress": 100, |
"scheduled": false, |
"partitioned": true, |
"numPartition": 2, |
"partitionMap": { |
"172.23.104.137:8091": [ |
2 |
],
|
"172.23.121.117:8091": [ |
1 |
]
|
},
|
"numReplica": 2, |
"indexName": "idx6_jbjp4g5U", |
"replicaId": 0, |
"stale": false, |
"lastScanTime": "NA" |
}
|
The issue seems to be on the Indexer node which was failed over, ie - 172.23.96.253.
Attachments
Issue Links
- relates to
-
MB-30782 Janitor should be run when service rebalance is in progress
-

- Reopened
-