Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
7.1.4
-
Untriaged
-
0
-
Unknown
Description
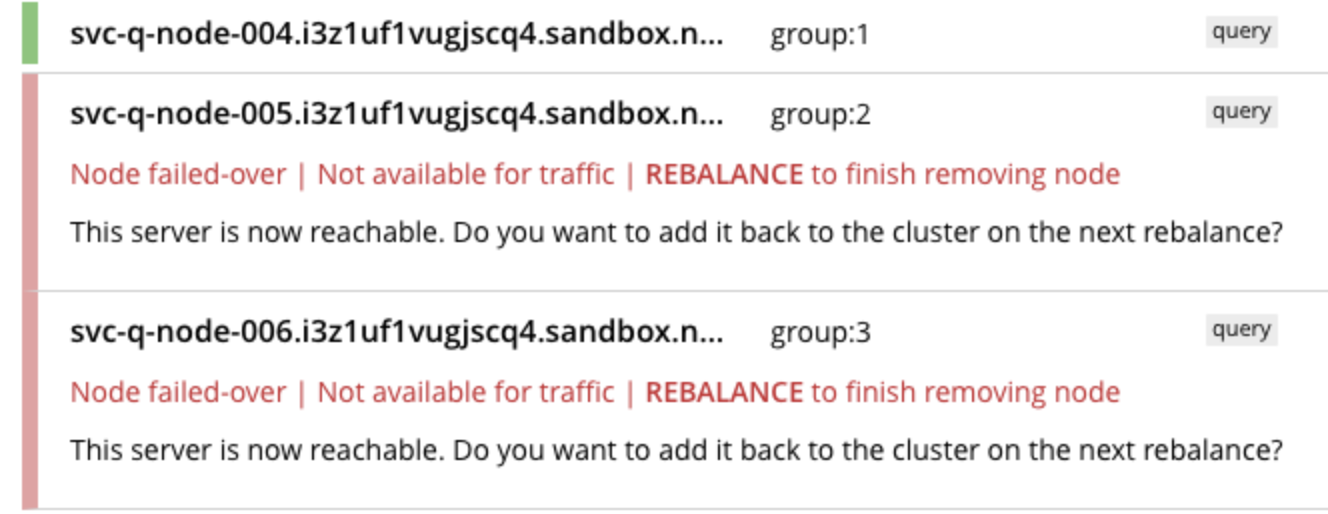
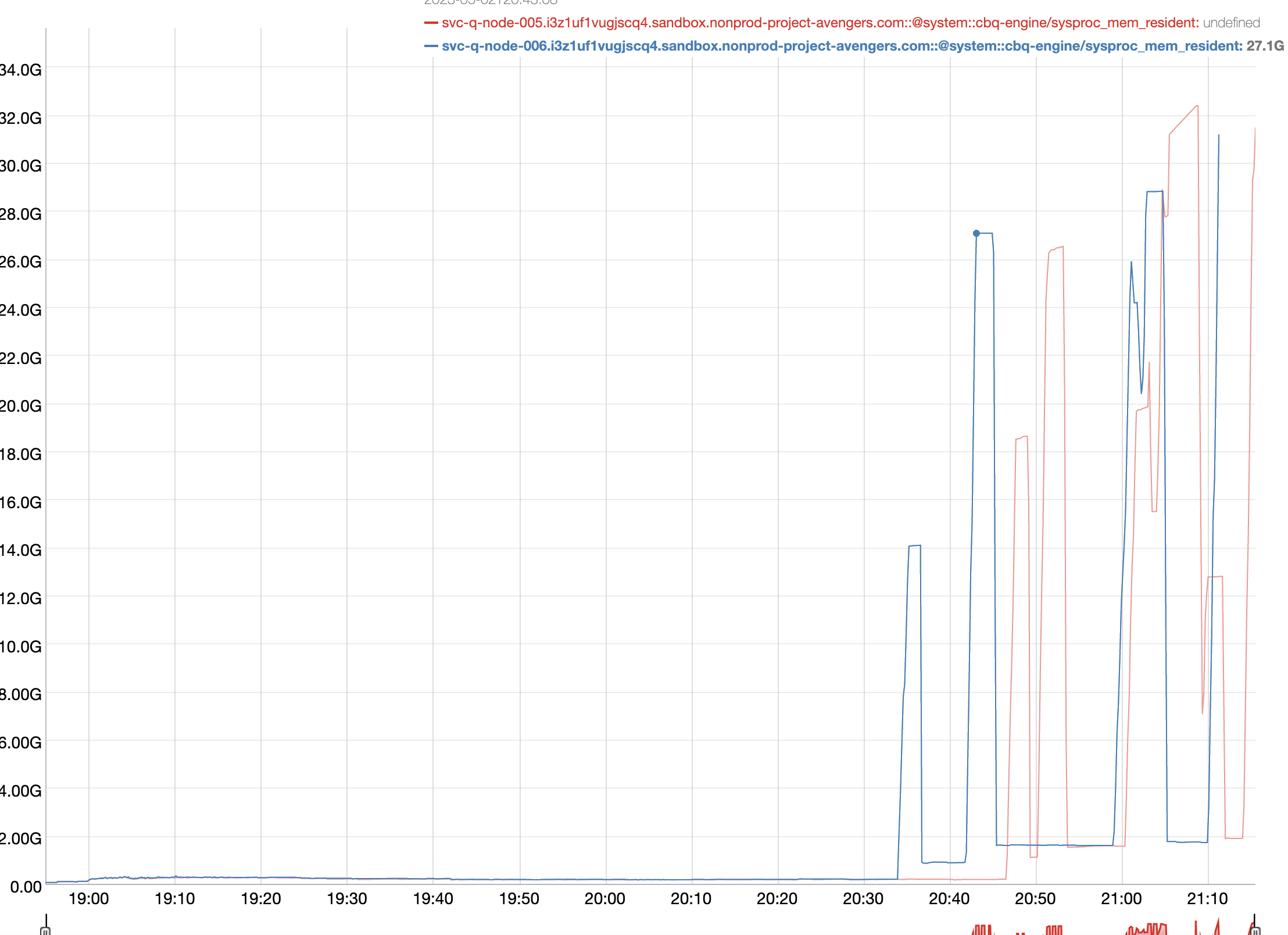
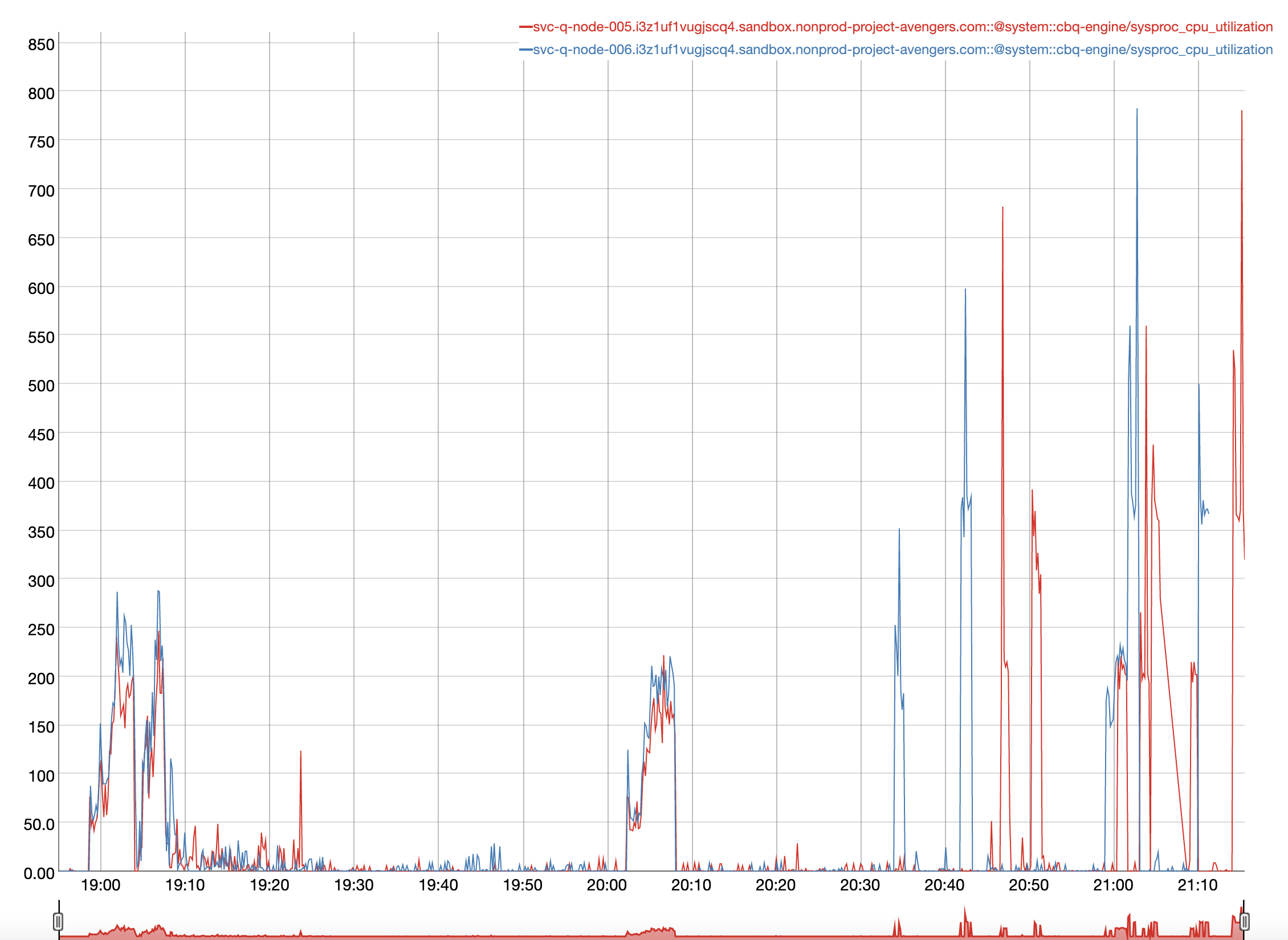
The following issue occurred during a cluster rebalance on Capella, with an app service (sync gateway) workload ongoing. During the rebalance, all nodes were able to successfully rebalance apart from the query nodes. The app service workload posts, gets, and deletes n new docs through the app service, then gets all the bucket's document IDs through the SGW's
/db/_all_docs
|
endpoint.
This issue occurred two separate times on separate clusters - one with and one without XDCR.
The query nodes were eventually recovered after the app service workload had ended.
The following supportal logs are related to the cluster in question: https://supportal.couchbase.com/snapshot/1052f1aa4916cf5051ad729d55bed5ee::0