Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.2.1
-
7.2.1-5819
-
Untriaged
-
-
0
-
Unknown
-
Analytics Sprint 22
Description
- Create a 6 node all services co-located cluster. Create a bucket, 2 collections, and load 50k items in each collection
- Create GSI/FTS indexes, CBAS datasets/indexes. Let ingestion for all to complete.
- Start the query load for all the services.
- Scale up cluster from 6->9 At each scaling completion increment the query workload post the scaling completion.
- Scale down cluster from 9->6. Before each scaling operation decrement the query workload before starting the scaling completion.
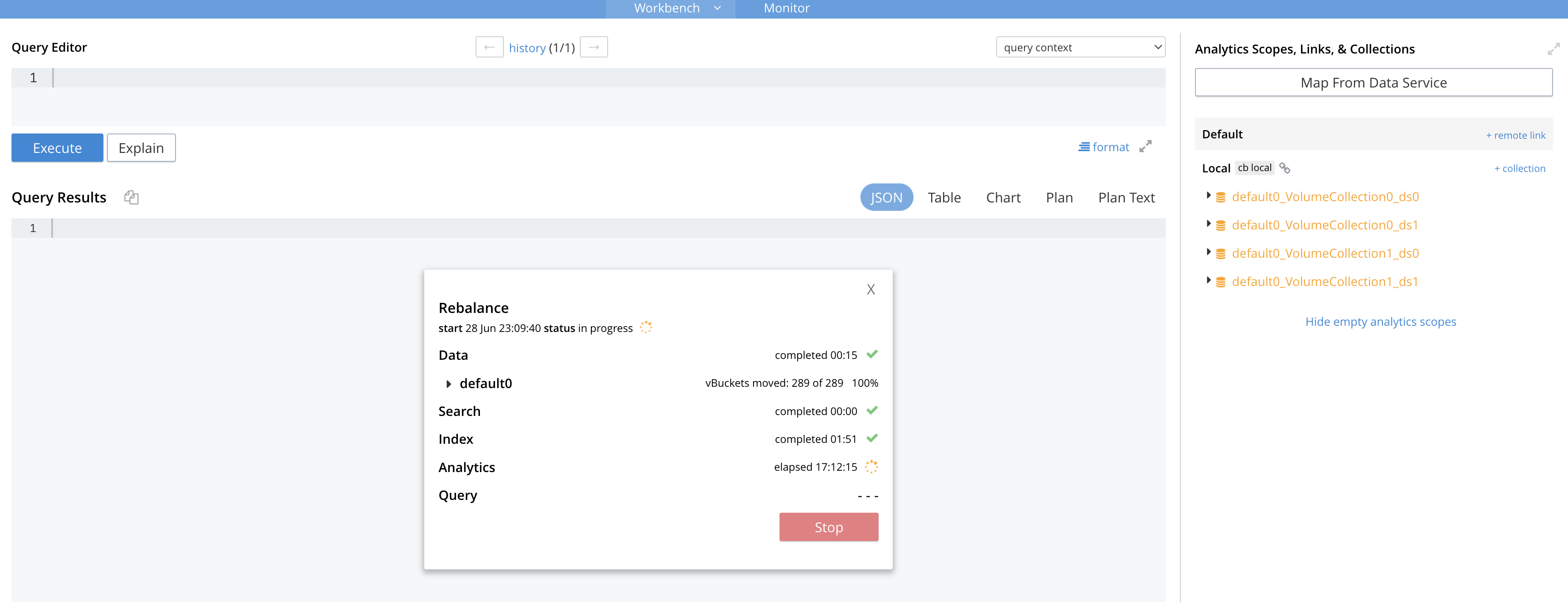
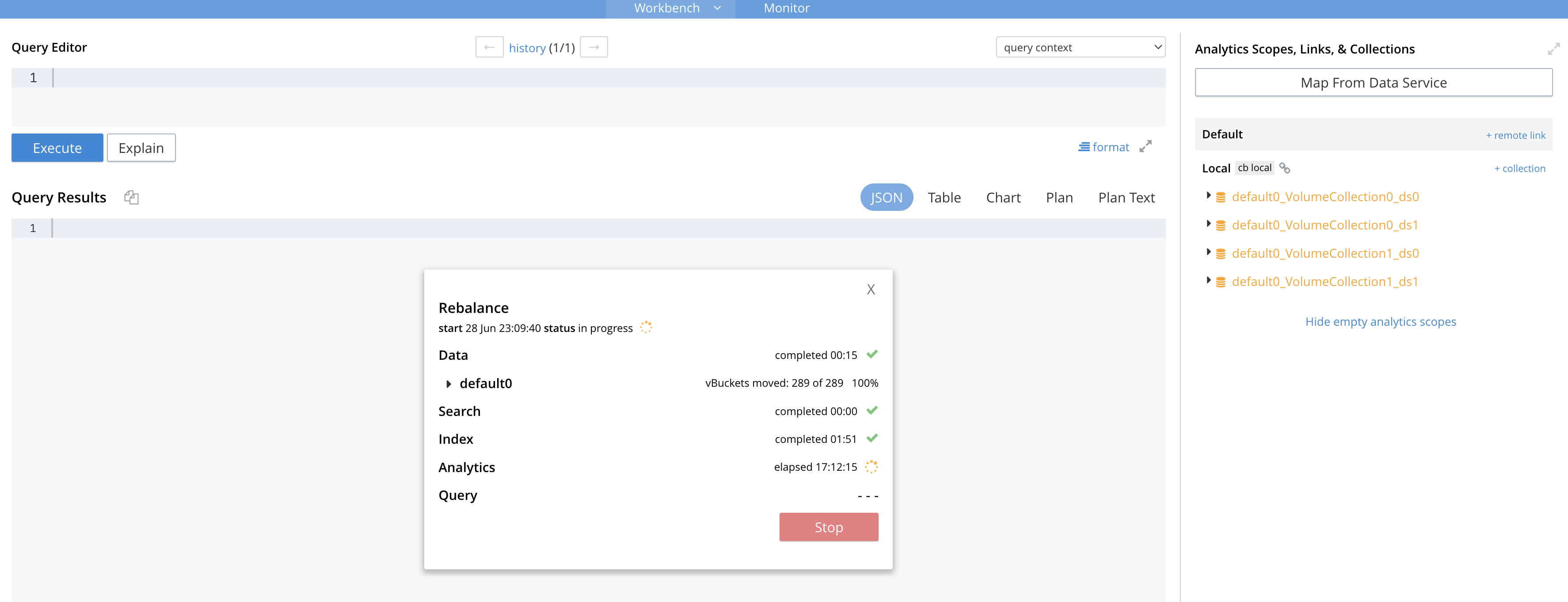
- At the last scale down from 6 nodes to 3 nodes, the rebalance out of the last node is stuck during analytics rebalancing:
|
Test |
git fetch https://review.couchbase.org/TAF refs/changes/51/193151/4 && git checkout FETCH_HEAD
|
|
|
sudo guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/couchbase_capella_volume_2.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.hostedHospital.Murphy.test_rebalance,nodes_init=6,graceful=True,skip_cleanup=True,num_items=50000,num_buckets=1,bucket_names=GleamBook,doc_size=1024,bucket_type=membase,eviction_policy=fullEviction,iterations=2,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,maxttl=10,pc=20,gsi_nodes=3,cbas_nodes=3,fts_nodes=3,kv_nodes=3,n1ql_nodes=3,kv_disk=300,n1ql_disk=50,gsi_disk=300,fts_disk=300,cbas_disk=300,kv_compute=n2-standard-16,gsi_compute=n2-standard-16,n1ql_compute=n2-standard-16,fts_compute=n2-standard-16,cbas_compute=n2-standard-16,mutation_perc=20,key_type=CircularKey,capella_run=true,services=data:query:index:analytics:search,max_rebl_nodes=27,provider=GCP,region=us-east1,type=PD-SSD,size=300,skip_teardown_cleanup=false,wait_timeout=14400,index_timeout=28800,runtype=dedicated,sanity=True -m rest'
|
Attachments
Issue Links
- links to