Details
-
Bug
-
Resolution: Known Error
-
 Blocker
Blocker
-
None
-
7.2.1
-
couchbase-cloud-server-7.2.1-5878-v1.0.19
-
Untriaged
-
0
-
Unknown
Description
Cluster Config:
3 KV nodes, 2 GSI/N1QL nodes
c5.2xlarge instance types
Data service RAM quota: 12800MB
Steps:
- Create a cluster with the above config
- Create a bucket, 10 collections. Load 100M items in each collection
- Create GSI indexes on 2 collections and let them build completely. Start a N1QL query workload
- Start a 10k R:W workload with 10s expiry.
- Scale UP/Down the cluster a few times by increasing/decreasing the nodes in a service groups by 1
- When there are 4 KV nodes and 3 GSI nodes trigger a backup. Back up completes successfully
- Flush the bucket. Indexes rollbacks to 0.
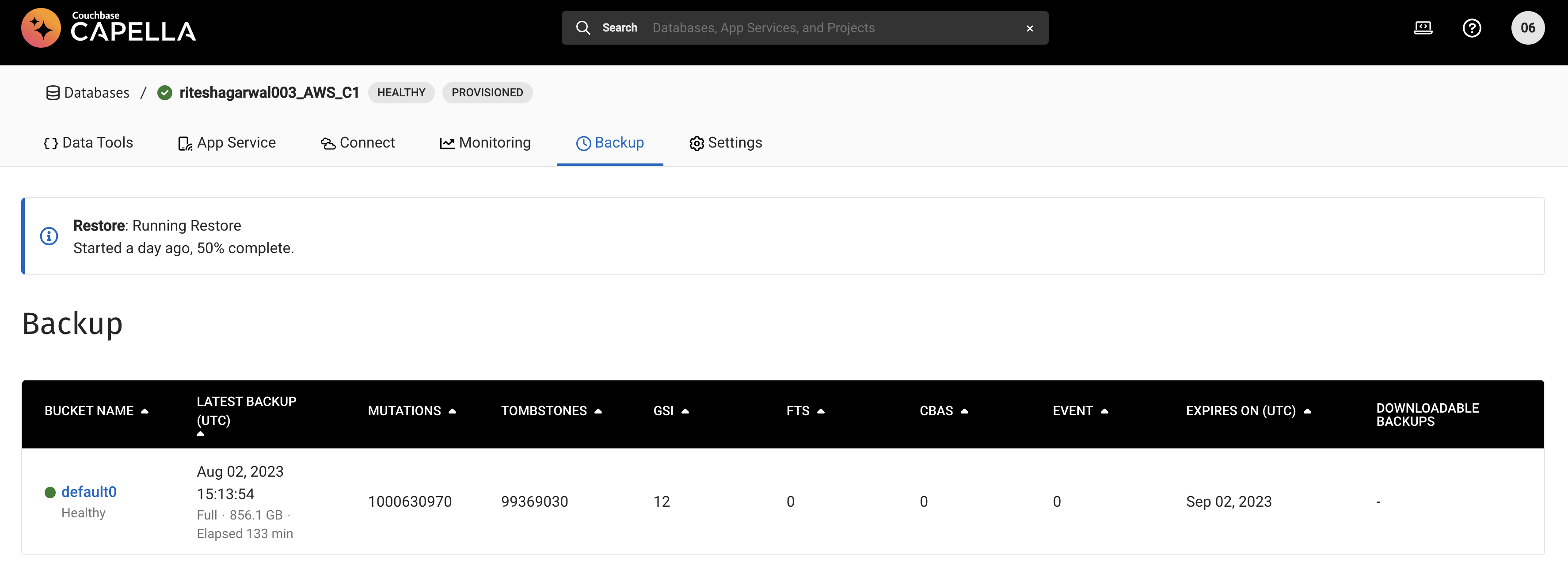
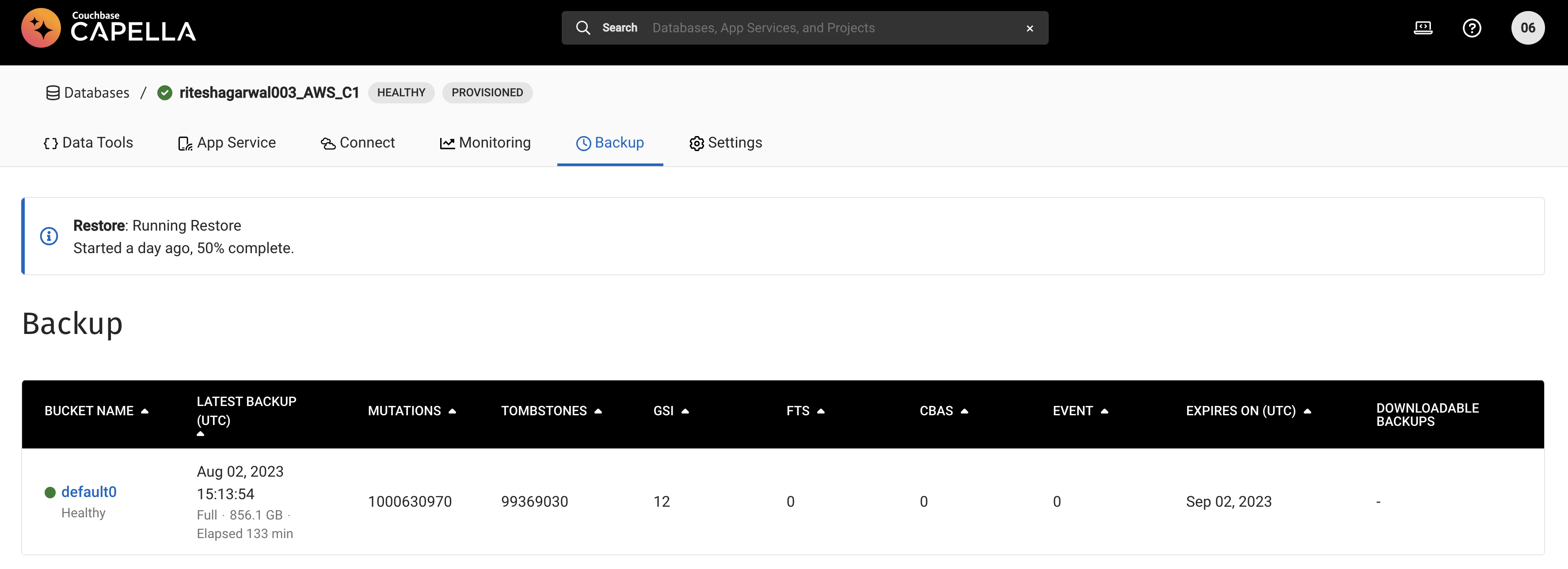
- Trigger a restore and restore is hung at 668,309,473 items.
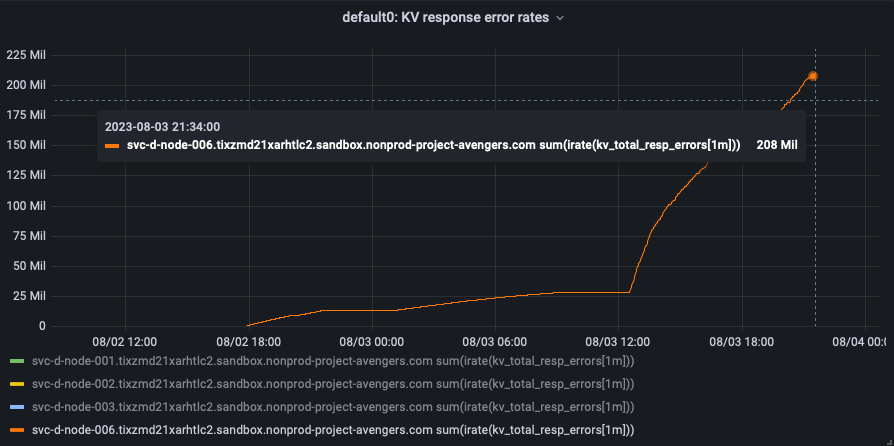
The restoration of 1000630970 mutations which has 99369030 tombstones reportedly, failed. I can see that the restore is still running on the backup node:
sh-4.2$ ps -aef | grep restore
|
ssm-user 12389 12381 0 21:25 pts/0 00:00:00 grep restore
|
ec2-user 16381 2382 99 12:30 ? 09:09:17 /opt/couchbase/bin/cbbackupmgr restore -a s3://cbc-storage-3f11ad/backups/buckets/default0/cycles/553531be-b401-4d46-a1cd-b3b3f46a6db1 -r 553531be-b401-4d46-a1cd-b3b3f46a6db1 -c couchbases://svc-d-node-001.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-d-node-002.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-d-node-003.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-d-node-006.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-qi-node-004.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-qi-node-005.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com,svc-qi-node-007.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com -u couchbase-cloud-admin -p BJvgA%6@P!lXP7Sso2BDkpZE --obj-staging-dir /home/ec2-user/staging/553531be-b401-4d46-a1cd-b3b3f46a6db1 --auto-select-threads --json-progress restore --cacert /home/ec2-user/ca.pem --start start --end 2023-08-02T15_14_03.318274428Z --purge
|
sh-4.2$ df -h
|
Filesystem Size Used Avail Use% Mounted on
|
devtmpfs 7.7G 0 7.7G 0% /dev
|
tmpfs 7.7G 0 7.7G 0% /dev/shm
|
tmpfs 7.7G 392K 7.7G 1% /run
|
tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup
|
/dev/nvme0n1p1 1.0T 74G 951G 8% /
|
tmpfs 1.6G 0 1.6G 0% /run/user/994
|
sh-4.2$
|
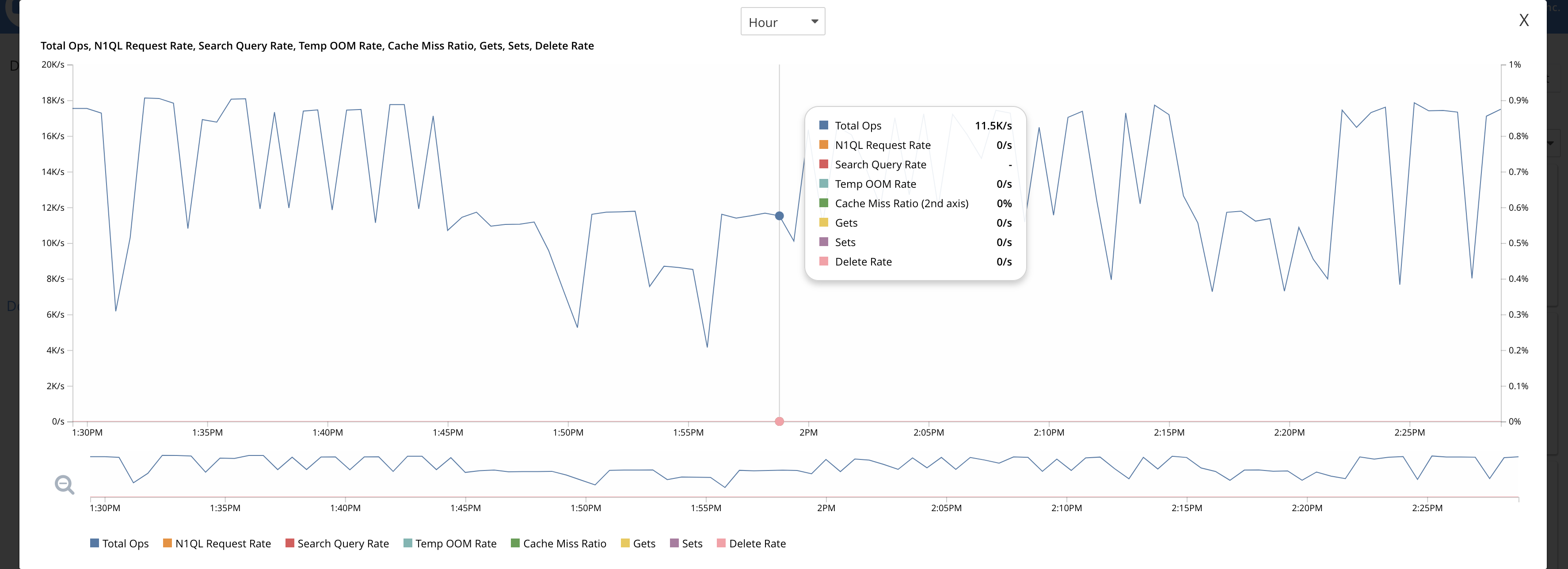
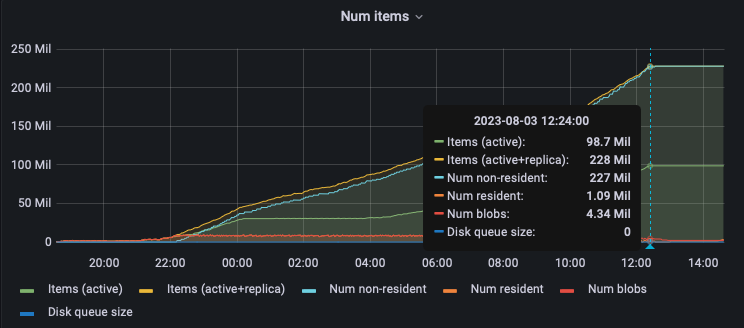
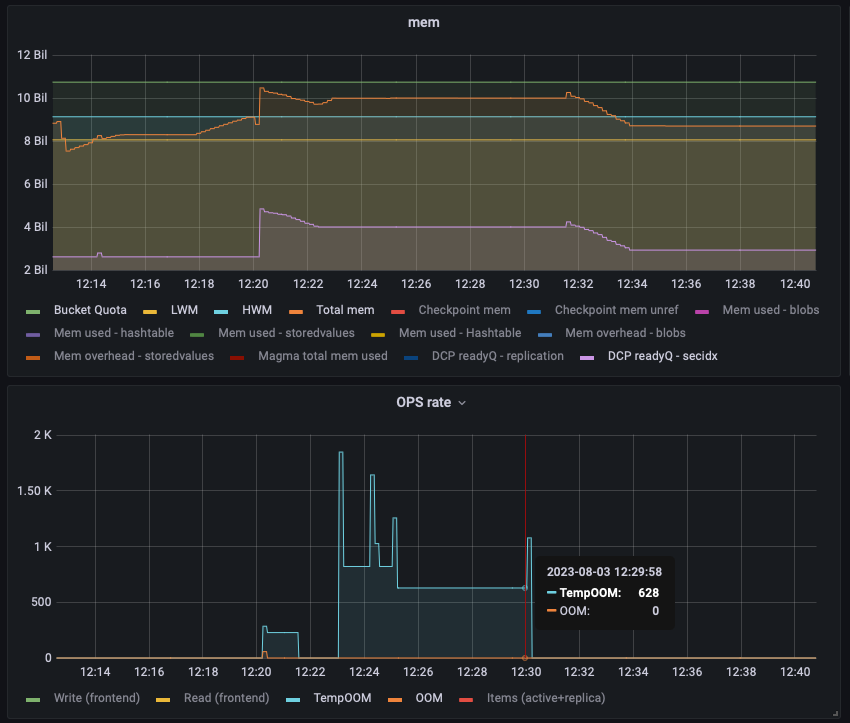
Bucket: The constant ops are coming in as seen in the dashboard but not sure where they are going as the items count isn’t increasing at all:
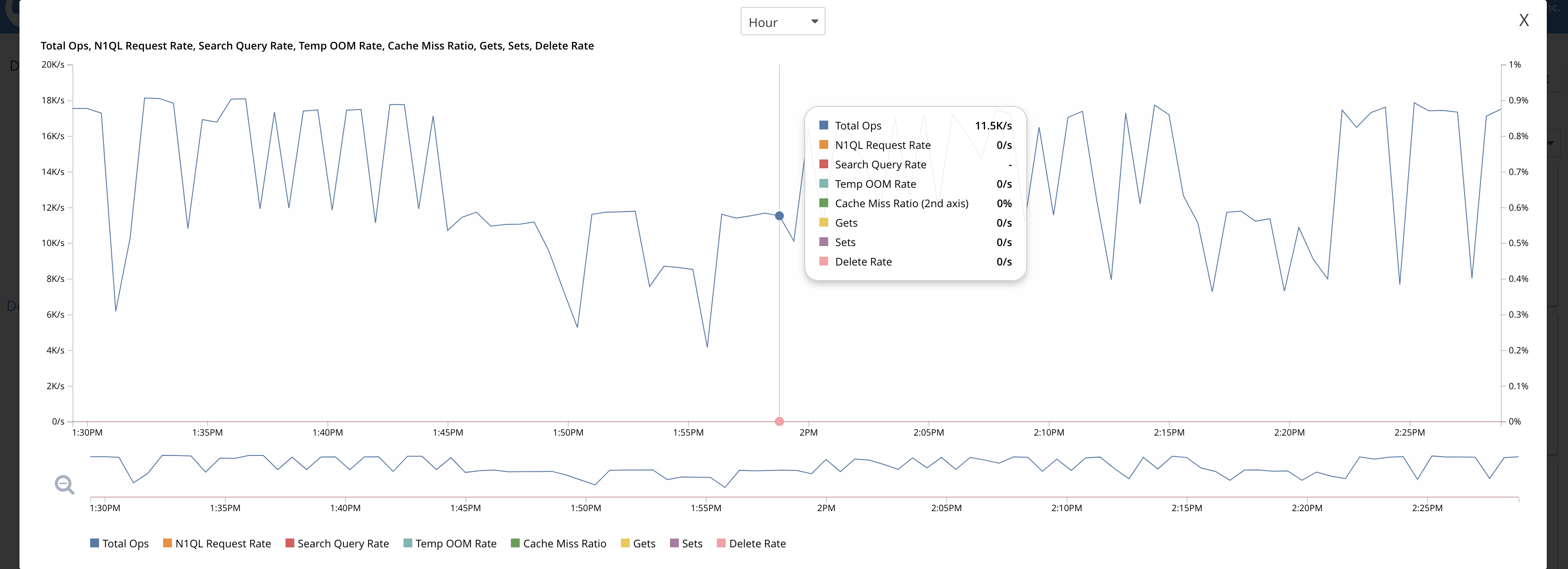

It seems that the RAM quota is completely blocked and the RAM is not getting released to accept the further mutations. But while the eviction policy is fullEviction why the ram isn’t getting freed up for the upcoming traffic from restore?
Environment
- Database Type: Provisioned
- Is the database still running?: NO
- Environment: sandbox
- Organisation ID (aka Tenant ID): 82c310b9-1c07-468c-a36c-7423cde5f7ed
- Project ID: 3c81cb13-4ff7-474b-b729-3e29cbf6f738
- Cluster/Database ID: 80786aba-8cdb-47a8-a5b1-d6f0a73f11ad
Server Logs:
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-d-node-001.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-d-node-002.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-d-node-003.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-d-node-006.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-qi-node-004.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-qi-node-005.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
s3://cb-customers-secure/restore/2023-08-03/collectinfo-2023-08-03t211604-ns_1@svc-qi-node-007.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com.zip
|
Backup Logs:
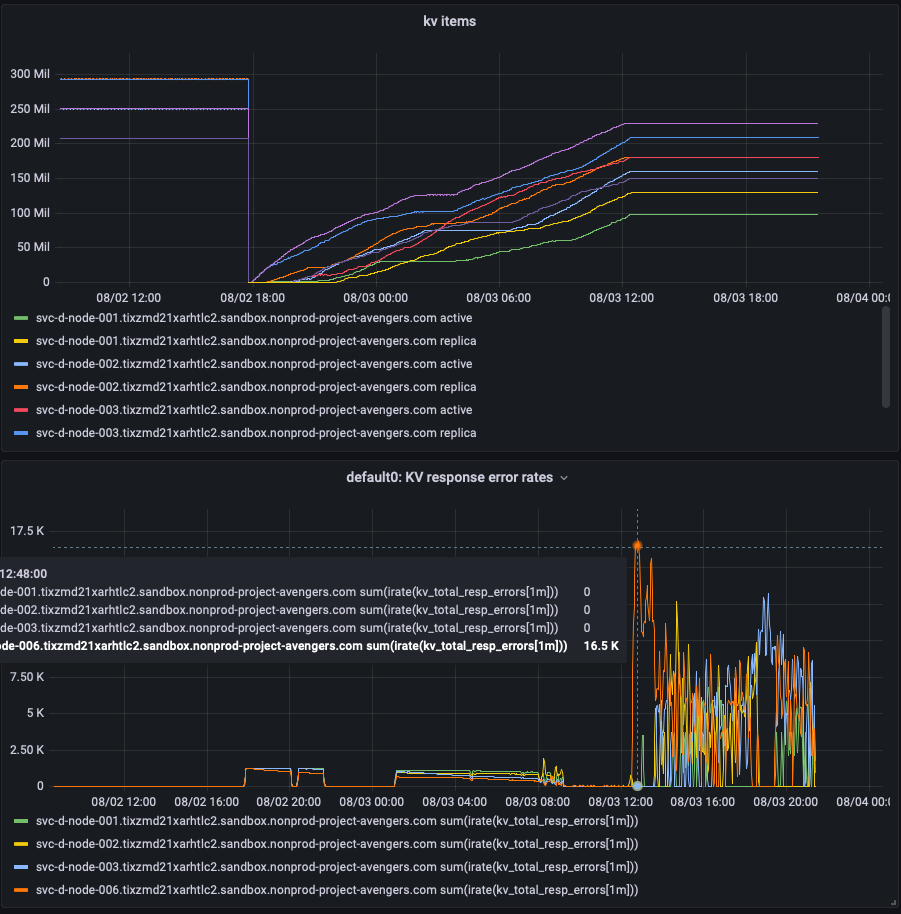
{"InnerError":{"InnerError":{"InnerError":{},"Message":"ambiguous timeout"}},"OperationID":"SetMeta","Opaque":"58827611","TimeObserved":300000018315,"RetryReasons":["KV_TEMPORARY_FAILURE"],"RetryAttempts":125,"LastDispatchedTo":"svc-d-node-002.tixzmd21xarhtlc2.sandbox.nonprod-project-avengers.com:11207","LastDispatchedFrom":"10.2.2.232:40004","LastConnectionID":"d31e460be1233941/cee443be6a947dcf","Internal":{"ResourceUnits":null}} -- couchbase.(*MemcachedWorker).processOperation() at pool_worker.go:279 |
cc: Raju Suravarjjala, Ritam Sharma This seems to be a KV(server) bug to me.
cc: James Lee, Shelby Ramsey
|
QE Test |
sudo guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/couchbase_capella_volume_2_new.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.hostedHospital.Murphy.test_rebalance,num_items=100000000,num_buckets=1,bucket_names=GleamBook,bucket_type=membase,iterations=1,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,maxttl=10,pc=20,gsi_nodes=2,cbas_nodes=2,fts_nodes=2,kv_nodes=3,n1ql_nodes=2,kv_disk=1000,n1ql_disk=50,gsi_disk=500,fts_disk=1000,cbas_disk=1000,kv_compute=c5.2xlarge,gsi_compute=c5.2xlarge,n1ql_compute=c5.2xlarge,fts_compute=c5.2xlarge,cbas_compute=c5.2xlarge,mutation_perc=20,key_type=CircularKey,capella_run=true,services=data-index:query,rebl_services=data-index:query,max_rebl_nodes=27,provider=AWS,region=us-east-1,type=GP3,size=1000,collections=10,ops_rate=100000,skip_teardown_cleanup=true,wait_timeout=14400,index_timeout=28800,runtype=dedicated,skip_init=true,rebl_ops_rate=10000,collections=10,expiry=true,vh_scaling=true,horizontal_scale=1 -m rest'
|