Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
7.2.1
-
7.2.1-5890
-
Untriaged
-
-
0
-
Unknown
Description
Better config than: MB-57597
Cluster Config:
8 nodes: 3 KV(36c 72G), 3 GSI(32c, 128G), 2 N1QL(16c, 32G)
Total Indexer RAM:
345GiB
Total Data indexed so far:
Indexes Data Size 1.68TiB
Indexes Disk Size 528GiB
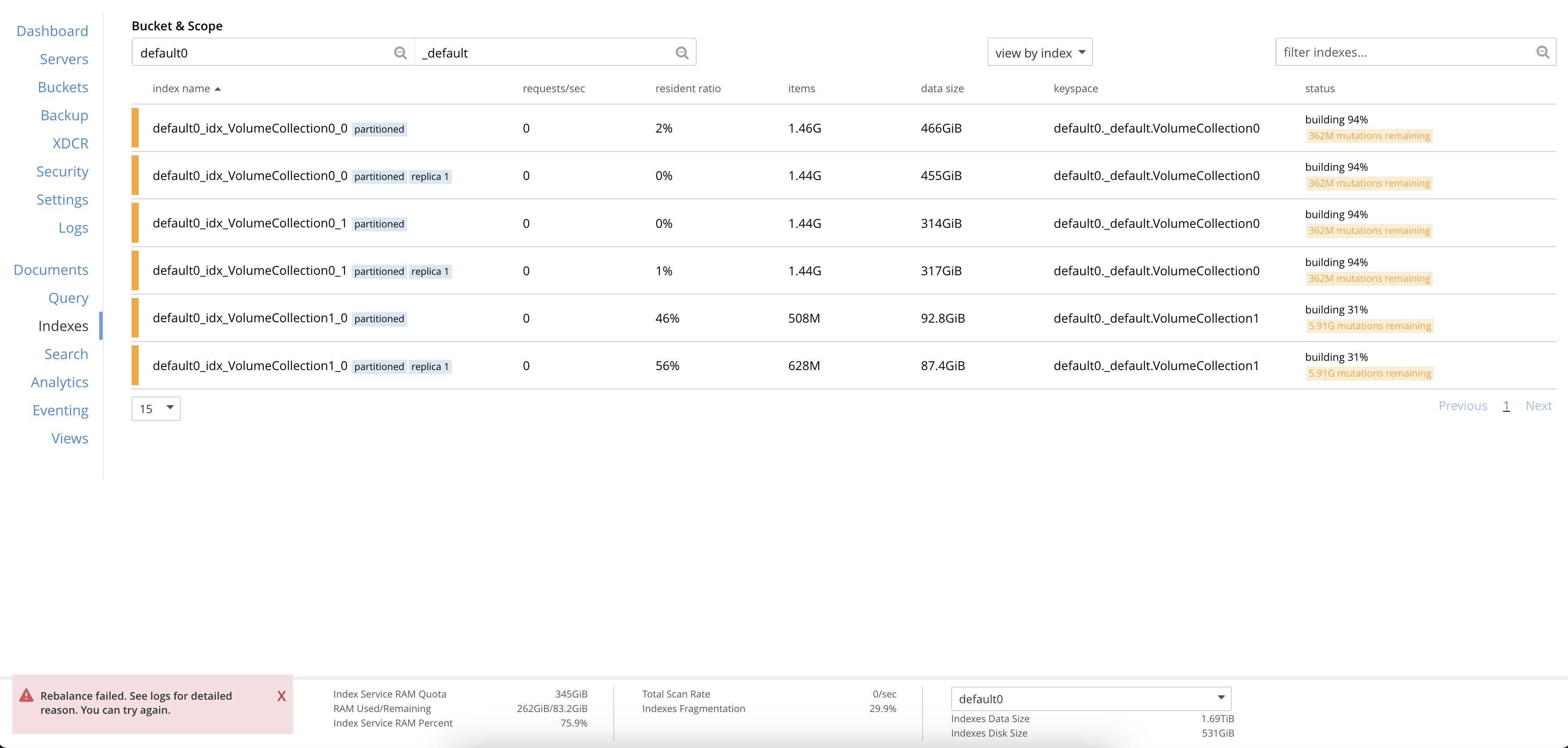
This is much above 10% RR which is a must for GSI to function properly.
Steps:
- Create a bucket. 2 collections. load 1.5B items in 2 collection. When the above load finishes, bucket has 3B items.
- Create GSI indexes. wait for them to build completely.
- Index node 020 failed over during initial index building.
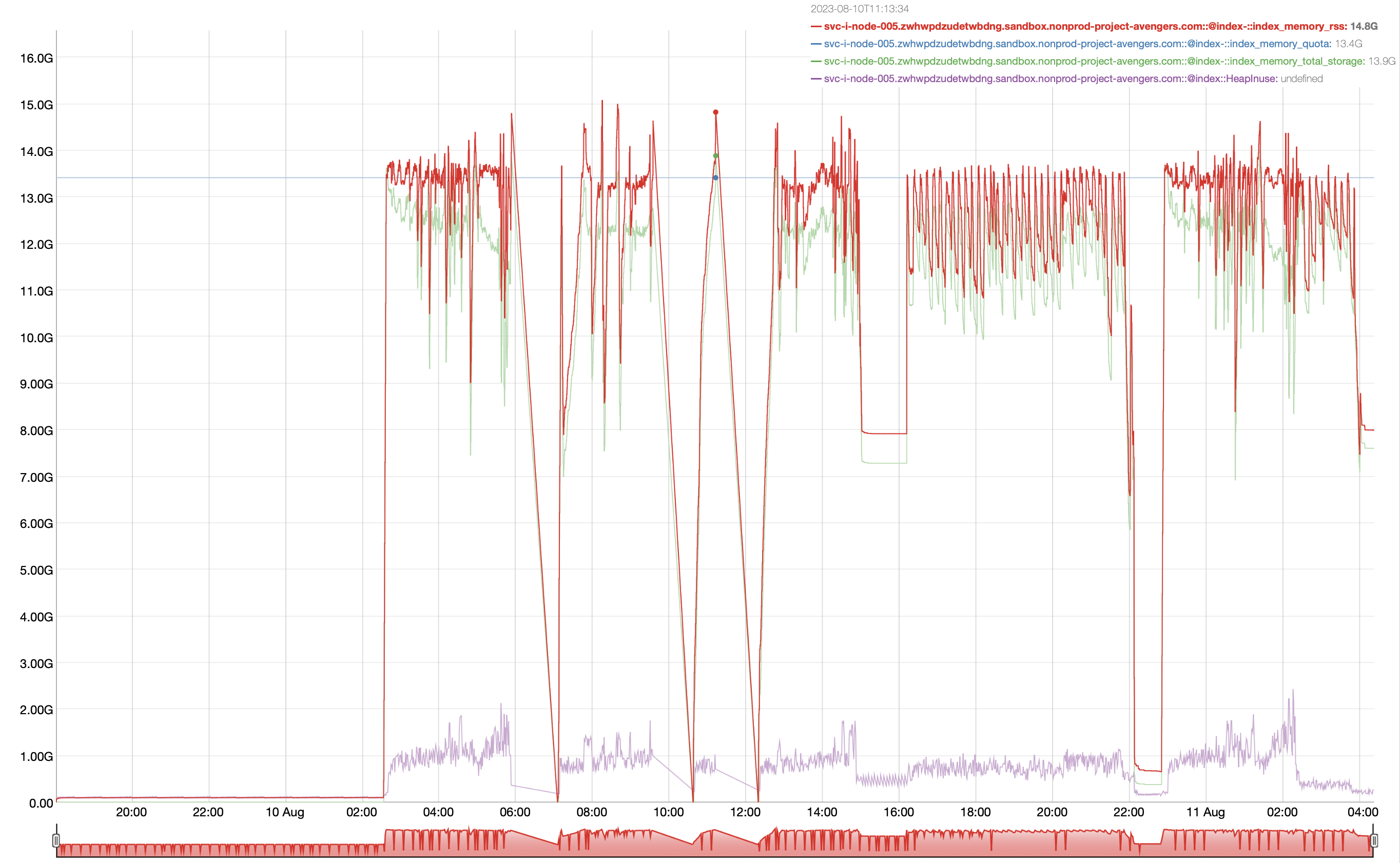
Enough free memory is present while building indexes as shown below:
Please note that this is an old cluster which has seen numerous rebalance/index issues. Ignore all the previous issues you may see in the logs and this defect should focus on the latest index node failover due to:
Node ('ns_1@svc-i-node-020.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com') was automatically failed over. Reason: The index service took too long to respond to the health check
|
Before starting the test KV data is kept as it is and all the indexes has been dropped and started afresh.
CP tried to add back the node which failed initially but then finally get added to the cluster successfully
|
Rebalance Failure |
Rebalance exited with reason {service_rebalance_failed,index,
|
{worker_died,
|
{'EXIT',<0.4625.204>,
|
{rebalance_failed,
|
{service_error,
|
<<"indexer rebalance failure - index build is in progress for indexes: [default0:default0_idx_VolumeCollection0_1 default0:default0_idx_VolumeCollection1_0 default0:default0_idx_VolumeCollection1_0 default0:default0_idx_VolumeCollection0_0 default0:default0_idx_VolumeCollection0_0 default0:default0_idx_VolumeCollection0_1].">>}}}}}.
|
Rebalance Operation Id = 1dbb17a1b72ec482c8fabc5fbbb0513d
|
|
Rebalance Success |
Starting rebalance, KeepNodes = ['ns_1@svc-d-node-015.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-d-node-016.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-d-node-017.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-i-node-018.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-i-node-019.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-i-node-020.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-q-node-013.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com',
|
'ns_1@svc-q-node-014.5cx6lchleaencuaw.sandbox.nonprod-project-avengers.com'], EjectNodes = [], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = 2f9bbab33fc0a4e91a8bd8f3733a9742 hide
|
|
|
Rebalance completed successfully.
|
Rebalance Operation Id = 2f9bbab33fc0a4e91a8bd8f3733a9742
|
Finally the cluster is back to healthy!
|
QE Test |
sudo guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/couchbase_capella_volume_2_new.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.hostedHospital.Murphy.test_rebalance,num_items=1500000000,num_buckets=1,bucket_names=GleamBook,bucket_type=membase,iterations=3,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,maxttl=10,pc=20,gsi_nodes=3,cbas_nodes=3,fts_nodes=3,kv_nodes=3,n1ql_nodes=2,kv_disk=1510,n1ql_disk=50,gsi_disk=2000,fts_disk=1500,cbas_disk=1500,kv_compute=n2-custom-36-73728,gsi_compute=n2-standard-32,n1ql_compute=n2-custom-16-32768,fts_compute=n2-custom-16-32768,cbas_compute=n2-custom-16-32768,mutation_perc=100,key_type=CircularKey,capella_run=true,services=data-index-query,rebl_services=data-index-query,max_rebl_nodes=27,provider=GCP,region=us-central1,type=PD-SSD,size=1500,collections=2,ops_rate=100000,skip_teardown_cleanup=true,wait_timeout=14400,index_timeout=86400,runtype=dedicated,skip_init=true,rebl_ops_rate=10000,nimbus=true,expiry=false,v_scaling=true,h_scaling=false,horizontal_scale=1 -m rest'
|