Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
7.6.0
-
Enterprise Edition 7.6.0 build 1756
-
Untriaged
-
Centos 64-bit
-
0
-
Yes
Description
Script to Repro
./sequoia -client 172.23.104.168:2375 -provider file:centos_second_cluster.yml -test tests/integration/7.6/test_7.6.yml -scope tests/integration/7.6/scope_7.6_magma.yml -scale 1 -repeat 0 -log_level 0 -version 7.6.0-1756 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
We started seeing lot of these errors recently. See 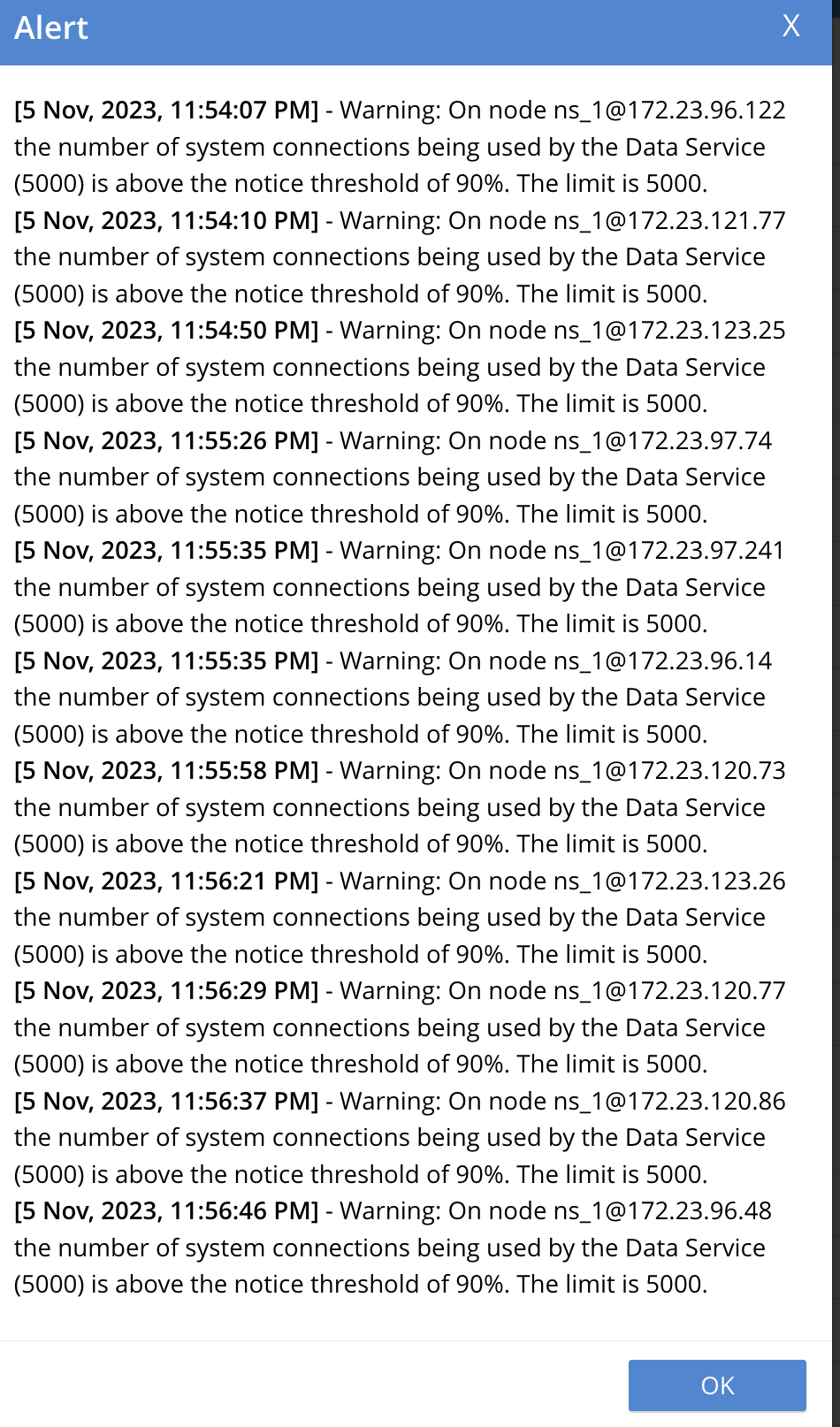 . Considering
. Considering MB-11445 was merged 2 months and back and we started seeing these errors only in past week or so hints at some kind of regression.
Last run where we did not see this is 7.6.0-1694. cbcollect_info attached.
Attachments
Issue Links
- causes
-
-

- Closed
-
- is duplicated by
-
-
- Closed
-
| For Gerrit Dashboard: MB-59468 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 200183,3 | MB-59468: Close socket when connecting to memcached fails | unstable | couchdb | Status: MERGED | +2 | +1 |